
BERT를 시작으로 NLP의 Imagenet이라 불리며 Self-supervised Learning 방법이 대부분의 NLP task들에서 SOTA(State-of-the-art) 성능을 보여주고 있습니다. 최근에는 BERT의 한계점/문제점들을 분석&해결하여 더 높은 성능을 가지는 모델 및 학습방법들이 연구되고 있습니다. 이번 글에서는 현재(10월 13일기준) Natural Language Understanding의 대표적인 벤치마크인 GLUE(General Language Understanding Evaluation) 리더보드에서 종합 89.4의 점수를 기록하면서 1등을 하고 있는 “ALBERT: A Lite BERT for self-supervised learning of language representations”를 리뷰하려고 합니다. (ICLR 2020 Under review paper)
Main Idea
- BERT등의 pre-training → fine-tuning 구조의 이전 논문들에서 모델사이즈의 증가는 성능 향상을 가져왔습니다. 그러나 모델사이즈가 커질 수록 memory/latency이슈가 생기고 학습속도가 느려지기 때문에 더 이상 늘리는 것은 불가능합니다. 이를 해결하기 위해 새로운 parameter reduction 기술을 소개 하고자 합니다.
- BERT-Large에서 hidden size를 2048로 늘려서 실험을 진행했을 때, 기존 모델(BERT-Large)보다 훨씬 못한 성능을 보여주었습니다. 이는 BERT 구조 및 학습 전략을 따른다면 파라메터 수를 늘리는 것도 한계가 있다는 것을 의미합니다. Hidden size를 늘리면서도 모델을 안정적으로 학습할 수 있는 방법을 제시합니다.
- 좋은 sentence embedding을 학습하기 위해 skip-thought, Fastsent등의 학습 방법들이 연구되었습니다. (BERT의 Next Sentence Prediction도 여기에 해당됩니다.) 내부 문장(inter-sentence)들 간의 관계/일관성을 파악할 수 있는 새로운 self-supervised loss를 제시합니다.
ALBERT: A Lite BERT
1. Model Architecture의 구성
기본적으로 BERT와 유사하게 Transformer Encoder 기반의 모델 구조를 이용합니다. 모델의 크기는 BERT의 하이퍼 파라메터와 동일한 Transformer Layer(Block) 수 L, Hidden Size H, Feedforward filter size(Intermediate Layer) 4H, Attention Heads H/64 와 본 논문에서 추가된 단어 임베딩 사이즈 E 에 의해 결정됩니다. (BERT 에서는 단어 임베딩 사이즈와 Hidden size가 동일하였습니다.)
2. Factorized embedding parameterization
BERT는 단어 단위의 정적 임베딩, WordPiece Embedding (한 단어/토큰당 고정된 하나의 임베딩 값을 가지는 것)을 이용하여 Self-Attention Layer를 통해 Contextual한 Embedding을 만들어 나갑니다. 기존의 BERT 및 후속 연구의 모델들은 WordPiece Embedding의 차원(E)과 Contextual Embedding의 차원(H)이 같았는데, 이는 embedding layer의 파라메터 수가 커지는 원인입니다. 일반적으로 Embedding layer는 총 사전의 토큰(단어) 갯수 (V) * Word Embedding 차원(E), \(O(V \times E)\) 만큼의 파라메터를 갖습니다. 이는 V=30000, E=768인 BERT-base기준 Word Embedding에서 약 23M개인데, 총 파라메터 108M 대비 21%로 상당히 큰 부분을 차지합니다.
또한 이전 연구들에서 BERT는 Word단위 Representation보다는 Self-Attention을 이용해 만들어진 Context-representation에 기반한다는 것을 보였습니다. 이에 근거하여, 본 논문에서는 E를 줄이는 방법을 시도했습니다. H » E인 E를 이용하여 Word Embedding을 계산하고, 이를 다시 H에 맞게 늘려서(Feedforward layer하나를 추가해서) BERT encoder에 입력으로 넣어줍니다. 따라서 \(O(V \times E + E \times H)\) 만큼의 파라메터를 갖습니다. 이는 V=30000, E=128, H=768 기준 약 4M으로 기존 방법에 비해 약 1/6정도의 양으로 볼 수 있습니다.
