
이번 글에서는 Alibaba Group에서 연구한 “StructBERT: Incorporating Language Structures into Pre-training for Deep Langauge Understanding”를 리뷰하려고 힙니다. 본 논문은 현재 ALBERT에 이어 GLUE 벤치마크 리더보드에서 89.0(2위)의 점수를 얻고 있습니다. 언어의 유창함은 단어와 문장의 순서에 의해 결정되는데, 본 논문에서는 sequential modeling은 “순서”에 대해 주목했습니다. BERT pre-training 단계에서 문장 내부와 문장들 사이 순서의 구조적 정보를 학습할 수 있는 새로운 전략을 제시합니다.
Main Idea
-
BERT에서 Bidirectional Transformer Encoder를 이용하여 두 개의 Objective(Masked-LM, NSP)를 pre-training하여 각 토큰의 Contextual representation을 얻을 수 있었습니다. 본 논문에서는 pre-training 단계에서 특정 토큰들 및 문장들의 “순서”를 예측하는 문제를 추가함으로써, 모델이 잘 정제된 단어 구조와 문장간의 구조를 학습하도록 했습니다.
-
이상적으로 잘 학습된 Language model은 랜덤한 순서의 단어들이 주어졌을 때, 이를 복구할 수 있어야 하는데, BERT의 학습전략으로는 단어들의 sequential 순서와 단어들의 고차원 의존성을 정확히 모델링하지 못한다고 언급합니다. 이러한 문제를 해결하기 위한 새로운 단어 단위의 pre-training objective를 제시합니다.
-
NSP objective는 쉽게 97-98% 정도의 정확도에 도달할 수 있는데, 이는 문제 자체가 너무 쉽기 때문입니다. 이러한 점에서 NSP를 확장하여 조금 더 어려운 문장들(segment) 사이의 관계를 모델링할 수 있는 pre-training objective를 제시합니다.
StructBERT
1. Model Architecture
기본적으로 StructBERT는 입력 문장의 contextual representation을 인코딩하기 위해, Multi-Layer Transformer Encoder, 즉 BERT의 모델 구조를 수정없이 그대로 이용합니다. 입력의 형태또한 BERT의 방식과 동일하게 [CLS] + Segment1 + [SEP] + Segment2 + [SEP]를 이용합니다. 두 segment를 구분하기 위한 segment embedding 및 토큰의 position을 구분하기 위한 positional embedding역시 동일하게 이용합니다.
2. Word Structural Objective
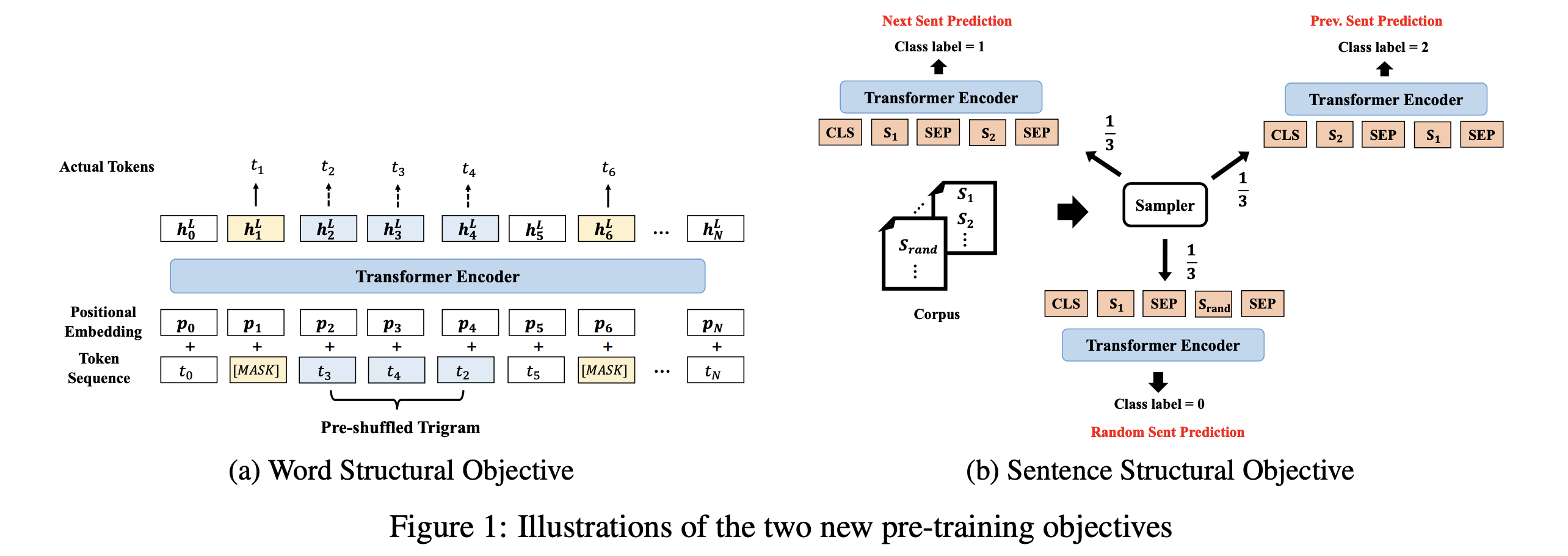
