
이번 글에서는 “Multi-Task Deep Neural Networks for Natural Language Understanding”(GLUE 밴치마크 87.6/6등)를 리뷰하려고 합니다. Microsoft Research에서 연구 되었고, 본 논문에서는 BERT구조 기반의 인코더와 Multitask-learning을 동시에 적용하는 방법을 시도했습니다. 결과적으로 Multitask-learning을 통해 서로 다른 테스크를 동시에 optimize 함으로써 언어의 지식을 공유할 수 있다는 것을 증명했습니다.
Main Idea
- BERT Encoder와 다양한 NLU 테스크들의 multi-task learning을 동시에 적용해 BERT를 능가하는 Multi-Task Deep Neural Network(MT-DNN)를 제시합니다.
- 특정 Downstream 테스크(NLI 테스크)에 대해 Fine-tuning에서 단순 Linear layer대신 다른 구조(Stochastic Answer Network)를 이용하여 향상된 성능을 보였습니다.
- Domain adaptation 실험을 통해 이 방식이 더욱 더 general representation을 만들 수 있음을 증명합니다.
- QNLI를 Binary Classification이 아닌 Relevance Ranking으로 학습함으로써 더 좋은 결과를 얻을 수 있음을 보였습니다.
MT-DNN
1. Task
Multi-task learning을 위해서는 먼저 어떤 테스크들을 동시에 학습할지 결정해야합니다. 본 논문에서는 NLU(Natural Language Understading)의 대표적인 벤치마크인 GLUE에 있는 테스크들을 이용하여 실험을 진행하였습니다. 다음과 같이 NLU 테스크들을 4가지로 구분하였습니다. (각 분류별로 fine-tuning layer 구조가 달라지기 때문에 구분하였습니다.)
-
Single-Sentence Classification: 말 그대로, 주어진 (하나의) 문장에 대해 사전에 정의된 레이블 중 하나로 예측하는 분류문제를 풉니다. GLUE에서는 주어진 영어 문장이 문법적으로 타당한지 예측하는 CoLA, 주어진 영화 리뷰가 긍정/부정인지 sentiment를 예측하는 SST-2가 이 분류에 속합니다.
-
Text Similarity: 주어진 문장쌍이 의미적으로 얼마나 유사한지(Regression 문제) 예측합니다. GLUE에서는 STS-B가 이 분류에 속합니다.
-
Pairwise Text Classification: 주어진 문장쌍의 관계를 사전에 정의된 레이블 중 하나로 예측하는 분류문제를 풉니다. GLUE에서는 RTE, MNLI, QQP, MRPC가 이 분류에 속합니다. MNLI, RTE는 주어진 문장쌍에 대해 {entailment/contradiction/neutral} 중 하나의 관계를 예측하는 Natural Language Inference(NLI)테스크입니다. QQP, MRPC는 페러프레이징 데이터셋으로, 주어진 문장쌍이 의미적으로 동일한 문장인지 예측하는 테스크입니다.
-
Relevance Ranking: 주어진 쿼리와 정답이 될 수 있는 후보군들 중 쿼리와 관계있는 순으로 랭킹을 메기는 테스크입니다. GLUE에서는 QNLI가 이 분류에 속합니다. 원래 QNLI는 주어진 질문에 대해 답변이 정답을 포함하고 있는지 예측하는 binary classification 문제입니다. 하지만 본 논문에서는 이를 pairwier ranking 테스크로 변환하여 품으로써, 정답을 포함한 답변이 다른 답변에 비해 상대적으로 더 높은 확률을 갖도록(랭킹을 메길 수 있도록) 학습했고, 더 좋은 성능을 보였습니다.
