
이번 글에서는 “RoBERTa: A Robustly Optimized BERT Pretraining Approach”를(GLUE 벤치마크 88.5/4등)리뷰하려고 합니다. Self-Supervised 기반의 학습 방식은 Pre-training에서 많은 시간/리소스가 소요되기 때문에 BERT 및 이후 접근법들을 엄밀하게 비교하기 힘들고, 어떤 Hyper Parameter가 결과에 많은 영향을 미쳤는지 검증하기 힘듭니다. 본 논문에서는 여러 실험을 통해 데이터의 양 및 Key-Hyperparameter의 영향을 분석합니다.
Main Idea
BERT는 아직 Undertrain되어 있고, Pre-training 과정에서 다음과 같은 Hyper-parameter의 튜닝으로 더 좋은 결과를 얻을 수 있었습니다.
- 학습 데이터: BERT에 비해 더 많은 데이터로 더 오래, 더 큰 배치로 학습을 진행합니다.
- Pre-training Objective: Next Sentence Prediction(NSP)테스크를 제거합니다.
- Sequence Length: BERT는 짧은 입력 문장들을 이용하는 downstream 테스크를 대비하여 pre-training 시, 0.1의 확률로 최대 길이보다 더 짧은 길이의 데이터를 이용합니다. 이러한 로직을 제거하고 최대 길이의 데이터로만 학습을 진행합니다.
- Masking strategy: Masking을 진행할 때, BERT의 static masking이 아닌 입력을 만들 때 마다 Masking을 다시 하는 “Dynamic masking”전략을 이용했습니다.
Background(BERT)
본 논문의 대부분 접근법들은 “BERT(Devlin et al., 2019)”와 비교되기 때문에 이에 대한 간단한 오버뷰를 진행합니다.
BERT는 아래 그림과 같이 self-supervised learning 학습법을 이용합니다. 따라서 1) 많은 양의 unlabeld corpus를 이용하여 언어 자체에 대해 배워나가는 pre-train단계와 2) 특정 도메인의 테스크(down-stream 테스크)를 학습하는 fine-tuning단계로 구성되며, 이 두 개의 단계를 차례로 거쳐 학습됩니다.
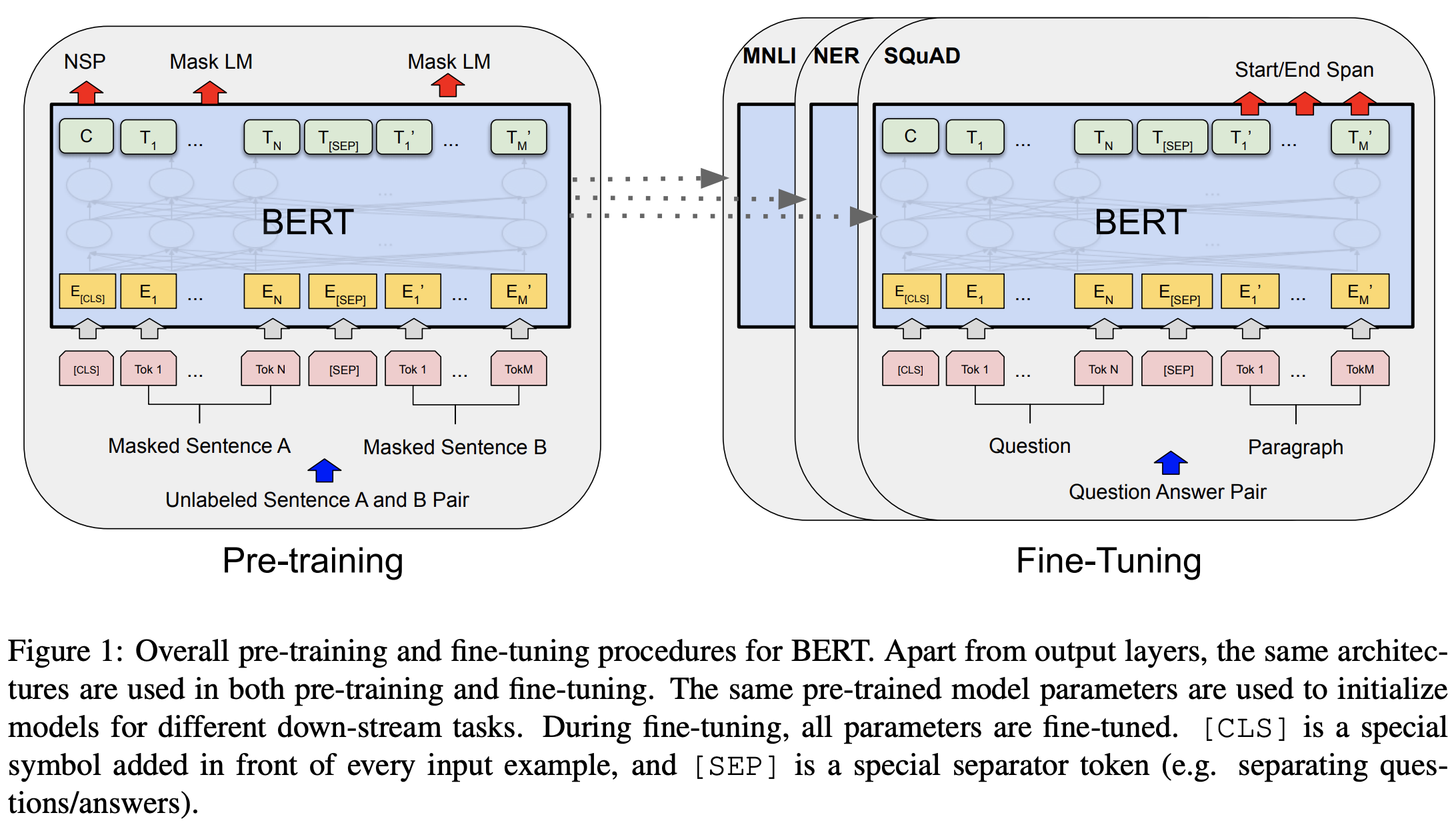
많은 NLP 테스크들에서 대량의 코퍼스에서 unsupervised objective(Skip-Gram, CBOW)를 통해 학습된 word embedding으로 모델 파라메터를 초기화하는 방법은 향상된 결과를 보여줬습니다. BERT는 이와 유사하게, 많은 양의 데이터와 이를 이용할 수 있는 unsupervised objective(MLM, NSP)를 통해 학습된 모델로 fine-tuning 모델을 초기화 함으로써 더 좋은 결과를 얻었습니다.