특정 범위 내에서 임의로 섞여진 토큰들을 원래의 순서로 복구하는 문제를 풀고자 합니다. Masked-LM이 임의로 토큰을 Masking하고 classifier가 [MASK] 토큰의 위치에서 원래 토큰의 likelihood가 최대가 되도록 학습한다면(위 그림의 노란색), 이 방법은 임의로 섞여진 토큰들이 주어지고, classifier는 해당위치에서 올바른 토큰의 likelihood가 최대가 되도록하는 학습합니다.(위 그림의 파란색) 즉 이 obejctive는 \(arg \max_{\theta} \sum \log P(pos_1 = t_1, pos_2 = t_2, ...pos_K = t_K \mid t_1, t_2, .... , t_K, \theta)\) 와 같이 나타낼 수 있습니다. 여기서 K는 섞여지는 subsequence의 길이인데, K가 클수록 모델은 순서가 더 많이 어그러진 문장을 복구하게 됩니다. 본 논문에서는 K=3으로 하여 최대 trigram 내부에서만 순서를 섞었습니다. 이 문제는 다음과 같은 과정으로 진행됩니다.
- 입력 토큰들의 15%를 masking하고 이를 Transformer Encoder로 인코딩 한 후, 이를 이용하여 원래의 토큰을 예측합니다.
- masking이 되어 있지 않은 trigram중 일정 부분을 랜덤으로 선택하여 해당 토큰들을 섞습니다.
- 이렇게 섞여진 입력을 다시 Transformer Encoder로 인코딩 한 후, softmax classifier로 원래 토큰 순서를 예측합니다. 위 그림과 같이 \((t_3, t_4, t_2)\) 가 주어지면 각각의 위치에서 \((t_2, t_3, t_4)\)를 예측하도록 합니다.
Masked-LM Objective와 새롭게 제시한 Word Ordering Objective는 동일한 모델로 한번에 함께 학습되며(jointly learned), 동일한 가중치로 학습됩니다. (최종 loss에 반영비율이 같습니다.)
3. Sentence Structural Objective
BERT는 Auxiliary task로 Next Sentence Prediction(NSP)을 제시합니다. 이는 [CLS] + Segment1 + [SEP] + Segment2 + [SEP]의 형식에서 Segment2 가 Segment2 다음에 오는 것이 맞는지 예측하는 문제입니다. BERT의 저자들은 문장들 쌍의 모델링(QA, NLI, Similairty 등)을 위해 이와 같은 obejective를 제시했습니다.
본 논문에서는 NSP에 이전 문장 예측를 추가적으로 확장합니다. Segment2가 Segment1 다음에 오기에 적절한 Segment인지 예측할 뿐만 아니라 Segment2가 순서상 Segment1 이전에 오기에 적절한지 추가적으로 예측합니다. 즉 3가지 클래스에 대한 분류문제를 풀게 됩니다. 따라서 다음과 같이 데이터 셋을 구성합니다.