3. Cross-layer parameter sharing
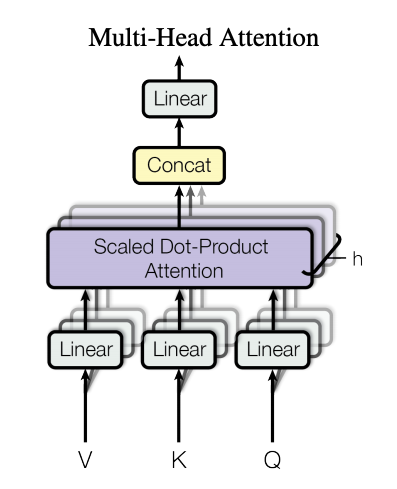
BERT는 L개의 독립적인 Transformer Block(Multi-head Attention + FeedForward)들을 순서대로 거쳐가면서 Contextual Embedding을 형성해 나갑니다. 따라서 각 Layer별로 각각의 파라메터들이 Optimize되고, Layer수에 비례하여 파라메터의 개수 & 메모리가 많아지게 됩니다.(\(Layer수 \times 1 \space Layer \space parameters\)) 반면에 ALBERT에서는 공통의 파라메터를 각 Layer에서 공유하는 방법을 이용합니다. 각 Layer를 거칠 때마다, 동일한 파라메터를 재사용하여 연산을 진행하게 됩니다. 따라서 Layer의 모든 parameter를 공유하는 경우 \(1 \space Layer \space parameters\) 만큼 파라메터 개수 & 메모리를 이용하게 됩니다.
Transformer Block를 간단하게 살펴보면, 위그림과 같이 1) 입력을 Feedforward Net을 거쳐 Multihead로 나누기 → 2) 각 head별 Attention연산 → 3) Feedforward(Intermediate) Layer 연산으로 구성됩니다. (Layer Norm, Residual Connetction 등도 존재함) 여기서 여러 가지의 파라메터 공유를 하는 방법을 시도해볼 수 있는데, 본 논문에서는 Attention의 파라메터만 공유, Feedforward의 파라메터만 공유, 모든 파라메터의 공유의 3가지 방식으로 실험을 진행했습니다.
- Attention의 파라메터만 공유: Attention연산 자체는 파라메터가 없는데, 여기서 말하는 Attention의 파라메터는 Multihead-Attention 연산 전에 Q,K,V가 이용하는 Linear layer의 파라메터입니다.
- Feedforward의 파라메터만 공유: Transformer에서는 Attention의 결과를 Linear(Feedforward Net)를 이용하여 더 큰차원(4 * H)으로 늘렸다가 다시 H 차원으로 줄이는 Intermediate Layer가 존재하는데, 이 파라메터를 공유합니다.
4. Inter-sentence coherence loss
BERT는 두 가지 loss(Masked LM + Next Sentence Prediction)를 이용하는데, NSP는 pair-sentence단위의 task들(NLI, QA 등)을 위해 고안되었으나 많은 후속 연구들(RoBERTa, XLNet)에서 성능을 해치는 요인으로 지적받았습니다. 그 이유는 다른 도큐먼트에서 랜덤한 segment를 추출하여 negative sample을 만드는 방식에 의해 전혀 관계없는 정보에도 attention이 생겨 noise로 작용하기 때문입니다. 또한 제한된 길이(일반적으로 512) 내에서 서로 관계없는 두 개의 segement를 분리하여 넣는 것보다 최대길이에 맞춰 하나의 segment로 학습(NSP없이)하는 것이 좋은 성능을 보였습니다.
본 논문에서는 또 다른 부분을 지적합니다. 일반적으로 BERT pre-training시에 NSP의 정확도는 95%이상으로 수렴하게 되는데,이는 이 문제가 매우 쉽게 풀리기 때문입니다. NSP를 위한 negative sampling 은 다른 도큐먼트들 중 random으로 선택하는 방식을 이용하는데, 해당 방식은 각 segment의 토픽만 제대로 파악하면 바로 맞출 수 있는 문제입니다. 따라서 문장들 간의 내부 연관성을 파악하는 것(본래 NSP의 목적)이 아닌 단순 토픽 선택 문제 정도가 됩니다.