2. Model
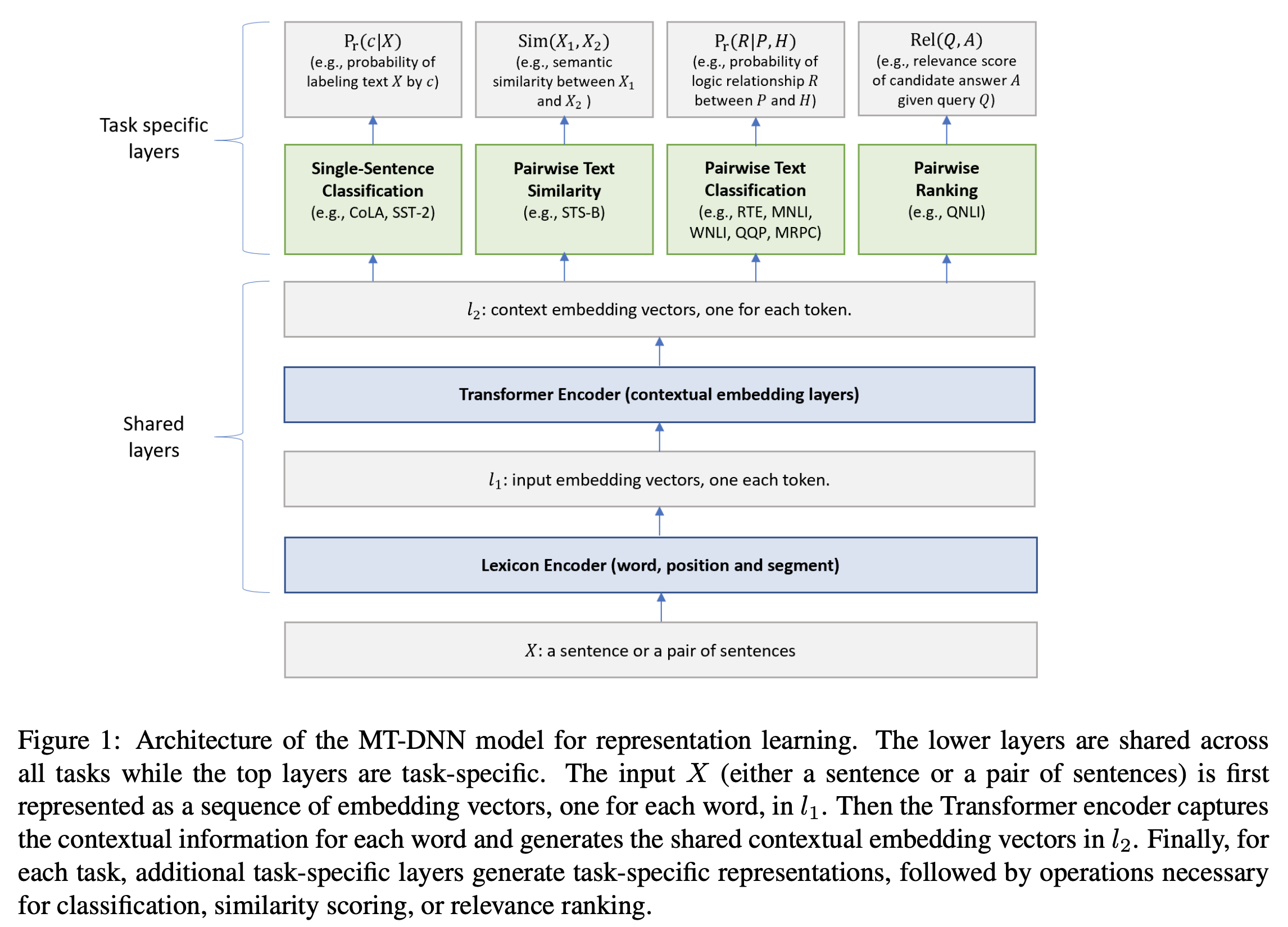
Multi-task learning을 위한 모델 구조는 위 그림과 같습니다. 공통된 Transformer Encoder(그림의 shared layers)와 위의 테스크 분류에 따른 각 테스크별 fine-tuning layer(그림의 task specific layers)를 갖습니다. 모델의 각 구성요소 별 설명은 다음과 같습니다.