1. Input Data
BERT는 두 개의 segment(여러 토큰의 sequence, 여러 문장도 가능)와 special token으로 구성된 입력을 이용합니다. special token은 classification task의 representation으로 이용하기 위한 [CLS] 토큰과 두 segment를 분리하기 위한 [SEP] 토큰으로 구성됩니다. 최종 입력은 [CLS] + segment1 + [SEP] + segment2 + [SEP] 의 형태를 가집니다.
pre-training 데이터는 영어 위키피디아와 Book Corpus를 이용하였고, 이는 약 16GB 정도의 크기를 가집니다.
2. Architecture
“Attention is All you need”에서 소개된 transformer 구조의 encoder를 이용합니다. transformer는 L개의 transformer block으로 구성되고, block에서는 Multi-head attention,FFN 연산을 진행합니다. 각 block은 A개의 multi-head와 hidden dimension H에 의해 결정됩니다.
3. Training Objective
Pre-training은 두 개의 objective(Masked Language Modeling, Next sentence prediction)를 optimize 하도록 진행됩니다.
3.1. Masked Language Modeling(MLM)
입력 문장에서 특정 확률(15%)에 따라 랜덤으로 몇 개의 토큰이 선택됩니다. 선택된 15%의 토큰들 중 80%는 [MASK]로, 10%는 랜덤한 다른 토큰으로, 나머지 10%는 그대로 유지됩니다. MLM 은 이 선택된 토큰들을 원래의 토큰으로 예측하는 문제를 풉니다.
MLM을 위한 데이터는 같은 문장이라도 서로 다른 여러 Masking 순서를 가질 수 있습니다. BERT 구현체에서는 pre-training데이터를 미리 만들고 해당 데이터를 이용하여 학습을 진행합니다. 따라서 학습 시작 시 데이터는 고정(static)됩니다. 이를 조금이라도 해결하기 위해 원래의 코드에서는 데이터를 만들 때 동일한 입력 문장에대해서 서로 다른 mask를 생성할 수 있는 duplication_factor라는 인자를 추가했습니다. 이 인자의 default값은 10인데 BERT가 40epoch을 학습했기 때문에 결과적으로 모델은 같은 데이터를 4번 보게 됩니다.