이 문제점을 해결하기 위해, 내부 문장간의 관계를 이해할 수 있는 새로운 Sentence-Order Prediction(SOP) loss를 소개합니다. positive는 BERT와 동일하게 유지하고, 기존의 연속적인 segment들의 앞뒤 순서를 바꿔서 negative sample을 만듭니다. 즉 한 도큐먼트 내에서 해당 문장들의 순서가 올바른지(Positive), 반대로 되어있는지(Negative)를 구분하는 문제를 풀게 됩니다. 이렇게 되면 토픽이 아닌 문장의 내부 구조 자체를 이해 해야만 문제를 풀 수 있게 됩니다. (부가적으로 동일 도큐먼트 내에서 순서를 섞는 작업만 이루어지기 때문에 다른 논문들에서 제시한 attention 문제도 해결하게 됩니다.)
Experiment Detail
1. Model Setup

실험은 위와 같이 총 7개의 설정으로 진행되었습니다. ALBERT는 base, large, xlarge, xxlarge의 4가지 모델을 이용하였고, 비교 대상은 BERT(Devlin et al., 2019)로 base, large, xlarge를 이용하였습니다. 저자들은 ALBERT xxlarge의 경우 12layer와 24layer의 성능차이가 거의 없었기 때문에 12layer를 채택하였습니다. 또한 cross-layer parameter sharing의 효과로 Layer 수를 늘려도 파라메터의 수가 변하지 않기 때문에 Hidden size 4096의 경우(xxlarge)에도 BERT-Large에 비해 적은 파라메터를 가지는 것을 볼 수 있습니다.
2. Experimental Setup
- Dataset: BookCorpus + English Wikipedia (16GB) - BERT와 동일
- Input의 구성방식:
[CLS]+ \(x_1\) +[SEP]+ \(x_2\) +[SEP]- BERT와 동일 - Maximum input length: 512, 10%의 확률로 Max length보다 작은 길이를 이용 - BERT와 동일
- Tokenizer & Vocab: SentencePiece, 30000 vocab size
- Masking method: N-gram masking (SpanBert의 방법), 최대 길이는 3 길이는 \(p(n) = \frac{1/n}{\sum^N_{k=1}1/k}\)의 분포에 따라 샘플링
- Batch size: 4096
- Optimizer & Learning rate: LAMB Optimizer & 0.00176
- Step: 125000
BERT와의 비교를 위해 원 저자와 비슷한 설정(데이터셋, input, max length)을 유지했습니다. 또한 최신의 연구들에서 성능 향상이 증명되었던 N-gram masking(SpanBERT)뿐만 아니라 큰 batch size(RoBERTa 등) 또한 이용하였습니다. 동일한 비교를 위해 위의 조건으로 ALBERT와 BERT또한 학습했습니다.
3. Evaluation Benchmark
pre-training 중에는 모델이 잘 수렴하고 있는지 확인을 위해(단 이 성능을 이용해 모델을 선택하는 등 downstream task에 영향을 주는 행위는 피했다고 합니다.) RACE 와 SQuAD dataset을 이용하여 내부적으로 MLM 및 SOP 성능을 확인했습니다.(아마 Wiki나 Book Corpus와 가장 비슷한 종류의 데이터이기 때문에 이용하였을 것으로 추측됩니다.)
Downstream task에서는 NLU, Reading comprehension의 대표인 General Language Understanding Evaluation(GLUE), Stanford Question Answering Dataset(SQuAD), ReAding Comprehension from Examinations(RACE)의 3가지 벤치마크를 대상으로 실험을 진행하였습니다.
