
지난 포스트에서 “Transformer-XL”에 대한 리뷰를 진행했었는데요. Language Modeling 테스크에서 장기 의존성 능력을 높이기 위해, Transformer의 제한된 컨텍스트 길이를 recurrence한 구조로 늘려주는 방법이였습니다. 이번 포스트에서는 해당 논문의 후속으로 제안된 “XLNet: Generalized Autoregressive Pretraining for Language Understanding”을 리뷰하려고 합니다. 많은 양의 코퍼스로 Language Modeling에 대한 Pre-training을 진행하고 특정 테스크로 Fine-tuning을 진행하는 방법은 BERT 이후로 NLP 문제를 풀기위한 정석과 같은 방법이 되었습니다. XLNet에서는 BERT와 같이 Masked Language Modeling을 objective로 하는 Autoencoder(AE) 방식과 GPT와 같이 Auto-Regressive(AR) Language Modeling을 objective로 하는 방식의 장점을 유지하면서 단점을 보완하는 새로운 학습 방식을 제안합니다. 또한 Transformer-XL의 recurrence 알고리즘도 함께 적용하여 BERT를 능가하는 성능을 달성합니다. 약 9개월 전에 XLNet 리뷰를 팀블로그에 작성 했는데, 최근에 논문이 업데이트 되어 다시 한 번 공부하면서 글을 작성합니다.
1. Main Idea
Language Modeling은 특별한 레이블링 작업이 필요 없는 비지도 학습 방식이고, 최근에 언어 자체를 이해하기 위한 pre-training 방법으로 자주 이용됩니다. BERT이전의 방법들은 대부분 Auto-Regressive(AR)방식으로 주어진 컨텍스트에 대해 다음 토큰을 맞추는 단방향의 학습을 진행했습니다. BERT에서는 이를 해결하기 위해 특정 토큰을 [MASK] 로 치환하고 이를 예측함으로써(Denoising Autoencoder), 양방향의 정보를 이용할 수 있었습니다. 하지만 1) [MASK]는 pre-training 에만 등장하는 토큰으로 fine-tuning 과 불일치 하고, 2) [MASK] 토큰 사이의 의존관계가 무시되는 문제가 발생합니다. 본 논문에서는 이를 해결하기 위해, 양방향의 정보를 이용할 수 있는 AR Language Modeling 학습법을 제안합니다.
2. AR, AE Language Modeling
Language Model은 특정 토큰들의 시퀀스 \([x_1, x_2, x_3, ... x_T]\)에 확률 \(P(x_1, x_2, x_3, ... x_T)\)을 할당하는 확률 분포 모델입니다. 주로 언어 자체의 분포, 즉 “주어진 시퀀스가 얼마나 자연스러운가”를 학습하고 비지도학습으로 진행할 수 있기 때문에 pre-training에 많이 이용되고 있습니다.
2.1. Auto Regressive(AR)
AR Language modeling은 확률을 할당하기 위해 주어진 텍스트 시퀀스 \(X = [x_1, x_2, x_3, ... x_T]\) 에 대한 확률 분포를 \(p(X) = p(x_t \mid x_{ < t}) = \prod\limits_{t=1}^T p(x_t \mid x_{ < t}\)과 같이 특정 방향(정방향/역방향)의 곱으로 분해합니다. 뉴럴 넷은 이러한 조건부 확률 분포를 학습합니다.
\[input \space sequence : X = (x_1, x_2, ..., x_T)\] \[forward \space likelihood:p(X) = \prod\limits^T_{t=1} p(x_t \mid x_{<t})\] \[training \space objective(forward) : \max_{\theta} \space \log p_{\theta}(x) =\max_{\theta} \space \sum\limits^T_{t=1} \log p(x_t \mid x_{<t})\]즉 ["나는", "블로그", "를", "쓰고", "있다", "."]가 주어졌을 때, \(p(블로그 \mid 나는)p(를 \mid 나는, 블로그) ...\)의 확률 분포를 모델링하도록 학습을 진행합니다. 이 방법은 Language Modeling이라는 목적을 달성하기 위해, 어떠한 가정 없이 \(p(X)\)를 조건부 확률의 곱으로 분해하여 표현할 수 있는 장점이 있습니다. 하지만 특정 방향의 컨텍스트만 인코딩하도록 학습되어 pre-training 방법으로 이용할 시, 양 방향 컨텍스트를 고려하는 테스크들에 효과가 떨어지는 단점이 있습니다. (ELMo, GPT 등의 방법이 해당합니다.)
2.2 Auto Encoding(AE)
Auto Encoding은 주어진 입력을 그대로 예측하는 문제를 푸는데, 주로 차원 축소 등을 목적으로 이용됩니다. 최근에는 Variational Auto Encoder(VAE), Conditional Auto Encoder(CAE), Denoising Auto Encoder(DAE) 등 많은 변형과 서로 다른 목적 으로 이용되고 있습니다. DAE는 노이즈가 섞여 있는 입력을 원래의 입력으로 예측하는 문제를 푸는데, BERT에서 이용했던 시퀀스의 토큰을 일정 확률로 [MASK] 로 치환한 뒤 이를 원래 토큰으로 복원하는 방법도 일종의 DAE로 볼 수 있습니다.
즉 ["나는", \([MASK]_1\), "를", "쓰고", \([MASK]_2\), "."]이 주어 졌을 때, 원래 토큰 분포를 예측하는 \(P([MASK]_1 \mid 나는, 를, 쓰고, [MASK]_2, .)P([MASK]_2 \mid 나는, [MASK]_1, 를, 쓰고, .)\)를 학습합니다. 이 방법은 AR에 비해 양방향 컨텍스트를 고려하여 학습할 수 있다는 장점이 있습니다. 하지만 [MASK]는 기존 언어 분포에 없는 노이즈이고, pre-training시에만 이용되기 때문에 다른 테스크들과 불일치 문제가 발생합니다. 또한 각 [MASK]들 이 독립적으로 예측되어(3번째 식의 빨간색 근사) [MASK] 토큰들 사이의 의존관계를 학습할 수 없습니다.