2.1 Shared Layers
Shared Layer는 각 문장의 representation을 만드는 부분으로 모든 구성은 BERT와 동일한 설정을 유지합니다. 위 그림에서 Shared layer의 각 요소는 다음과 같습니다.
- 입력(\(X\)): 입력 \(X = {x_1,...x_m}\)는 m개의 토큰의 sequence로 구성됩니다. BERT의 설정과 같이 항상 첫번 째 토큰은 분류문제를 위한
[CLS]를 이용하고, 문장쌍(\(X_1, X_2\))에 대한 테스크인 경우 각 문장을[SEP]토큰으로 분리합니다. - Lexicon Encoder: BERT의 임베딩 레이어와 동일한 역할로, X를 입력으로 받아 각 토큰의 단어, 포지션, 세그멘트 임베딩값을 더해 최종 임베딩값을 만듭니다. 토큰 당 단어, 포지션, 세그멘트에 따라 고정된(static) 임베딩값을 갖습니다.
- Transformer Encoder: Multi-layer Bidirectional Trnasformer Encoder로 Lexcon Encoder를 거쳐 형성된 임베딩(static)을 여러 층의 Self-attention을 통해 주변 문맥을 고려한 Contextual 임베딩으로 만드는 역할을 합니다.
2.2 Task Specific Layers
위에서 정의했던 테스크에 따라 task specific layer를 정의합니다. 본 논문에서는 GLUE에 속하는 테스크만을 대상으로 실험을 진행했지만, 실제로는 어떤 임의의 NLP테스크(심지어 generation)도 대상이 될 수 있습니다.
- Single Sentence Classification Output: BERT에서 downstream 분류 문제를 fine-tuning하는 방법과 동일하게 진행합니다. 해당 입력의 의미 전체를 내포하는(분류 문제를 위한)
[CLS]토큰의 representation을 linear classifier와 softmax를 거쳐 사전에 정의된 클래스들의 확률 분포로 나타냅니다.
- Text Similarity Output: BERT에서 downstream regression 문제를 fine-tuning하는 방법과 동일하게 진행합니다.
[CLS]토큰의 representation을 linear layer를 거쳐 하나의 점수(유사도)로 나타냅니다. (하나의 점수이므로 \(W_{Task} \in \mathbb{R}^{D_{hidden} \times 1}\))
-
Pairwise Text Classification Output: Pairwise 분류 문제들(MNLI, RTE, QQP, MRPC)은 주어진 문장쌍의 관계를 예측하는 문제를 풉니다. 본 논문에서는 BERT(linear layer + softmax)와 다르게 Stochastic Answer Network(Liu et al., 2018a)를 이용했습니다. 이는 NLI의 기존 SOTA 모듈로,주어진 문장들에 대한 Multi-step Reasoning을 모델링하는 구조입니다. NLI 테스크를 예시로 SAN 구조를 파악해보겠습니다.
SAN은 GRU(RNN 계열) 모듈에 주어진 문장쌍의 representation을 input 및 hidden state으로 넣는 과정을 K번 반복(K-step reasoning)함으로써 정제된 representation을 얻고, 이를 이용하여 최종 예측을 진행합니다.
- NLI 테스크는 입력으로 문장 쌍(H: Hypothesis {\(h_1, ... h_n\)}, P: Premise {\(p_1, ... p_m\)})을 받습니다. 이를
[CLS]+ H +[SEP]+ P +[SEP]와 같은 형식으로 만들고 transformer encoder로 인코딩하면 Contextual 임베딩을 얻을 수 있습니다. - \(H\)와\(P\) 각각에 속하는 토큰들의 Contextual 임베딩을 모으면 \(M^h \in \mathbb{R}^{d \times n}\)와 \(M^p \in \mathbb{R}^{d \times m}\)를 얻을 수 있습니다.