4. Result
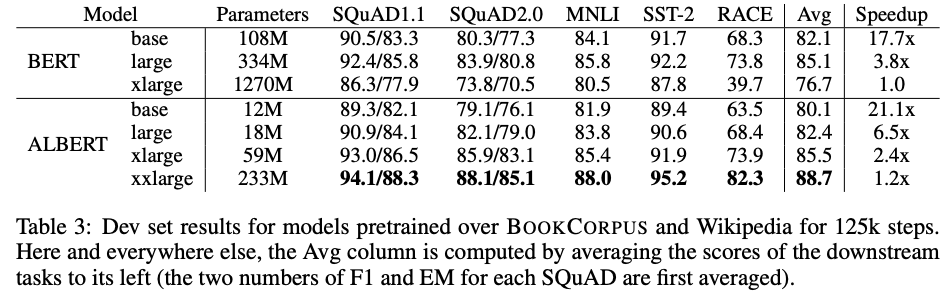
위 결과와 같이 ALBERT-xxLarge는 BERT-Large에 비해 약 70%의 파라메터로 모든 Evaluation task에서 월등히 뛰어난 성능을 보여주고 있습니다. 이는 파라메터들을 더욱 효율적으로 사용하도록 학습되었다고 볼 수 있습니다. 또한 BERT-xLarge는 Large에 비해 훨씬 좋지않은 성능을 보여주는데, BERT와 같은 구조에서 많은 파라메터를 가진 모델은 더 학습하기 힘들다는 것을 알 수 있습니다. 학습 시간또한 BERT-xLarge에 비해 ALBERT-xxLarge는 약 1.2배, ALBERT-xLarge는 약 2.4배 빨라졌습니다.
5. Ablation Study
5.1 Factorized Embedding Parameterization
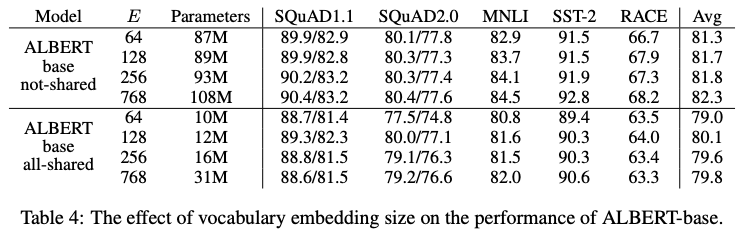
Factorized Embedding Parameterization 방법의 효과를 검증하기 위해, BERT-style(파라메터 공유 x)와 ALBERT-style(모든 파라메터 공유)의 두 조건 아래에서 각 Embedding차원(E)에 따른 downstream task성능을 비교했습니다. BERT-style에서는 embedding 사이즈가 커질수록 좋은 성능을 보였지만, ALBERT-style에서는 E=128인 경우 가장 좋은 성능을 보였습니다.
파라메터를 공유하는 조건에서는 Embedding 차원에 따라 전체 parameter 개수가 크게 차이나는데, 특히 768인 경우 Embedding에서 약 23M개(전체의 74%)로 Embedding이후 파라메터 보다 많은 비율을 차지하게 됩니다. 저자들의 자세한 언급은 없지만, 이 설정에서는 embedding 이후 파라메터들의 개수가 더 적지만 Optimize는 더 많이 이루어지기 때문에(layer 수 만큼 더 많이 진행) 상대적으로 embedding layer를 Optimize하기 힘들어 성능이 떨어지는 것으로 추측됩니다. 이 실험 결과에 따라 이후 세팅에서는 128차원 임베딩을 이용하였습니다.