3. XL-Net
위에서 제시한 두 가지 Language Modeling의 단점을 보완하고 장점을 살릴 수 있는 새로운 objective와 이를 학습할 수 있는 모델 구조를 제시합니다.
3.1. Objective: Permutation Language Modeling
특정한 가정 없이 모델링을 표현할 수 있는 AR모델의 이점과 양방향의 컨텍스트를 이용할 수 있는 AE모델의 이점을 모두 살리면서 나머지 단점/한계점들을 보완하는 Permutation Language Modeling이라는 새로운 objective를 제시합니다.
길이 \(T\)의 시퀀스 \(X=[x_1, x_2, ... x_T]\)가 주어졌을 때, 시퀀스를 나열할 수 있는 모든 순서의 집합(\(Z_T\)) - 순열(Permutation)은 \([1, 2, 3, ..., T], [2, 3, 4, ... T], ... [T, T-1, ... 1]\) 등 총 \(T!\)개 만들 수 있습니다. 이 때 새로운 objective는 다음 식과 같이 이 집합(\(Z_T\))에 속해있는 모든 순서들을 고려하여 AR 방식으로 모델링을 진행하고, 각 순서에 대한 log likelihood 기댓값을 최대화합니다. 기존의 AR모델링은 해당 objective의 순열 중 한 가지 경우-원래의 순서(\([1, 2, 3, ... T]\))만을 고려한다고 볼 수 있습니다.
\[likelihood : \mathbb{E}_{z\backsim Z_T}[\prod\limits_{t=1}^Tp_{\theta}(x_{z_t} \mid x_{z < t})]\] \[training \space objective :\max_{\theta} \space \mathbb{E}_{z\backsim Z_T}[\sum\limits_{t=1}^T \log \space p_{\theta}(x_{z_t} \mid x_{z < t})]\]입력 시퀀스 ["나는", "블로그", "를", "쓰고", "있다", "."] 와 길이가 6인 모든 순서들의 집합 \(Z_6 = {[1,2,3,4,5,6], [2,3,4,5,6,1], ... [6,5,4,3,2,1]}\)이 주어졌을 때, 각 순서들에 대한 AR모델링을 고려할 수 있습니다.
\(z=[1,2,3,4,5,6]\)인 경우 기존 시퀀스의 순서 그대로 진행하여 \(\prod_{t=1}^Tp(x_{z_t} \mid x_{z < t})\)는 \(p(블로그 \mid 나는)p(를 \mid 나는, 블로그)...p(. \mid 나는,블로그,를,쓰고,있다)\) 가 되고 \(z=[2,3,4,5,6,1]\)인 경우 ["블로그", "를", "쓰고", "있다", ".", "나는"]의 순서로 진행하여 \(p(를 \mid 블로그)p( 쓰고 \mid 를, 블로그)...p(나는 \mid 블로그,를,쓰고,있다,.)\)이 됩니다.
이 때 주의해야 할 점은 시퀀스 자체의 순서를 섞는것이 아니라 \(p(x)\)를 조건부 확률들의 곱으로 분리 할때 이 순서만 섞는다는 점입니다. 즉 모델은 기존 시퀀스의 토큰들의 절대적 위치를 알 수 있습니다. 위 예시에서 \(p(나는 \mid 블로그,를,쓰고,있다,.)\)는 2번째 위치에 "블로그"라는 토큰, 3번째 위치에 "를"이라는 토큰, 4번째 위치에 "쓰고" 라는 토큰… 이 주어졌을 때, 첫번째 위치에 "나는"이라는 토큰이 올 확률을 나타냅니다.
시퀀스 길이 \(T\)에 대해 가능한 순열의 갯수는 \(T!\)개를 갖기 때문에, 하나의 텍스트\([x_1, x_2, ... x_T]\)에 대해 순열(\(Z_T\))의 모든 경우를 고려하는 것은 불가능합니다. 따라서 하나의 텍스트 시퀀스에 대해 하나의 permutation 순서\((z)\)를 샘플링 하고 해당 순서에 대해 \(p_{\theta}(x)\)를 \(\prod_{t=1}^Tp_{\theta}(x_{z_t} \mid x_{z < t})\)로 분해합니다. 하지만 모델의 파라메터(\(\theta\))는 학습하는 동안 모든 순서에 대해 공유되므로, 많은 양의 데이터를 거치면 모든 순서를 고려한다고 볼 수 있습니다. 따라서 모델은 자연스럽게 \(x_i \neq x_t\) 인 모든 토큰을 보게 되고, 이 과정에서 어떠한 근사 없이 양방향 컨텍스트를 볼 수 있는 능력을 갖게 됩니다.
3.2. Architectur: Two-Stream Self-Attention for Target-Aware Representation
Target-Aware Representation
위에서 새롭게 제시한 objective를 바로 기존의 Transformer 구조에 적용하면 다음과 같은 문제가 발생합니다.