3.2. Next Sentence Prediction
입력 데이터에서 두 개의 segment 의 연결이 자연스러운지(원래의 코퍼스에 존재하는 페어인지)를 예측하는 문제를 풉니다. positive sample 은 코퍼스에서 연속적인 segment를 선택함으로써 얻을 수 있고, negative sample 은 서로 다른 문서의 segment들을 연결함으로써 얻을 수 있습니다. 이 테스크는 pair단위의 downstream task들(NLI, text similarity)을 고려하여 디자인 되었습니다.
4. Optimization
BERT는 Adam Optimizer(\(\beta_1 = 0.9\), \(\beta_2 = 0.999\), \(\epsilon=1e-6\), L2 weight decay = 0.01)를 이용하였습니다. Learning rate는 1e-4를 이용하였으며, 첫 10000step에서 linear-warmup하여 최대 치(1e-4)를 찍고 다시 linear하게 감소하는 스케쥴링 방법을 이용했습니다. GELU activation과 모든 layer에서 0.1 확률의 dropout을 이용했습니다. pre-training 단계에서 batch size 256으로 약 1,000,000 스탭을 학습했습니다.
Experiments
저자들은 여러 Hyper-parameter들에 대한 실험을 진행하고 최적의 세팅으로 “RoBERTa”를 학습했습니다. 이 파트에서는 저자들이 진행했던 실험들을 하나씩 살펴보겠습니다.
1. Reimplementation
실험을 위해 BERT의 학습 코드를 재구현 했는데 대부분의 설정은 동일하고, 차이점은 다음과 같습니다.
- Peak Learning rate/ warm up step: Batch Size에 따라 각각 튜닝합니다. (BERT에서는 1e-4/256 이용)
- Adam Optimizer: Large batch size에서 조금 더 안정적이도록 \(\beta_2=0.98\)로 설정하였습니다.
- Sequence Length: 위에서 언급했듯이 짧은 문장은 사용하지 않습니다. 또한 BERT의 저자들은 pre-training의 처음 90%는 짧은 길이(128, 256)로 학습하고 남은 10%에서 full length(512)를 이용하도록 권장했지만, 처음부터 512(full length)로 학습을 진행했습니다.
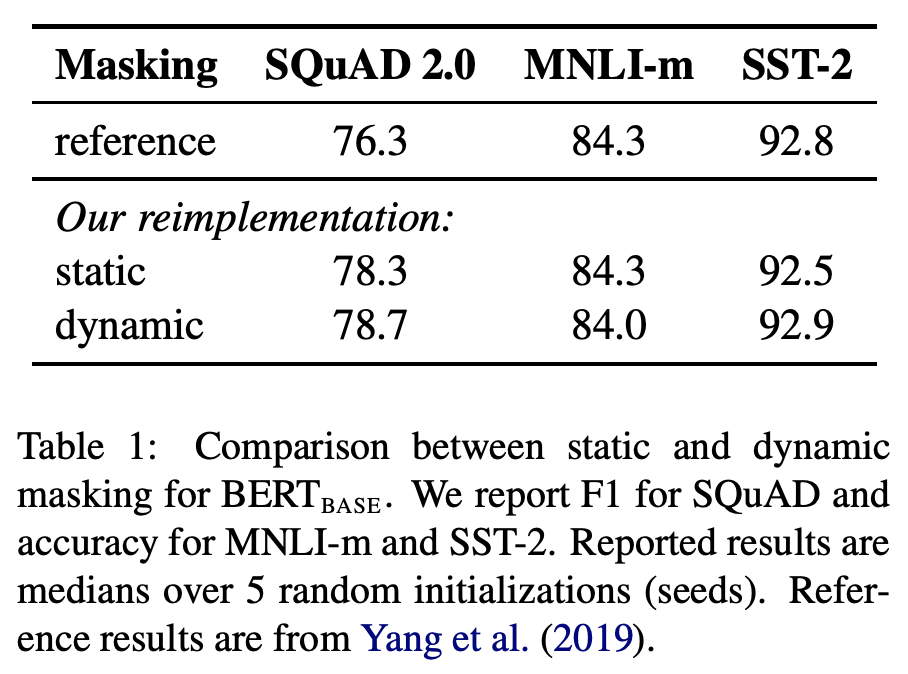
2. Dynamic Masking
Background에서 언급했듯이, BERT의 구현체에서는 Static Masking을 이용했고, 학습 도중 동일한 Mask를 갖는 입력 문장을 반복해서 보게 됩니다. 본 논문에서는 동일한 Mask가 반복되는 것을 피하기 위해 매 학습 epoch마다 다른 Masking을 진행하는 Dynamic Masking을 진행했습니다. 더 많은 step, 더 큰 dataset으로 pre-training할 수록 Dynamic Masking은 중요해 집니다. 저자들은 동일 환경에서 Static과 Dynamic Masking을 구분해서 실험을 진행습니다. 아래 실험결과와 같이 실험 결과 Static masking에 비해 비슷하거나 조금 향상된 결과를 볼 수 있습니다.