5.2 Cross-Layer Parameter Sharing
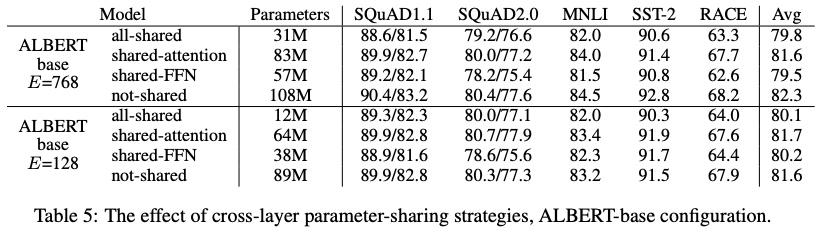
Cross-Layer Parameter Sharing 방법의 효과를 검증하기 위해 두 개의 Embedding 조건(E=768, E=128)에 대해 각각 4 가지 실험(모든 파라메터 공유, attention 파라메터만 공유, FFN 파라메터만 공유, 공유하지 않음)을 진행했습니다. 파라메터 개수를 보면, 모두 공유(12M) < FFN만 공유(38M) < attention만 공유(64M) < 공유하지 않음(89M) 순인데 모델에서 FFN이 차지하는 파라메터가 가장 많고 그 다음으로 Attention이 많기 때문에 FFN을 공유하는 경우 파라메터가 더 많이 줄어드는 것을 볼 수 있습니다.
E=768 인 경우, 공유하지 않는 실험(BERT와 완전히 동일)이 가장 좋은 성능을 보여주었고, Attention만 공유하는 실험이 성능 하락이 가장 적었습니다. 하지만 모두 공유하는 실험에서는 평균 성능에서 약 2.5정도의 성능 하락이 있었습니다.
E=128 인 경우, Attention만 공유하는 실험의 결과가 가장 좋았고, 모두 공유하는 실험에서는 평균 성능에서 약 1.5정도의 성능 하락으로 768의 경우보다 비교적 적은 성능 하락이 있었습니다.
결과적으로 본 논문에서는 모든 파라메터를 공유하는 방법을 선택했습니다. 결과만 보았을 때에는 이해가 되지 않을 수 있지만, 파라메터 수를 본다면 12M으로 줄어들어 89M 대비 약 13%의 파라메터만 이용하여 1.5밖에 성능 하락이 없는 것으로 볼 수 있기 때문에 충분히 이상적인 선택입니다. (파라메터 개수에서 많은 이점을 얻을 수 있습니다.)
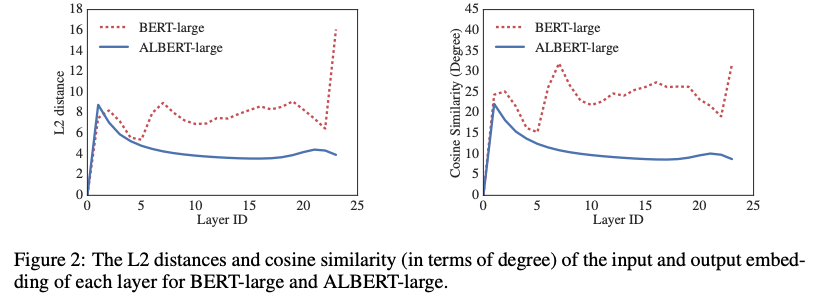
위의 그래프와 같이, 파라메터 공유의 또 다른이점은 파라메터들을 안정화 시켜준다는 것입니다. 왼쪽 그래프는 특정 layer의 input과 output의 L2 distance (크기 차이)이고 오른쪽 그래프는 cosine similarity (각도 차이)를 나타냅니다. 각 값들이 클수록 해당 layer에서 많은 변화가 있는 것을 나타낸다고 볼 수 있습니다. ALBERT의 경우 BERT-Large에 비해 비교적 안정된 결과를 보여주고 있습니다.
Factorized Embedding Parameterize, Cross-Layer Parameter Sharing 개별적으로는 BERT학습 전략보다 낮은 성능을 보여주었습니다. 하지만 위의 최종 결과에서 BERT의 경우 Hidden size를 2048로 학습한 경우, 학습이 잘 이루어지지 않았는데, ALBERT는 위의 전략들의 효과로 얻은 적은 파라메터 + 안정화를 적극 이용, 4098의 Hidden size(ALBERT-xxLarge)도 성공적으로 학습을 진행할 수 있었습니다. (각 전략들의 시너지를 적극적으로 활용했기 때문에 얻을 수 있었던 결과라고 생각합니다.)