- segment1 뒤에 segment2가 자연스럽게 이어지는 데이터 (BERT의 Positive sample과 동일)
- segment1 뒤에 다른 document로 부터 임의로 추출한 segment2로 구성된 데이터 (BERT의 Negative sample과 동일)
- segment1 뒤에 segment1 이전의 문장들로 segment2를 구성한 데이터 (본 논문에서 새롭게 제시하는 previous sentece prediction)
저자들은 모든 위의 3가지 방법들을 동일한 확률(1/3)로 샘플링했습니다. 그리고 학습시에 BERT의 방식과 동일하게 Transformer Encoder의 최종 hidden state의 [CLS]토큰 representation을 이용하여 classifier를 학습했습니다.
4. Pre-training Setup
최종 objective fuction은 Word Structural Objective(MLM + Word ordering)와 Sentence Structural Objective의 선형 결합으로 구성됩니다. Masked LM을 위해 Masking prob(15%) 등을 BERT와 동일한 설정으로 유지했고, Word ordering을 위해서 전체 중 5%의 trigram을 선택하여 셔플링을 진행했습니다. 다른 설정들은 다음과 같습니다.
- 학습 데이터: 영어 Wikipedia + BookCorpus(BERT와 동일한 설정)
- Tokenizer: WordPiece
- Max Sequence Length: 512
- Optimizer: Adam(learning rate = 1e-4, \(\beta_1 = 0.9\), \(\beta_2 = 0.999\), L2 weight decay = 0.01, linear warmup = 초기 10% step)
- 모든 layer에 0.1확률의 dropout, gelu activation
모델은 \(BERT_{Base}\), \(BERT_{Large}\)와 모델 하이퍼파라메터가 같은 두 개의 모델 \(StructBERT_{Base}\),\(StructBERT_{Large}\)을 이용하여 학습을 진행했습니다.
Experiment Result
총 3개의 Downstream task [General Language Understanding Evaluation(GLUE), Stanford Natural Language Inference(SNLI), Stanford Question Answering Dataset(SQuAD v1.1)]에 대해 fine-tuning을 진행했습니다. Fine tuning에서는 Batch size {16,24,32}, Learning rate {2e-5, 3e-5, 5e-5}, Number of epochs {2, 3}, Dropout rate {0.05, 0.1}의 하이퍼 파라메터에 대해 exhaustive search를 진행했고, dev set에서 가장 좋은 성능을 보인 모델을 선택했습니다.