- \(M^h\)를 이용하여 GRU의 초기 hidden state(\(s_0\))를 만들고 \(M^p\)를 이용하여 GRU의 t번째 input (\(x_t\))을 만듭니다.
- \(s_0\) 만들기: \(M^h\)(\(H\)의 각 토큰 represention)을 가중합(self-attention으로 볼 수도 있음)하여 \(s_0 \in \mathbb{R}^{1 \times d}\)을 만듭니다.(즉 \(H\)를 대표할 수 있는 representation을 만듭니다.) \(\alpha_j = \frac{exp(w_1^T \cdot M_j^h)} {\sum_i exp(w_1^T \cdot M_i^h)}\), (\(w_1 \in \mathbb{R}^{D_{hidden} \times 1}\)) 와 같이 \(w_1\)을 이용해 각 토큰 representation을 1차원으로 줄이고 softmax를 통해 각 토큰 별 상대적인 가중치를 만듭니다. \(s_0 = \sum_j \alpha_j M_j^h\) 와 같이 이 가중치로 각 토큰 representation을 가중합합니다.
- t번째 input(\(x_t\)) 만들기: \(M^p\) 와 GRU의 t-1번째 hidden state(\(s^{t-1}\))를 이용하여 t번째 input을 만듭니다. \(\beta_j = softmax(s^{k-1}W^T_2M^p)\), \(x^t = \sum_j \beta_j M^p_j\)와 같이 이전 hidden state(\(s^{t-1}\))와 premise의 토큰 representation(\(M^p\))을 고려한 가중치 \(\beta\)가 만들어지고 이에 따른 가중합으로 input(\(x^t\))가 만들어집니다.
- 초기 hidden state(\(s_0\))와 입력(\(x_1\))을 이용해 사전에 정의된 K-step만큼 \(s_t = GRU(s_{t-1}, x_t)\) 연산을 진행합니다.
- \(P_r^t = softmax(W_3^T[s^t;x^t; \mid s^t - x^t \mid ; s^t \cdot x^t])\) 와 같이 각 step을 진행할때마다 linear classifier를 거쳐 각 클래스에 대한 확률 분포를 계산합니다.
- \(P_r = avg([P_r^0, P_r^1, ... P_r^{K-1}])\)과 같이 모든 K-step output을 평균하여 클래스에 대한 최종 확률 분포를 계산합니다. averaging 연산을 진행하기 전에 stochastic prediction dropout(Liu et al., 2018b)를 적용했습니다.
- NLI 테스크는 입력으로 문장 쌍(H: Hypothesis {\(h_1, ... h_n\)}, P: Premise {\(p_1, ... p_m\)})을 받습니다. 이를
-
Relevance Ranking Output: 주어진 Query(\(Q\))와 Answer(\(A\))를 함께 입력하여 계산된
[CLS]토큰의 representation을 이용하여 relevance score를 계산합니다. 이는 Q,A간의 관계를 상대적으로 나타내는 점수로, 후보군들 중 정답이 가장 높은 점수를 얻도록 학습합니다.
3. Training
3.1. objective
- Classification Objective: Single sentence classifiaction, Pairwise Classification등 분류문제에 대해서는 cross-entropy를 사용합니다.
- Regeression Objective: Text similarity 등 regression 테스크에 대해서는 Mean-squared error를 사용합니다.
-
Relevance Ranking Objective: QNLI와 같은 Relevance ranking 테스크에서는 후보군들 중 정답을 맞추는 방식의 objective를 이용합니다. 특정 쿼리 Q에 대해 후보 답변셋 \(A = A^+ \cup A^-\) (\(A^+\): 정답, \(A^-\): negative sample)을 만듭니다.