5.3 Sentence Order Prediction(SOP)

Sentence Order Prediction(SOP)의 효과를 검증하기 위해 1) 보조 테스크 없음(RoBERTa, XLNet 설정), 2) NSP(BERT 설정), 3) SOP 3가지 실험을 진행했습니다. 각 설정에 대해 MLM, NSP, SOP 성능을 측정하였습니다. 1)의 경우, 보조의 loss(Auxiliary loss)가 없으므로, NSP, SOP 둘 다 랜덤 선택에 비슷한 결과를 보여줍니다. 2)의 경우 NSP의 성능은 높지만 본 논문에서 지적했듯이, 토픽에 의존해 구분할 확률이 높으므로 SOP은 1)보다 낮은 성능을 보여줍니다.(풀지 못함, random으로 찍는 수준임), 3)의 경우 SOP뿐만 아니라, NSP에서도 (NSP를 objective로 학습하지 않았음에도 불구하고) 준수한 성능을 보여줍니다. 또한 두 개이상의 segment를 포함하는 pair단위의 downstream task들(SQuAD, MNLI, RACE)에서 다른 실험들에 비해 좋은 성능을 보여주었습니다.
5.4 Additional Training Data and Dropout Effects
최신의 연구들(XLNet, RoBERTa)은 pre-training에서 추가적인 데이터의 이용이 downstream-task에서 큰 성능 향상을 이끌어낼 수 있다는 것을 증명했습니다. 저자들은 이와 동일한 설정으로 ALBERT 학습을 진행했습니다.

SQuAD를 제외한 모든 테스크에서 성능향상이 있었는데, SQuAD는 wikipedia 기반의 데이터이기 때문에 외부의 데이터가 부정적인 효과를 주었기 때문입니다.
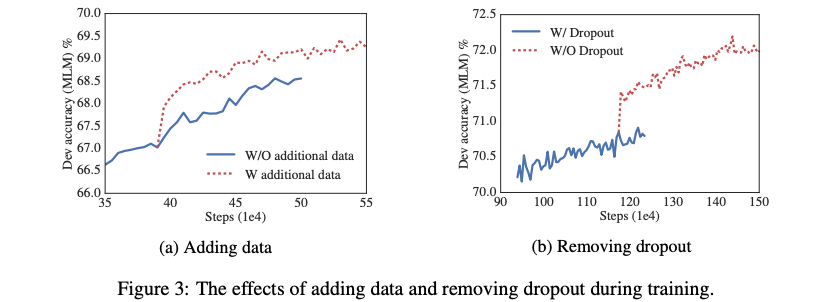

저자들은 ALBERT-xxLarge가 1M step이후에도 overfitting되지 않았기 때문에, 모델의 능력을 조금이라도 더 향상시키기 위해 dropout을 제거했습니다. 위 그래프와 같이 Dropout을 제거함으로써, MLM성능이 크게 향상되었고, Downstream task에서도 성능향상을 보였습니다.
Review
BERT 기반으로 NLP가 엄청난 발전을 하고 있는데, 최근에 BERT를 능가했던 방법들 중 XLNet이후로 가장 신선했던 접근법이었던 것 같습니다. 앞으로도 Langauge modeling 및 Auxiliary objective 에 대해 조금 더 다양한 시도들이 이루어지지 않을까 라는 생각이 들었습니다. BERT가 세상에 등장한지 1주년이 지났는데, 앞으로는 생각보다 훨씬 빠르게 발전할 것 같다는 느낌을 받았습니다. 한편으로는 이정도 규모의 연구는 점점 TPU가 없으면 시도조차 할 수 없는 것 같아서 경량화 기법 및 학습 속도에 관한 연구도 지속적으로 이루어질 것 같습니다.
Reference
-
ALBERT: A Lite BERT For Self-Supervised Learning of Language Representations, 2019.
-
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc VLe. XLNet: Generalized autoregressive pretraining for language understanding. arXiv, 2019.
-
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv, 2019
-
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. SpanBERT: Improving pre-training by representing and predicting spans. arXiv, 2019.
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep idirectional transformers for language understanding. In Proceedings of the 2019 Conference of he North American Chapter of the Association for Computational Linguistics(NAACL), 2018.
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems(NeurIPS), 2017.