1. GLUE
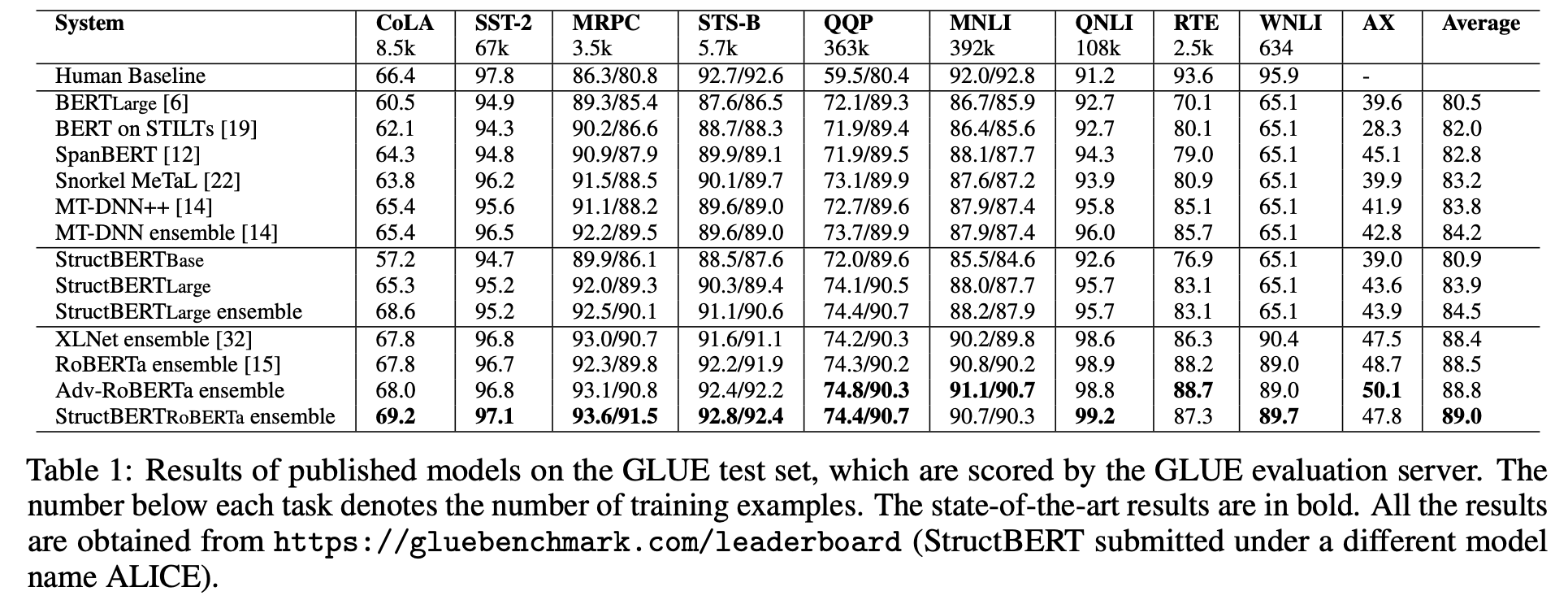
GLUE 벤치마크는 총 9개의 NLU 테스크들로 구성되며 각 테스크들의 성능들을 평균하여 최종 점수를 계산합니다. StructBERT는 Fine-tuning시에 테스크 마다 다른 전략을 이용했습니다. 기본적으로 MRPC/RTE/STS-B/MNLI는 문장 pair단위로 진행하는 테스크로 유사성이 있습니다. 각 데이터셋의 양은 MRPC(train 4.1k/dev 1.7k), RTE(train 2.4k/dev 0.2k), STS-B(train 5.7k /dev 1.4k), MNLI(train 392k/dev 20k)로 구성됩니다. MNLI에 비해 다른 데이터셋은 학습셋이 매우 적은데, 이에 따라 저자들은 MNLI데이터 셋으로 fine-tuning을 진행한 모델을 다시 한 번 MRPC/RTE/STS-B 각 데이터셋으로 fine-tuning 하였습니다. 나머지 테스크들에 대해서는 해당 테스크의 데이터셋으로만 fine-tuning하는 일반적인 방법으로 진행하였습니다.
XLNet/RoBERTa 등의 최신 연구에서 pre-training시 추가적인 데이터의 이용은 큰 성능 향상을 가져온다는 것을 증명했습니다. 위의 표에서 StructBERT는 추가적인 데이터를 이용하지 않고 BERT와 동일한 설정을 이용했기 때문에 XLNet, RoBERTa와 동등한 비교가 이루어지지 않습니다. 따라서 저자들은 RoBERTa에 본 논문에서 제시한 두 개의 objective를 추가한 StructBERTRoBERTa를 학습했습니다. 결과적으로 추가적인 데이터를 이용하지 않은 경우에는 동일 설정의 나머지 모델들(BERT, SpanBERT, MT-DNN)에 비해 뛰어난 성능을, 추가적인 데이터를 이용한 경우에도 RoBERTa, XLNet보다 뛰어난 성능을 얻었습니다.
2. SNLI

SNLI도 두 문장간의 의미적 관계를 파악하는 테스크 입니다.(위의 MRPC, RTE, STS-B, MNLI와 유사함) 두 문장이 entailment/contradiction/neutral 중 어떤 관계인지 분류하는 문제를 풉니다. StructBERT는 문장간의 관계에 조금 더 집중할 수 있는 sentence ordering objective를 제시한 만큼 위 그림과 같이 기존모델에 비해 향상된 결과를 보였습니다.