\(- \sum _{Q, A^+} \log{Pr(A^+ \mid Q)}\), \(Pr(A^+ \mid Q) = \frac{exp(\gamma Rel(Q, A^+))}{\sum_{A' \in A}exp(\gamma Rel(Q, A'))}\)
그리고 위 식과 같이 다른 후보들에 비해 정답이 가장 큰 확률을 갖도록 정답 확률의 negative log likelihood를 최소화하는 방향으로 학습합니다. (\(\gamma\)는 튜닝할수 있는 요소 이며 데이터에 따라 결정됩니다. 본 논문에서는 1을 이용했습니다.)
3.2. Training Procedure
전체 학습단계는 다음과 같이 총 3단계로 구성됩니다.
- BERT와 같은 전략(Masked-LM, Next Sentence Prediction)으로 Pre-training을 진행합니다.
- Multi-task Learning으로 GLUE의 모든 테스크를 동시에 fine-tuning 합니다.
- 특정 task로 다시 한 번 fine-tuning을 진행합니다.
2번과정을 조금 더 자세하게 살펴보면 다음과 같습니다.
- 모든 테스크에 대해 각각 미니배치로 구성된 데이터셋을 만듭니다.
- 모든 테스크의 데이터셋들을 하나로 합치고 섞습니다. 즉 하나의 배치는 하나의 테스크에 대한 input으로만 구성됩니다.
- 2번에서 만들어진 데이터셋을 돌면서 각 배치별로 해당 테스크의 fine-tuning layer 및 objective를 이용하여 optimize를 진행합니다.
3.3 Implementation Details
- Optimizer: Adamax
- learning rate: 5e-5 (전체 step의 0.1까지 linear warmup후 decay)
- epoch: 5
- fine-tuning layer dropout: 테스크 마다 다르게 설정(MNLI:0.3, CoLA:0.05, 나머지는 0.1)