일반적으로 파라메터(\(\theta\))를 갖는 모델로 다음 토큰분포 \(p_{\theta}(X_{z_t} \mid x_{z < t})\)를 예측하기 위해, 모델의 최종 hidden state(\(h_{\theta}(x_{z < t}\))와 Softmax함수를 이용합니다.
\[p_{\theta}(X_{z_t} = x \mid x_{z < x}) = \frac{exp(e(x)^{\top} h_{\theta}(x_{z < t}))}{\sum_{x'}exp(e(x')^{\top} h_{\theta}(x_{z < t}))}\]이 때, Transformer의 \(h_{\theta}(x_{z < t}\)는 예측될 다음 토큰의 위치에 관계 없이 일정한 값을 가집니다. 기존의 AR 모델링에서는 컨텍스트(\(< t\))가 고정되면 예측할 토큰의 위치가 다음 시점(\(t\))으로 고정되어 문제가 발생하지 않습니다. 하지만 제시한 Objective에서는 permutation된 순서를 고려하기 때문에 주어진 컨텍스트(\(z_{< t}\))가 고정되더라도 예측할 토큰의 위치(\(z_t\))가 고정되지 않기 때문에, 예측 위치에 대한 정보가 추가적으로 필요합니다.
["나는", "블로그", "를", "쓰고", "있다", "."]의 순서 permutation의 두 경우(\([\color{blue}{3,2,1,}\color{red}{4,}\color{black}{6, 5}]\), \([\color{blue}{3,2,1,} \color{red}{5,}\color{black}{6, 4}]\))에서 4번째 시점(붉은색) 토큰의 확률 분포를 예측하는 문제를 보면, 예측할 토큰에 대한 위치 정보를 받지 않기 때문에 \(h_{\theta}(를, 블로그, 나는)\)는 항상 같은 값을 갖게 됩니다. 따라서 같은 hidden state로 첫 번째 순서일 때는 “쓰고”를, 두 번째 순서일 때는 “있다”를 예측하도록 학습되어 예측할 토큰이 명확하지 않은 문제가 발생합니다.
이를 해결하기 위해 모델의 입력으로 예측할 토큰의 위치정보(\(\color{red}{z_t}\))를 추가적으로 제공하여 다음과 같이 예측할 토큰에 대한 확률 분포를 계산합니다.
\[p_{\theta}(X_{z_t} = x \mid x_{z < x}) = \frac{exp(e(x)^{\top}g_{\theta}(x_{z < t}, \color{red}{z_t} \color{black}{))}}{\sum_{x'}exp(e(x')^{\top} g_{\theta}(x_{z < t}, \color{red}{z_t}\color{black}{))}}\]Two-Stream Self-Attention
위의 방법으로 예측할 토큰에 대한 모호성은 해결했습니다. 이제, 기존의 \(h_{\theta}(x_{z < t})\)를 계산하던 모델을 \(g_{\theta}(x_{z < t}, \color{red}{z_t} \color{black}{)}\)을 계산하도록 변경하는 문제가 남아있습니다. 이를 위해 현재 예측하고자 하는 시점 \(z_t\)는 주변 컨텍스트(\(x_{z < t}\))와 attention을 통해 정보를 축적해 나가는 방식을 제시합니다. 두 가지 제약 조건을 통해 이 방법을 실현하는데, 기존의 Transformer구조를 이용하면 이들 사이에 모순이 생깁니다.
- 토큰 \(x_{z_t}\)를 예측하기 위해 \(g_{\theta}(x_{z < t}, z_t)\)는 위치에 대한 정보 \(z_t\)만 이용하고 컨텐츠(단어 자체에 대한 정보) \(x_t\)를 이용하면 안됩니다. 단어 자체에 대한 정보를 제공하면, 정답 단어를 제공하는 꼴이 되기 때문에, 의미 없는 쉬운 문제가 됩니다.
- 다음 토큰들(\(x_{z > t}\))을 예측할 때에는 \(g_{\theta}(x_{z < t}, z_t)\) 는 컨텐츠에 대한 정보 \(x_{z_t}\)를 인코딩하고 있어야 합니다. 다음 시점들에서는 현재 시점의 단어에 대한 정보를 이용할 수 있어야 합니다.
위의 두 조건은 특정 시점에서 하나의 hidden state을 인코딩하는 기존의 Transformer구조 에서는 서로 모순입니다. 따라서 두 가지 hidden state들을 이용하는 새로운 방법을 제시합니다.