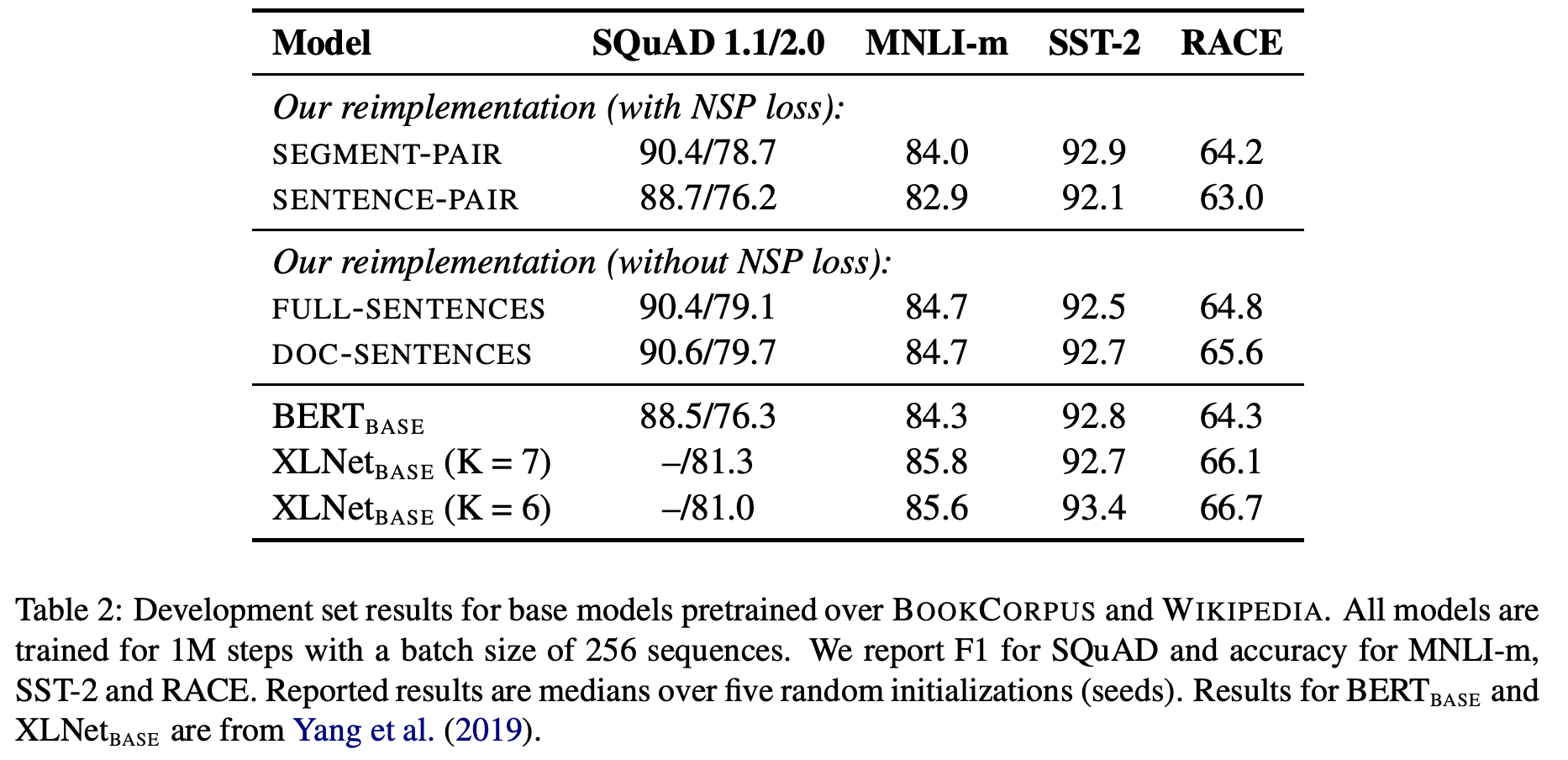
3. Model Input Format and Next Sentence Prediction
BERT의 저자들은 Pair단위의 테스크들을 위해 NSP를 추가했고, 해당 논문의 ablation study에서는 NSP는 Pair단위의 테스크들에서 효과가 있었습니다. 하지만 이는 해당 실험에서 단순히 NSP loss만 제거하고 두 개의 segment가 입력으로 들어가는 구조는 유지했기 때문에 나타난 결과였습니다. 이를 다시 검증하기 위해 본 논문의 저자들은 다음과 같이 4가지 입력 구성으로 실험을 진행했습니다.