- tokenizer: WordPiece
Experiment Results
1. GLUE
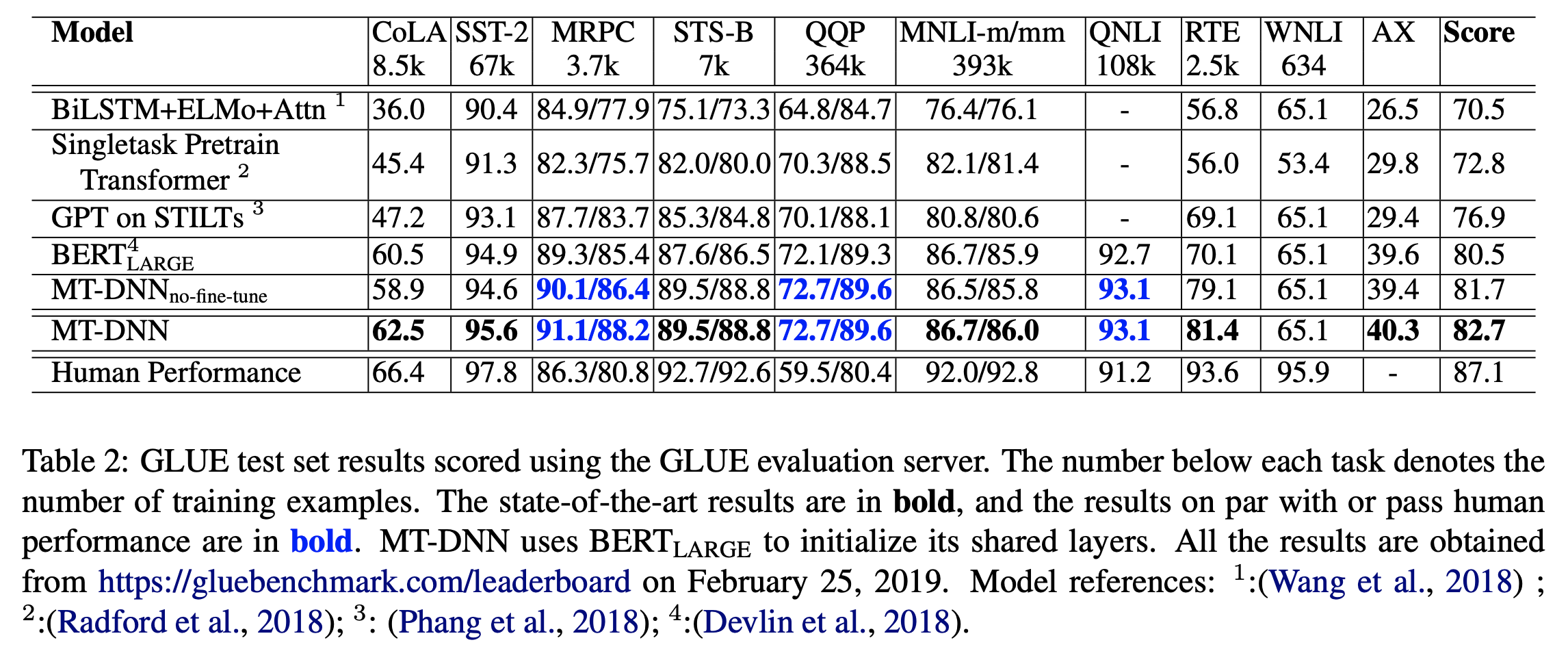
GLUE 밴치마크의 결과는 위의 그림과 같습니다. \(MT-DNN_{no-fine-tune}\) 은 위의 학습 과정에서 3번을 진행하지 않고 2번의 결과모델을 이용하여 성능평가를 진행한 것입니다. 결과적으로 3번과정까지 모두 진행한 MT-DNN은 WNLI를 제외한 모든 테스크에서 \(BERT_{Large}\)를 능가하는 성능을 보여주었습니다. 1번과정까지 \(BERT_{Large}\)와 동일한 설정이기 때문에, 이 성능 향상은 Multi-task Learning의 효과로 볼 수 있습니다.
이 학습법은 STS-B, MRPC, RTE와 같이 학습데이터가 적은 테스크에 대해 더 큰 성능 향상을 보였습니다. 특히 NLI - RTE(적은 양) vs MNLI(많은 양), paraphrase - MRPC(적은 양) vs QQP(많은 양) 와 같이 같은 분류의 테스크가 존재하고 해당 분류의 데이터가 많은 경우 더 큰 성능향상이 있었습니다.즉, 같은 분류이면서 많은 양의 데이터가 있는 테스크의 영향을 받았다고 볼 수 있습니다.
그리고 \(MT-DNN_{no-fine-tune}\)의 경우에도 CoLA를 제외한 나머지 테스크들에서 기존의 BERT를 능가하는 성능을 보여주었습니다. 이는 CoLA와 유사한 다른 테스크가 없을 뿐더러(다른 테스크로부터 배울 수 있는 지식이 적음) 데이터의 양이 너무 적기 때문입니다. 하지만 이경우에도 3번과정을 거쳐 CoLA데이터로만 한번 더 fine-tuning을 진행하게 되면 BERT의 성능을 뛰어넘게 되는데, 저자들은 이러한 점에서도 Multi-task learning이 domain adaptaion 능력을 높여준다고 주장합니다.