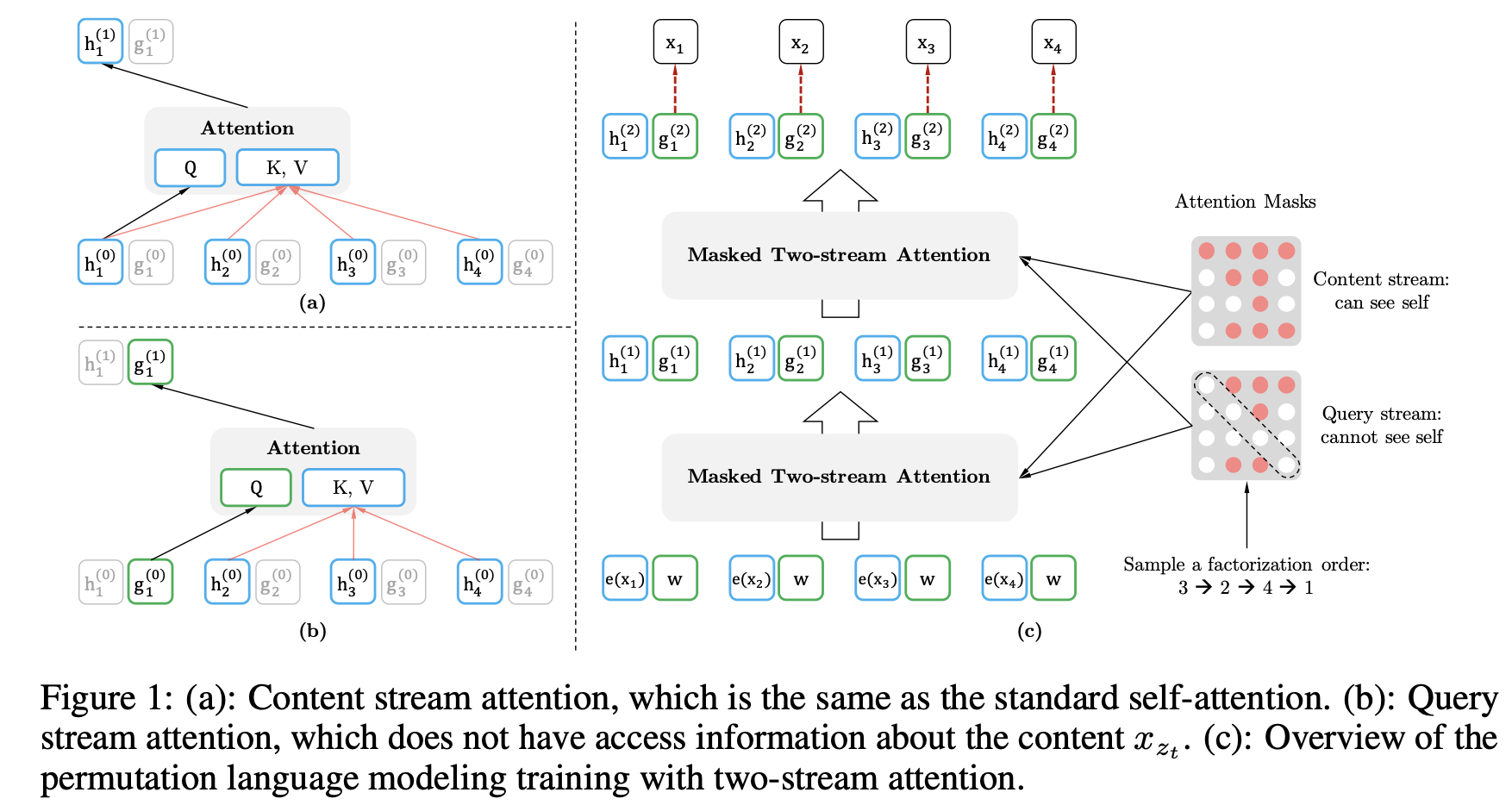
- Content representation (\(h_{\theta}(x_{z \leq t}\)): \(z \leq t\) 시점의 정보(\(x\))를 이용하여 컨텍스트와 \(x_{z_t}\)에 대한 정보를 함께 인코딩합니다. (기존 Transformer의 hidden state들과 비슷한 역할을 합니다.) 이를 통해 2번 제약 조건을 만족시킵니다.
- 초기 입력으로 단어 임베딩(컨텐츠)를 받습니다. \(h_i^{(0)} = e(x_i)\)
- Query representation (\(g_{\theta}(x_{z < t}, z_t)\)): \(z < t\) 시점의 정보(\(x\))와 \(z_t\)시점의 위치만을 이용하여 컨텍스트에 대한 정보를 인코딩합니다. 이를 통해 1번 제약 조건을 만족시킵니다.
- 초기 입력으로 임의의 학습가능한 벡터를 받습니다. \(g_i^{(0)} = w\)
- 예측 해야하는 토큰의 위치 정보를 갖고 있기 때문에, 최종 state(\(g_{z_t}^{(M)}\))는 다음 토큰을 예측하기 위해 이용됩니다.
두 스트림은 파라메터(\(\theta\))를 공유하며 학습을 진행합니다. fine-tuning을 진행할 때에는 Query 스트림을 제거하고 Content 스트림을 Transformer와 동일하게 이용합니다.
Partial Prediction
제시한 objective는 기존의 단점을 보완하기 때문에 몇 가지 이점을 갖고 있지만, permutation으로 인해 배워야 하는 정보량 자체가 많아져 optimizing하기 까다롭고, 수렴이 느립니다. 이를 보완하기 위해, 주어진 시퀀스의 순서(\(z\)) 대해 특정 지점 \(c\)를 기준으로 뒤의 몇 토큰(\(z_{> c}\))만 타겟으로 예측하도록 수정합니다. 즉 다음과 같이 \(p_{\theta}(x_{z > c} \mid x_{z \leq c})\)를 최대화 합니다.
\[\max_{\theta} \space \mathbb{E}_{z\backsim Z_T}[\log \space p_{\theta}(x_{z > c} \mid x_{z \leq c})] = \mathbb{E}_{z\backsim Z_T}[\sum\limits_{t=c+1}^{\mid z \mid} \log \space p_{\theta}(x_{z > c} \mid x_{z \leq c})]\]서로 다른 시퀀스 길이의 입력에 대해 타겟의 시점(\(c\))를 정하기 위해 \(K\)라는 하이퍼파라메터를 도입합니다. 각 시퀀스 별로 \(\lvert z \rvert / (\lvert z \rvert - c) \approx K\) 를 만족하는 \(c\) 를 이용하는데, 이 식을 이용하면 약 \(1/K\) 개의 토큰이 타겟으로 설정됩니다. 또한 학습의 효율성을 위해 \(z_{< c}\) 에 대해서는 Query representation을 계산하지 않습니다.
3.3. Incorporating Ideas from Transformer-XL
Trnasformer-XL은 AR Language Modeling에서 SoTA성능을 보이고 있고, Permutation Language Modeling 또한 넓은 범위의 AR 모델링이기 때문에 해당 방법을 적용할 수 있습니다. Transformer-XL의 핵심 아이디어 두 가지 1)recurrent 매커니즘, 2)relative positional encoding 을 XLNet에 적용합니다. Transformer-XL에 대한 자세한 내용은 논문 혹은 지난 포스트에서 확인할 수 있습니다.