- Segment Pair + NSP: BERT와 동일한 설정입니다.
- Sentence Pair + NSP: 각 Segment가 하나의 문장으로만 구성됩니다. 각 segment가 매우 짧기 때문에 batch size를 늘려 다른 구성들과 비교했을 때, 한번에 optimize되는 토큰 수를 비슷하게 설정하였습니다.
- Full Sentence: 각 input은 하나 이상의 문서들에서 연속적으로 샘플링 됩니다. 하나의 문서가 끝나면, 다음 문서를 그대로 연결(특수 토큰으로 분리)하여 총 토큰 갯수가 최대 길이를 최대한 채우도록 구성하였습니다.
- Doc Sentence: 3번 설정과 유사하지만, 하나의 문서가 끝나면 다음 문서를 이용하지 않습니다. 문서가 끝난 경우 토큰 갯수는 최대 길이보다 작게 되는데, 이를 보정하기 위해 batch size를 dynamic하게 조절하여, 한번에 optimize되는 토큰 갯수를 일정하게 유지했습니다.
실험 결과 아래 그림과 같이 Pair단위의 테스크들임에도 불구하고 NSP를 제거했을 때, 전체적으로 좋은 성능을 보입니다. 또한 Full-sentence와 Doc-sentence를 비교했을 때, Doc-sentence의 경우가 미세하게 좋지만 Batch size를 다양하게 조절해야하기 때문에 이후 실험들에서는 Full-sentence의 입력 구성을 이용하였습니다. XLNet과 큰 성능 차이가 나는 이유는 위의 실험들은 더 적은 데이터(Bookcorpus + Wikipedia)로만 학습했기 때문입니다.
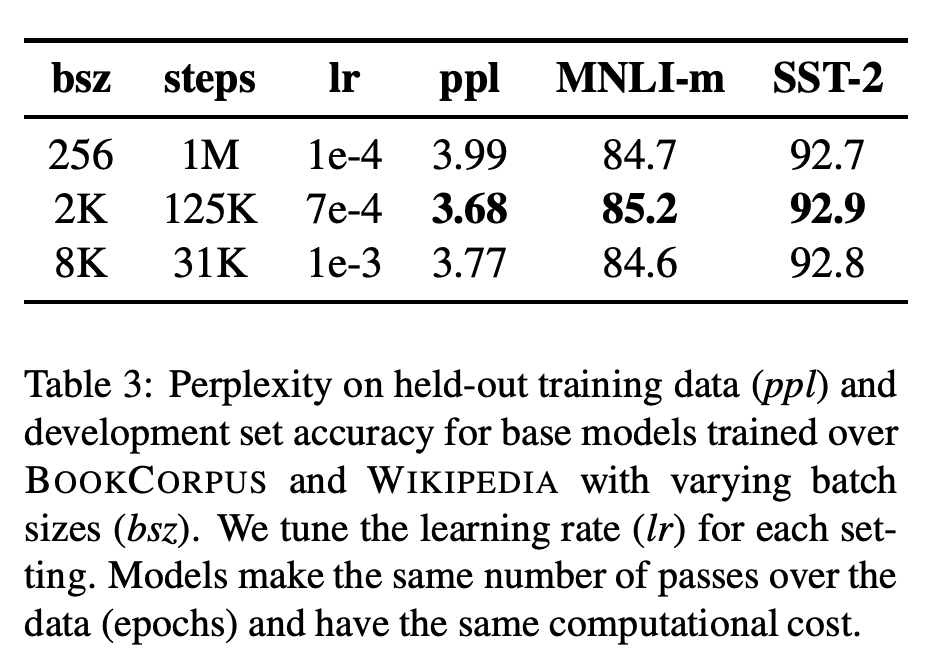
4. Training with Large Batches
최신의 연구들에서 더 큰 batch size와 이에 따른 적절한 Learning rate를 이용하면 optimization 속도 뿐만 아니라 최종 테스크의 성능도 향상됨을 보였습니다. BERT는 256 batch size 로 1M step정도 학습을 진행했습니다. 저자들은 이와 동일한 계산 비용을 유지하면서 batch size를 늘려가면서 실험을 진행했습니다. 실험 결과 아래 그림과 같이 큰 batch size의 설정일때, LM의 ppl 뿐만 아니라 downstream task의 성능도 함께 향상되는 것을 볼 수 있습니다.