3. Extractive Question Answering
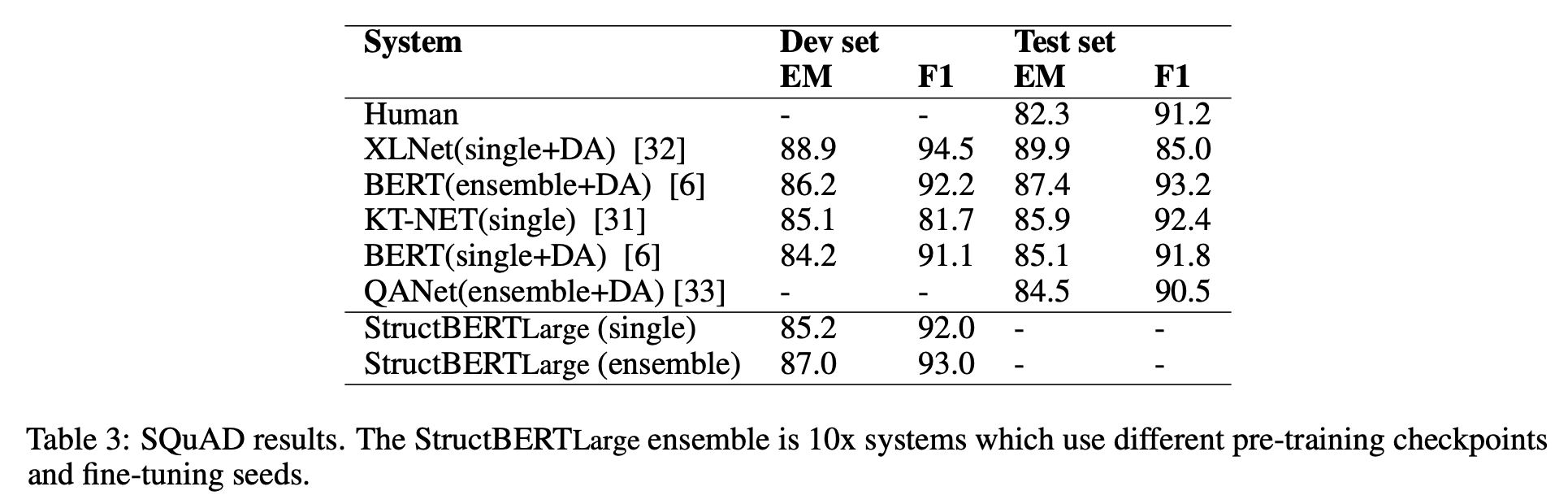
Extractive Question Answering은 질문과 해당 질문에 관계있는 문단이 주어졌을 때, 질문의 답이 해당 문단에서 어떤 “span”인지 추출하는 문제를 푸는 것입니다. (즉, 문단에서 답의 처음 index와 끝 index를 추출하는 것입니다.) 저자들은 Data Augmentation(DA)기법을 사용하지 않고 리더보드에서 XLNet을 제외한 나머지 모델들 보다 우수한 성능을 보였습니다. (XLNet은 큰 코퍼스로 pre-training + DA의 효과로 더 좋은 성능을 냈음.)