- recurrent 매커니즘: Trnasformer-XL에서는 두 개의 시그먼트 \(\tilde{x} = s_{1 : T}, x=s_{T+1:2T}\) 로 구성된 긴 시퀀스를 입력으로 받아서 첫 번째 시그먼트\((\tilde{x})\)의 각 레이어(\(m\)) 별 hidden state들, \(h^{(m)}(\tilde{x})\) 를 메모리로 저장(캐싱)해두고, 두 번째 시그먼트\((x)\) 계산시 이를 이용하여 하나의 시그먼트 길이보다 긴 의존성을 학습합니다. XL-Net에 이를 적용하기 위해 첫 번째 시그먼트의 순서 \(\tilde{z}\)와 두 번째 시그먼트의 순서 \(z\)를 정합니다. \(\tilde{z}\)의 순서로 첫 번째 시그먼트의 hidden state, \((h_{\tilde{z}}^{(m)})\)를 메모리로 저장(캐싱)하고, 이를 이용해서 두 번째 시그먼트\(h_{z}^{(m + 1)}\)을 계산합니다.
- relative positional encoding: Transformer-XL에서 메모리와 현제 시그먼트 사이의 positional encoding을 구분하기 위해, Q와 K사이의 상대적인 위치 차이를 인코딩하는 기법을 이용했습니다. XL-Net에서도 이와 동일한 기법을 이용합니다.
3.4. Modeling Multiple Segments
QA(Question/Paragraph), STS(Text1/Text2)등 많은 downstream 테스크들에서 입력으로 2개 이상의 시그먼트를 이용합니다. 그래서 BERT에서는 pre-training 부터 두 개의 시그먼트로 구성된 입력 형식([CLS], Segment_A, [SEP], Segment_B, [SEP])을 이용하고 두 시그먼트를 구분하기 위해 [SEP]이라는 특수 토큰과 각 시그먼트 별로 다른 임베딩(시그먼트 임베딩)을 부여합니다. 또한 두 시그먼트A가 시그먼트B와 연속 되는 것인지/ 시그먼트B가 다른 문단에서 샘플링된 것인지를 예측하는 Next Sentence Prediction(NSP)문제를 통해 두 시그먼트 사이의 관계를 학습합니다.
XL-Net에서도 이와 동일한 입력을 이용하고 50%의 확률로 다른 문단으로부터 시그먼트B를 샘플링하는데, 다음과 같이 몇 가지 차이점이 있습니다.
- 위에서 설명했던 메모리는 시그먼트A, 시그먼트B가 연속일 때에만 이용합니다. (연속 되지 않으면 서로 다른 문단으로 부터 추출되었기 때문에 서로 의존관계를 학습할 필요가 없습니다.)
- BERT와 유사하게 서로 다른 시그먼트를 구분할 수 있도록 시그먼트 인코딩을 추가합니다. 각 어텐션 헤드별로 같은 시그먼트에 속하는 토큰 \(i,j\)사이의 시그먼트 인코딩 \(s_{ij}=s_{+}\)과 아닌 경우 \(s_{ij}=s_{-}\)를 학습가능한 파라메터로 둬서 어텐션 계산시 반영합니다. \(i\) 번째 쿼리 토큰과 \(j\) 번째 키 토큰 사이의 어텐션을 계산할 때, \(a_{ij}=(q_i + b)^{\top}s_{ij}\)를 원래의 어텐션 값에 더해줍니다. (최종 softmax 이전에 더해줍니다.) \(q_i\)는 쿼리 벡터, \(b\)는 헤드 별 학습가능한 바이어스를 \(s_ij\)는 시그먼트 인코딩 입니다. 또한 이 인코딩은 상대적인 것(같은 시그먼트인지/아닌지)이기 때문에 입력이 두 개보다 많은 경우에도 이용할 수 있습니다.
4. Experiments
4.1 Pretraining and Implementation
데이터: BERT에서 이용했던 BooksCorpus, Wikipedia에 추가적으로 Giga5, ClueWeb 2020-B, Common Crawl까지 총 5개의 데이터셋을 이용해서 pre-training을 진행했습니다. 이는 SentencePiece를 이용하여 토크나이징 후 총 32.89B 토큰 정도의 양입니다.
하이퍼 파라메터:
- 모델 크기:
BERT-Base/BERT-Large와 각각 같은 크기를 갖는XLNet-Base/XLNet-Large- BERT와 비교하기 위해 모델 크기 뿐만 아니라 모든 학습 하이퍼 파라메터를 같게 설정한
XLNet-wikibooks모델도 학습했습니다.
- BERT와 비교하기 위해 모델 크기 뿐만 아니라 모든 학습 하이퍼 파라메터를 같게 설정한
- 시퀀스 길이: 항상 패딩 없이 512길이의 입력을 이용했습니다.(RoBERTa와 같은 설정)
- 배치 사이즈: 8192를 이용했습니다.
- Optimizer/Scheduler: Adam weight decay/ linear learning rate decay 이용했습니다.
- 장치/소요시간: 512 TPU v3로 약 5.5일 소요되었습니다.
양방향 데이터 파이프라인(Bidirectional Data Pipeline): recurrence memory를 이용할 때, 양방향으로 모두 장기 의존성을 학습할 수 있도록 배치를 정방향/역방향의 시퀀스가 반반으로 구성되도록 진행했습니다. 정방향의 경우 현재 시점 이전 시퀀스들이 메모리로 제공되고, 역방향의 경우 현재 시점 이후 시퀀스들이 메모리로 제공되어 양방향의 장기의존성을 학습할 수 있습니다.