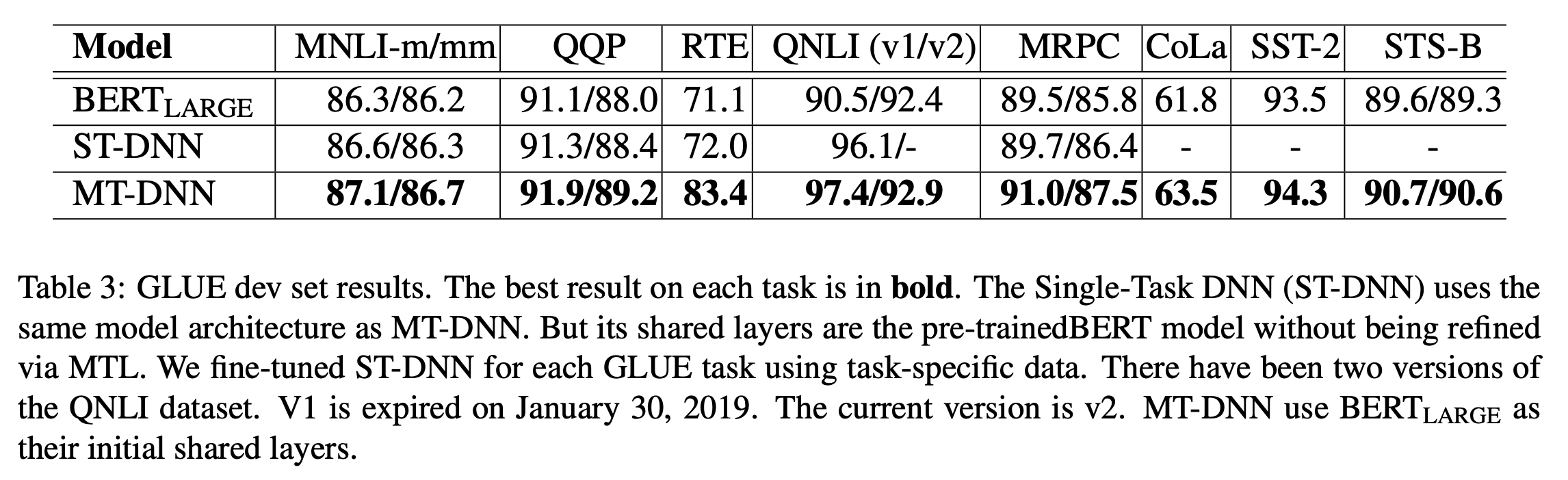
본 논문에서 BERT와 다른 또 하나의 차이점으로 제안하는 것은 문장쌍 단위의 테스크(MNLI, RTE, QQP, MRPC)에서 Fine-tuning layer로 SAN을 사용하는 것입니다. 이를 위해 Single task learning + SAN의 설정으로 해당 테스크들을 학습했습니다. 위 그림과 같이 모든 테스크에서 BERT에 비해 좋은 성능을 보이고 있습니다. 따라서 문장쌍 단위의 테스크에서 SAN구조가 조금 더 효과적이라는 것이 증명되었습니다.
또한 Single task learning + Relevance Ranking 설정으로 QNLI 테스크 학습을 진행했습니다. 위 그림과 같이 큰 성능향상이 있었기 때문에 분류 문제가 아닌 랭킹 문제로 접근하는 것이 해당 테스크에서 조금 더 효과적이라는 결론을 얻을 수 있었습니다.
2. Domain Adaptation
저자들은 MT-DNN의 Domain adaptation 능력을 검증하기 위해 SNLI와 SciTail 테스크에 대한 추가적인 실험을 진행했습니다. 저자들은 GLUE로 학습된 MT-DNN과 BERT를 비교하였으며 각 테스크의 학습셋중 일부만 이용하여 학습을 한 후 성능을 측정했습니다. 즉 적은양의 데이터로도 얼마나 좋은 성능을 낼 수 있는지(Domain adaptation 능력)를 비교했습니다.