5. Text Encoding
Byte-pair Encoding(BPE)은 Word 단위와 Character 단위의 중간에 있는 text encoding방식 입니다. BPE는 입력 텍스트를 sub-word unit들로 나누는데 이는 큰 학습 코퍼스의 통계치에 의해 결정됩니다.
BERT에서는 학습 코퍼스에 휴리스틱한 토크나이징을 진행하고 character-level의 BPE를 학습시켰고, 30k 사이즈의 사전을 이용했습니다. 본 논문에서는 GPT(Radford et al., 2018)에서 소개한 byte단위의 BPE를 학습했고, 50k 사이즈의 사전을 이용했습니다. (사전의 크기가 커져서 base 15M large 20M의 추가적인 파라메터가 이용됩니다.) 선행 연구에서 Byte단위가 character 단위에 비해 조금 안좋은 결과를 보였지만, 저자들은 universal encoding의 이점 때문에 남은 실험들에서 Byte단위를 이용하기로 결정했습니다.
RoBERTa
위에서 진행했던 실험결과들의 최상의 조합으로 Robustly optimized BERT approach(RoBERTa)를 소개합니다. RoBERTa에 이용된 설정은 다음과 같습니다.
- Dynamic Masking 사용
- Full-Sentence의 입력 구성 및 NSP 제거
- 더 큰 Batch size
- Byte-level BPE
- Pre-training에 이용하는 데이터: 16GB(BERT) → RoBERTa(160G)
- English Wikipedia & English Wekipedia(16G)
- CC-News(Common Crawl News corpus, 76G): 2016.9 - 2019.2 까지 뉴스 기사를 크롤링 한 것으로 약 63M개의 뉴스 기사를 포함합니다.
- Open Web Text(38G): reddit에서 up투표를 3이상 받은 공유된 URL의 내용을 크롤링 한 것입니다.(GPT에서도 이용함)