Span기반의 예측: Language Model의 특정 시점에서 주어진 컨텍스트에 대해 하나의 토큰만 예측하는 것이 아니라 여러 토큰들의 span을 예측합니다. 길이 \(L \in [1, ... ,5]\)을 랜덤으로 선택하고, 연속적인 길이 \(L\)의 span을 선택한 다음 \(KL\)개의 토큰들을 타겟으로 학습합니다.
4.2. Fair Comparison with BERT
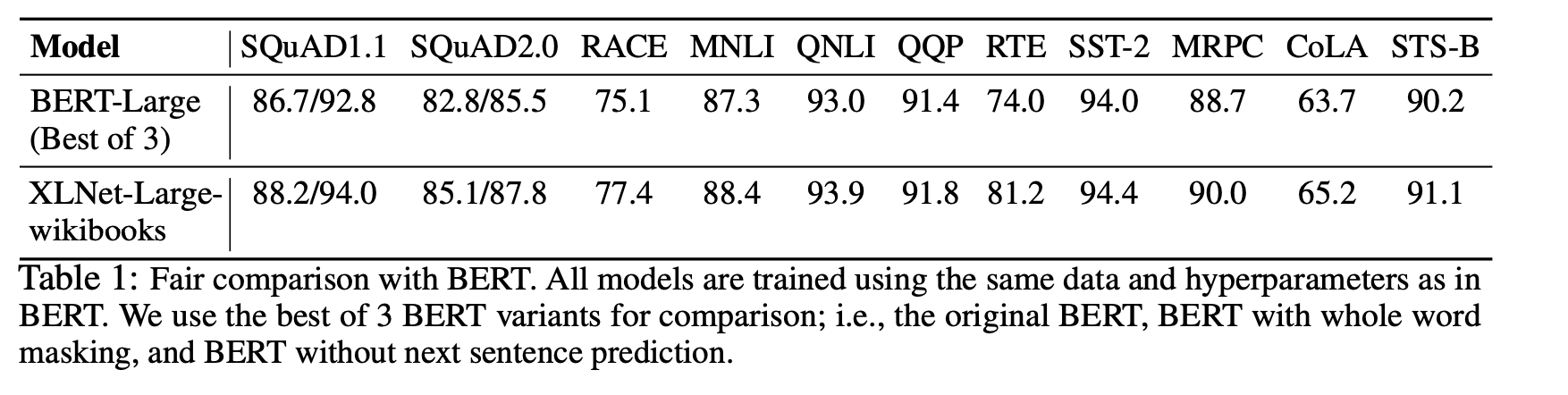
동일한 데이터를 사용한 공정한 pre-training환경에서 BERT와 XLNet을 비교합니다. 위의 표와 같이 SQuAD와 RACE-Reading Comprehension, MNLI, QNLI, RTE, MRPC-NLI 테스크 등 모든 테스크들에서 의미있는 격차로 XLNet이 우세한 모습을 보여줍니다.