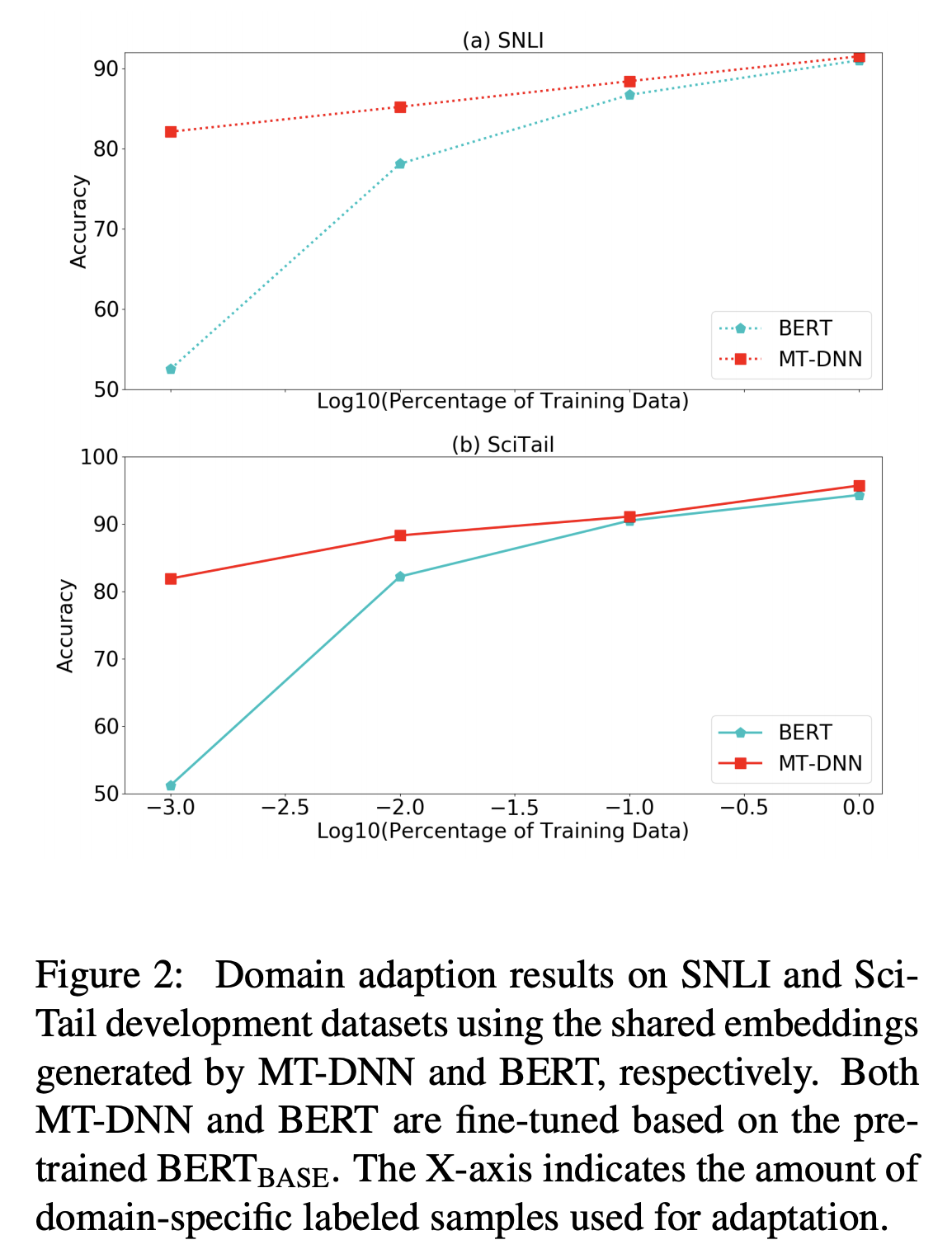
결과적으로 위 그림과 같이 적은 양의 데이터를 이용했을 때, 두 테스크 모두 MT-DNN이 더 뛰어난 성능을 보였습니다. 따라서 MT-DNN이 domain adaptaion에 있어서 조금 더 효과적인 방법으로 볼 수 있습니다.
Reference
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep idirectional transformers for language understanding. In Proceedings of the 2019 Conference of he North American Chapter of the Association for Computational Linguistics(NAACL), 2018.
-
Xiaodong Liu, Kevin Duh, and Jianfeng Gao. 2018a. Stochastic answer networks for natural language inference. arXiv, 2018.