Ablation Study
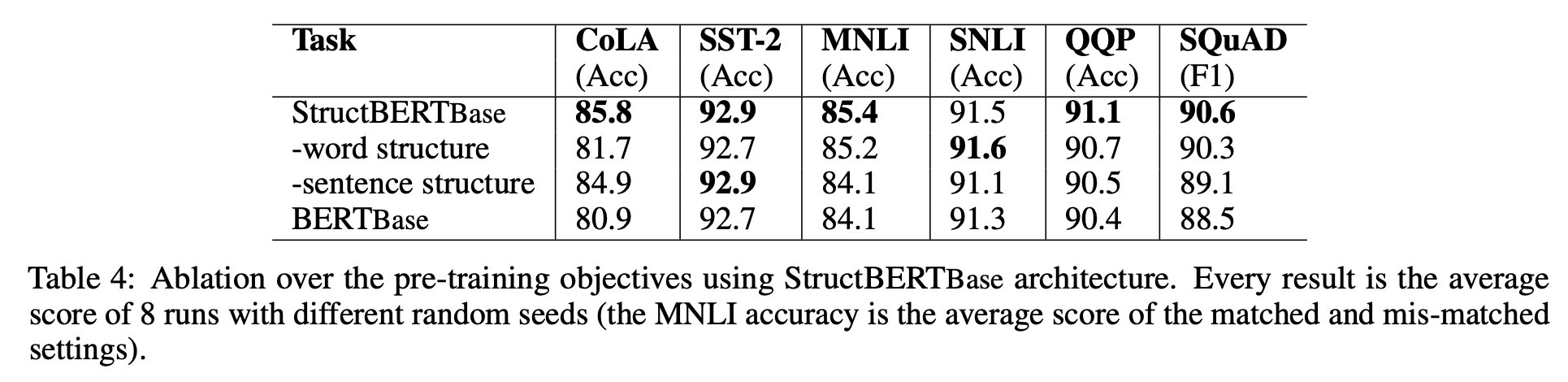
본 논문에서 제시하는 핵심 아이디어는 두 가지 새로운 Objective(Word Structural Objective와 Sentence Structural Objective)입니다. 저자들은 각 objective의 효과를 검증하기 위해 pre-training과정에서 각 objective에 대한 ablation study를 진행했습니다.
위의 결과와 같이 두 가지 objective는 모두 대부분의 downstream task 성능에 큰 영향을 미쳤습니다.(SNLI를 제외한 나머지 테스크만 해당함.) Pair 단위의 테스크들(MNLI, SNLI, QQP, SQuAD) 에서는 문장 사이의 관계를 모델링하는 sentence structural objective가 효과가 있었습니다.. 그리고 Single Sentence를 대상으로 하는 테스크들(CoLA, SST)에서는 단어 사이의 관계를 모델링하는 word structural objective가 효과가 있었습니다. 특히 문법적 오류를 교정하는 CoLA에 대해서는 약 5%의 큰 성능 향상이 있었는데, 이는 pre-training에서 단어 순서를 교정하는 word structural objective가 많은 도움을 주었다고 볼 수 있습니다.
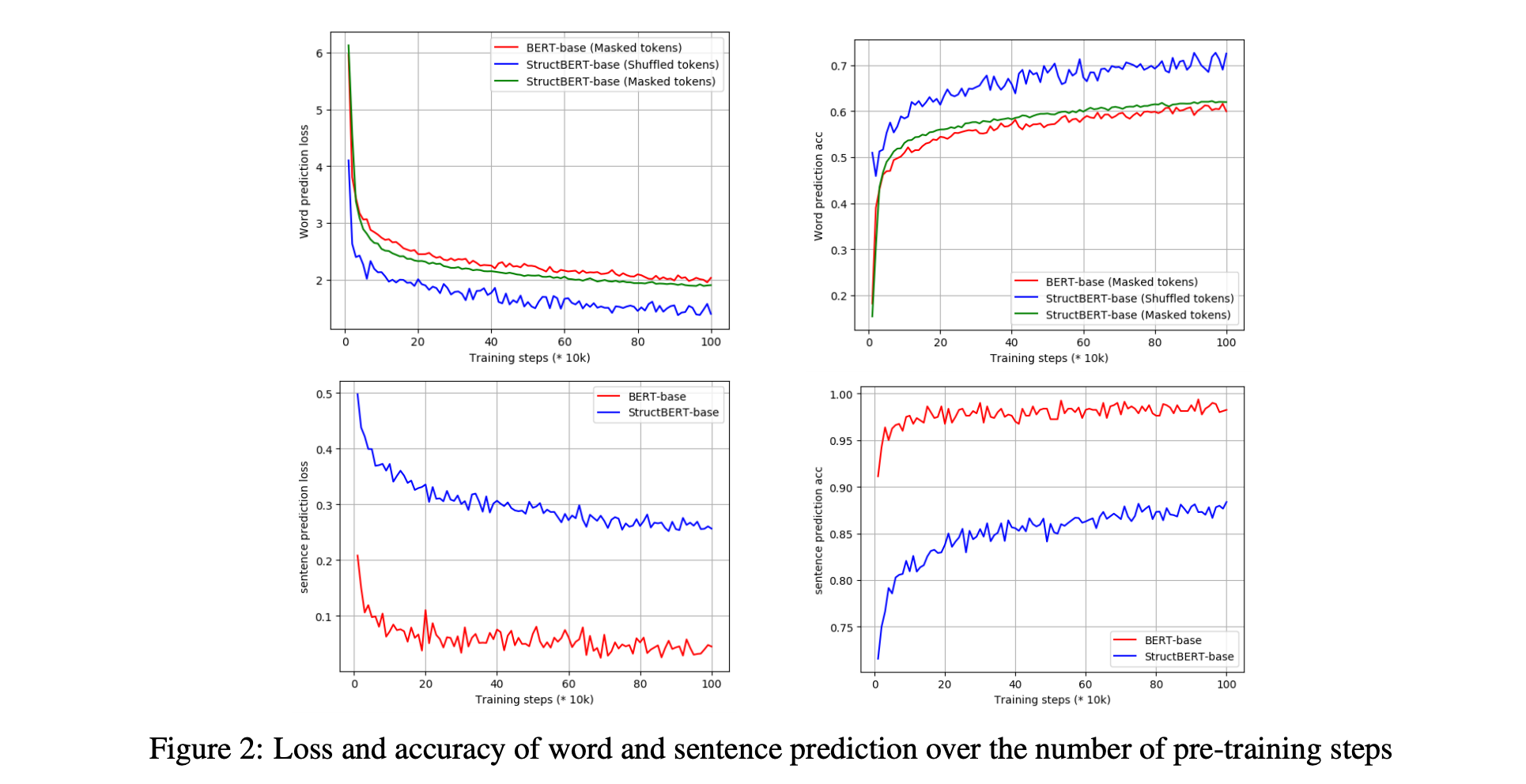
마지막으로 BERT와 StructBERT의 pre-training 양상은 위 그림과 같이 나타납니다. 위 두 개의 그림을 보면, StructBERT에서 기존 BERT보다 조금 더 수렴되고 향상된 Masked-LM 성능을 볼 수 있는데, 이는 Word structural objective가 MLM에도 긍정적인 영향을 미쳤기 때문으로 볼 수 있습니다. 또한 Word Ordering 테스크 또한 70% 정도의 상당히 높은 정확도를 보이고 있는데, 이는 모델이 단어 순서를 예측하는 비교적 어려운 테스크에 대해서도 잘 학습된다는 것을 보여줍니다.
아래 두 개의 그림에는 각각 Sentence Prediction 테스크에 대한 결과를 나타냅니다. ablation study에서 Sentence structural objective는 pair단위의 테스크들에서 성능 향상을 보였습니다. 해당 논문에서 처음에 제시했던 BERT의 next sentence prediction(약 97~98%의 성능)에 비해 조금 더 도전적인 Sentence Order Prediction(약 87~88%의 성능)을 제시하면서 pre-training 테스크 자체의 성능은 낮지만 downstream 테스크에서 큰 효과를 보일 수 있음을 증명했습니다.
Reference
-
Wei Wang, Bin Bi, Ming Yan, Chen Wu, Zuyi Bao, Liwei Peng, and Luo Si. StructBERT: Incorporating language structures into pre-training for deep language understanding. arXiv, 2019.
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep idirectional transformers for language understanding. In Proceedings of the 2019 Conference of he North American Chapter of the Association for Computational Linguistics(NAACL), 2018.