4.3 Comparison with RoBERTa
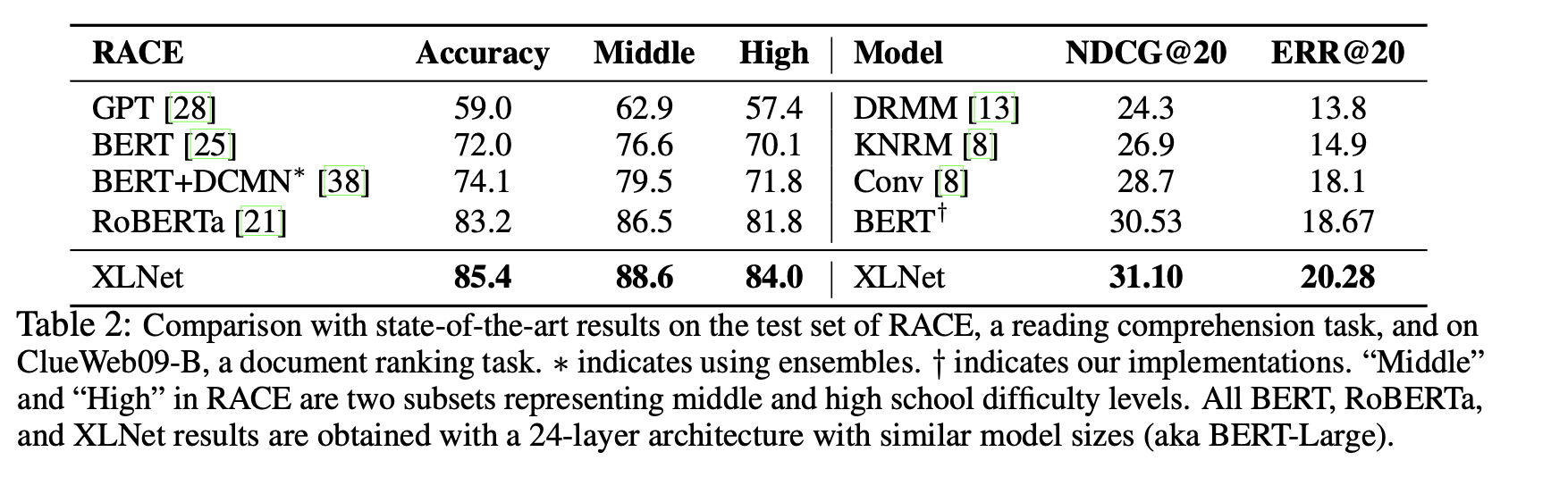
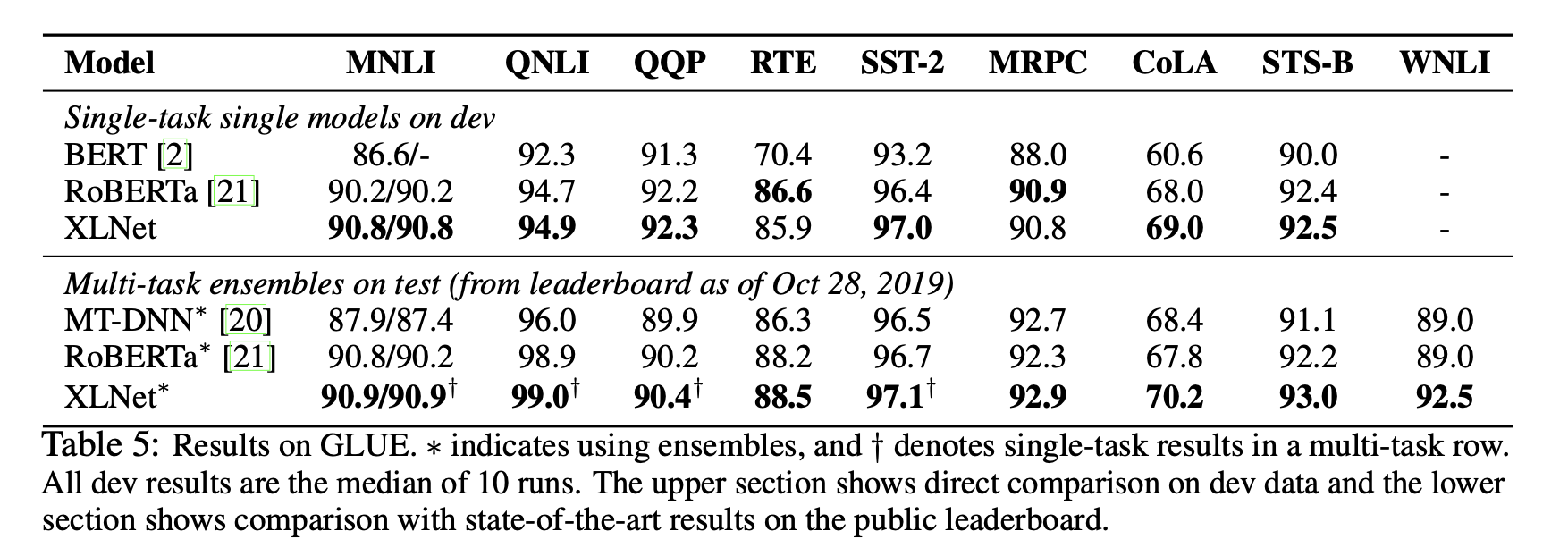
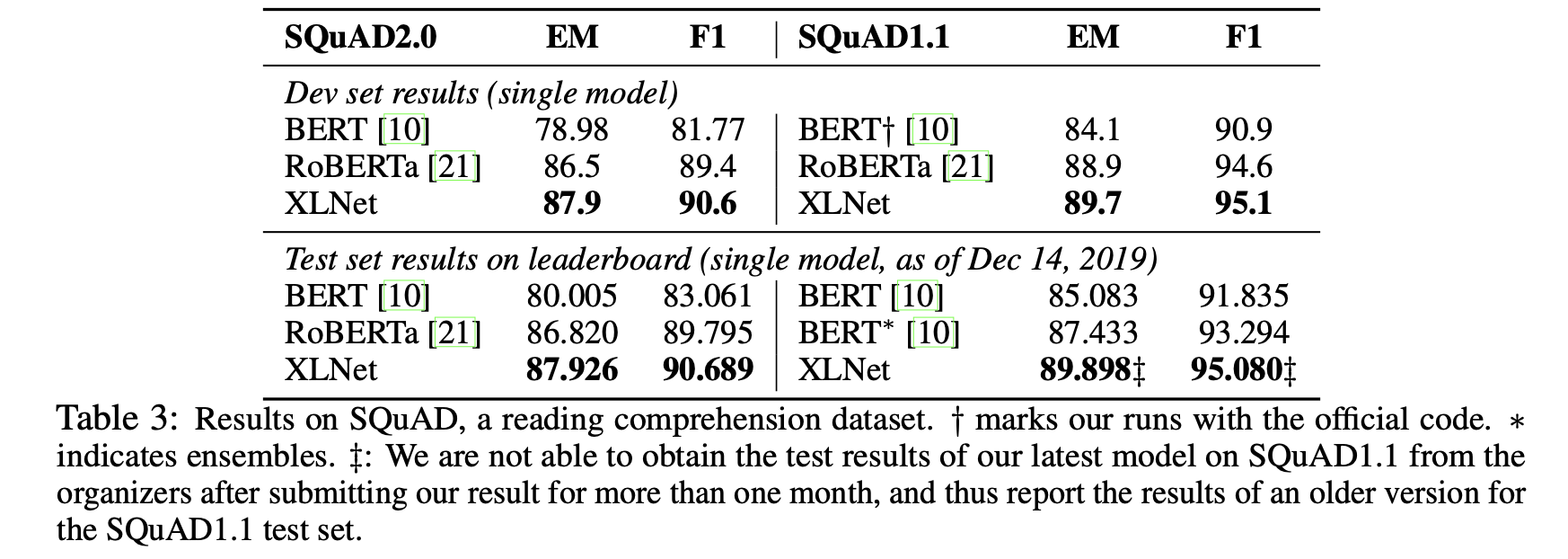
팀 블로그의 글을 쓸 당시에는 BERT와 의미있는 격차를 가진 모델들이 많지 않았는데, 그 이후로 RoBERTa, ALBERT 등 다양한 모델/방법들이 등장했습니다. 현 시점의 논문은 XLNet과 최신 SoTA 방법들과도 비교를 하고 있는데, ALBERT의 경우 파라메터 공유를 통해 hidden size를 키워 FLOPs 양 자체가 공정한 비교가 되지 않기 때문에 비교에서 제외했다고 합니다.