- Stories(31G): 크롤링된 데이터로 story-like style의 형식을 가집니다.
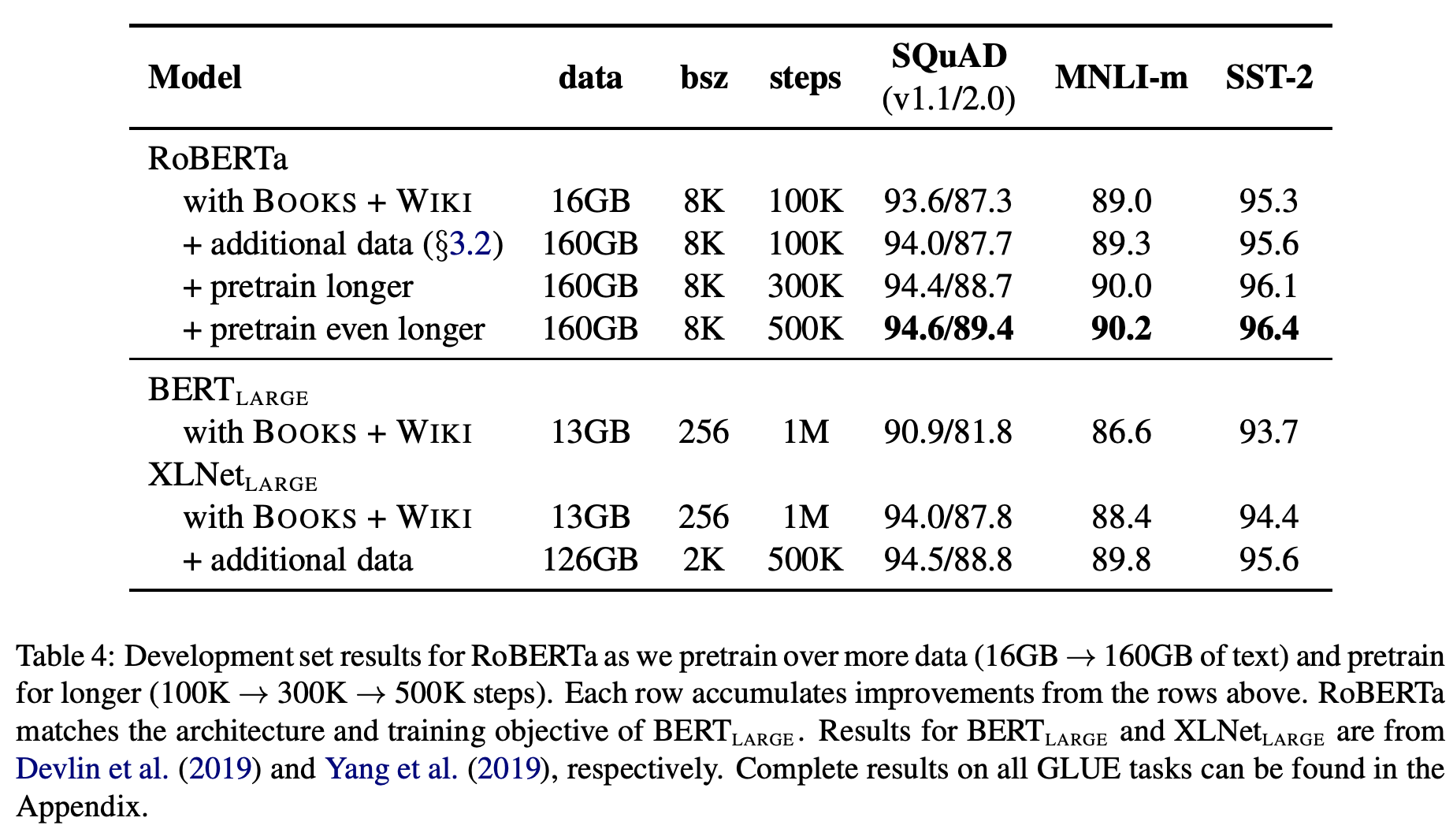
위 결과와 같이 더 많은 데이터로 더 많이 학습할수록 좋은 결과를 보였습니다. 또한 data를 늘려가며 실험했을 때, 가장 오래 학습한 모델에서도 데이터에 오버피팅되는 모습은 나타나지 않았다고 합니다. 따라서 저자들은 pre-training에서 데이터의 양과 다양성의 중요성을 증명했고, 이 부분에서는 조금 더 세밀한 분석이 필요하다고 언급했습니다.
Benchmark Result
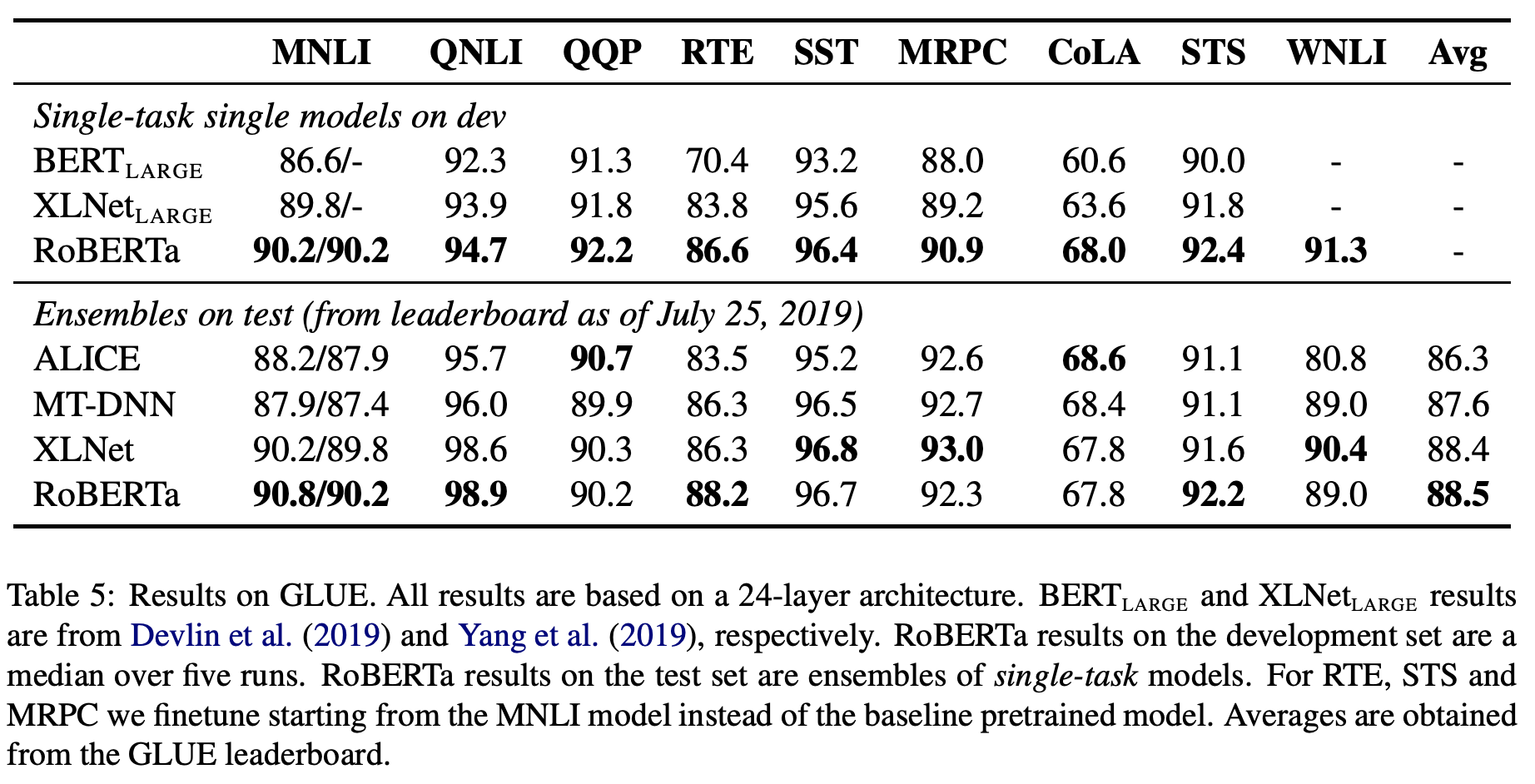
-
Single model 설정: GLUE의 모든 테스크들에 대해 각각 single-training을 진행했고, 다른 논문들과 유사하게 hyper-parameter는 적절한 범위 내에서 선택했습니다. 여기서 큰 차이점은 BERT 및 대부분의 논문들에서 3epoch만 학습하는 반면 10epoch의 학습과 early stopping을 진행했습니다.
-
Ensemble model 설정: 벤치마크의 다른 접근법들과 비교하기 위해 조금 더 넓은 hyper-parameter 범위에서 5~7개의 모델들을 학습하여 앙상블하였습니다. (일반적으로 Multi-task finetuning을 진행하면 성능이 오르지만 이용하지 않았습니다.) 또한 RTE, STS, MRPC는 pre-training 모델로 부터 시작하는것 보다 MNLI로 fine-tuning된 모델을 다시 fine-tuning하는 방법이 더 성능이 좋았다고 합니다.(아마도 MNLI가 pair단위의 테스크 중 데이터의 양이 가장 많기 때문인 것 같습니다.)
결과적으로 위 표와 같이(현재 GLUE benchmark와 다름) single model 설정은 9개의 테스크에서 모두 가장 좋은 성능을 보였고, ensemble model 설정은 4개 테스크의 성능과 평균 성능에서 가장 좋은 성능을 보였습니다. RoBERTa는 BERT와 동일한 모델 구조와 Masked-LM objective를 이용하면서 다른 모델 구조(XLNet) 및 training objective(XLNet, StructBERT-ALICE)를 사용한 접급법들을 능가했습니다.(현 시점 10/19기준 StructBERT가 더 좋은 성능을 보입니다.) 저자들은 이 점들에 주목하면 본 논문에서 주목한 학습시간 및 데이터의 양등 일반적인 요소들이 모델 구조나 training objective등 세밀하고 복잡한 요소들에 비해 상대적인 중요도가 높을 수 있다고 주장합니다.
이외에도 SQuAD와 RACE 벤치마크 결과에 대한 설명도 있었지만 해당 테스크들 또한 SOTA달성으로 GLUE와 비슷한 양상이기 때문에 생략하겠습니다.
Reference
-
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv, 2019
-
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc VLe. XLNet: Generalized autoregressive pretraining for language understanding. arXiv, 2019.
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep idirectional transformers for language understanding. In Proceedings of the 2019 Conference of he North American Chapter of the Association for Computational Linguistics(NAACL), 2018.
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems(NeurIPS), 2017.
-
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. Technical report, OpenAI.