RoBERTa에서는 BERT에서 사용한 학습환경(데이터, NSP, 배치 사이즈 + learning rate 등)을 변경하여 BERT를 능가하는 성능을 보여주였습니다. XLNet또한 이와 비등한 양의 데이터와 동일한 하이퍼 파라메터 설정을 이용해 모델을 학습하고 성능을 비교했습니다. NLU(GLUE), MRC(SQuAD, RACE) 등 다양한 자연어 처리 데이터 셋들에서 RoBERTa 및 SoTA 모델들을 능가하는 성능을 달성했습니다. 특히 다른 테스크에 비해 더 긴 컨텍스트를 이용한 추론 과정을 거쳐야하는 SQuAD나 RACE와 같은 MRC(QA)테스크에서 눈에 띄는 성능 향상을 보여주는데, 이는 Transformer-XL을 백본구조로 이용하여 더 긴 의존성을 학습했기 때문입니다.
RoBERTa에 관한 내용은 리뷰 글 혹은 논문을 통해 확인할 수 있습니다.
4.4. Ablation Study
총 3가지 요인에 대해 Ablation Study를 진행합니다.
- Permuataion Language Modeling objective 자체의 효과 (BERT의 DAE objective와 비교했을 때)
- Transformer-XL을 백본구조의 효과
- Span-based prediction, 양방향 데이터 파이프라인, Next Sentence Prediction(NSP) 등 세세한 구현적인 디테일의 필요성
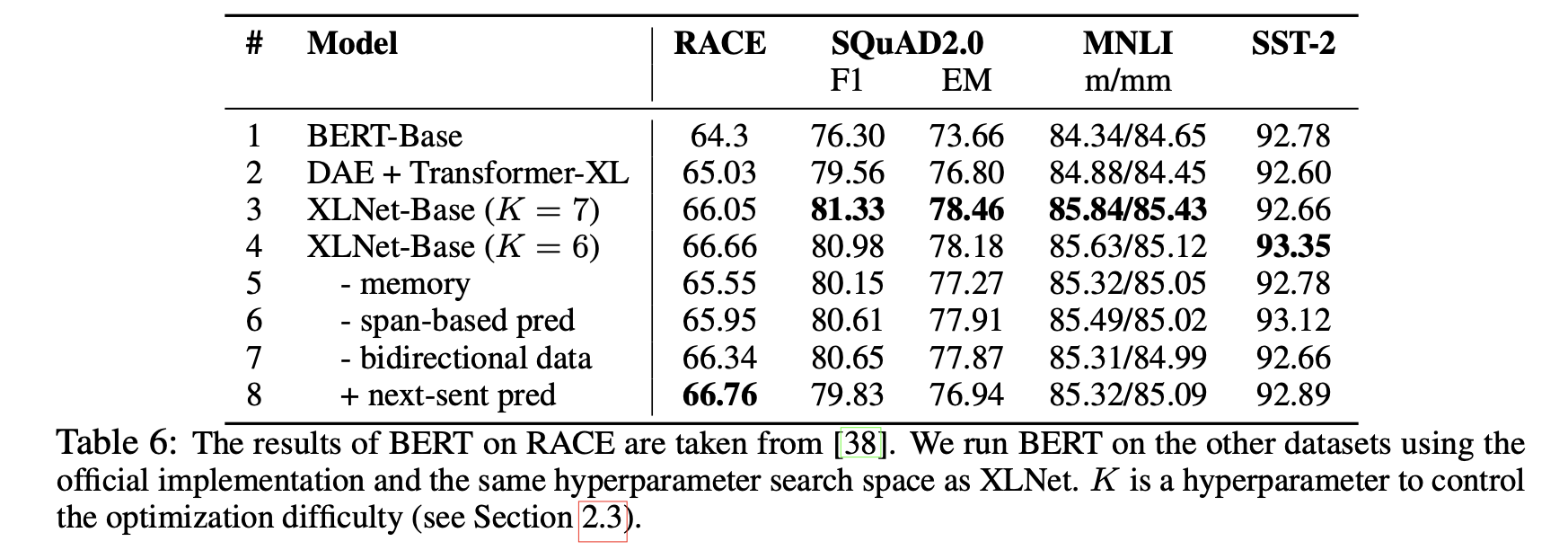
위의 표와 같이 8개의 모델의 성능을 비교했습니다. BERT-Base는 기존 BERT모델, DAE+Transformer-XL(2행)은 Transformer-XL 백본을 BERT의 objective(DAE)로 학습한 모델, 3-8행은 6개의 XLNet-Base 변형들 입니다. 모든 모델들은 12-layer의 모델 구조와 BERT_Base의 학습 하이퍼 파라메터를 이용하여 학습되었습니다.
1-4행을 보면 성능에 Transformer-XL 구조(1행 vs 2행)와 permutation LM(1행 vs 3,4행)의 기여가 크다는 것을 볼 수 있습니다. 또한 메모리를 제거한 경우, RACE와 같이 긴 컨텍스트 분석 능력을 요구하는 데이터셋에서 더 큰 성능 하락이 있었습니다. 6,7행의 Span 기반의 예측과 양방향 데이터 파이프라인 또한 성능 향상에 기여하는 것을 볼 수 있습니다. 그러나 XLNet의 환경에서 Next Sentence Prediction 문제의 추가는 성능 향상에 의미있는 기여를 하지 못했고, 최종 모델에서 이용하지 않았습니다.
5. Reference
-
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. ACL, 2019.
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019.
-
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
-
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Car- bonell, Ruslan Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. NeurIPS 2019.