
“Emotion Recognition in Conversation(ERC)”는 대화 내 발화들의 감정을 인식하는 문제입니다. 이 문제는 대화의 히스토리 혹은 쓰레드 형태의 소셜 미디어(유투브, 트위터, 페이스북 등)에서 의견 추출(Opinion mining) 등에서 응용가능성으로 인해, 최근에 많이 주목받고 있습니다. 본 포스트에서는 “화자”, “컨텍스트 발화”, “이전 발화의 감정”의 3가지 요소를 집중적으로 모델링하여 ERC문제를 풀고자 했던 “DialogueRNN: An Attentive RNN for Emotion Detection in Conversations”를 리뷰합니다.
Main Idea
대화는 두 명이상의 화자의 상호작용으로 이루어집니다. 본 논문에서는 각 ERC문제를 풀기위해 대화에 참여하고 있는 화자들의 상태를 각각 모델링함으로써, 성능을 개선하고자 했습니다. 저자들은 화자, 대화의 컨텍스트, 이전 발화의 감정이 대화에서의 감정과 가장 연관성이 높다고 가정하고, 이를 각각의 RNN(Recurrent Neural Network) 모듈로 모델링했습니다.
Problem Definition
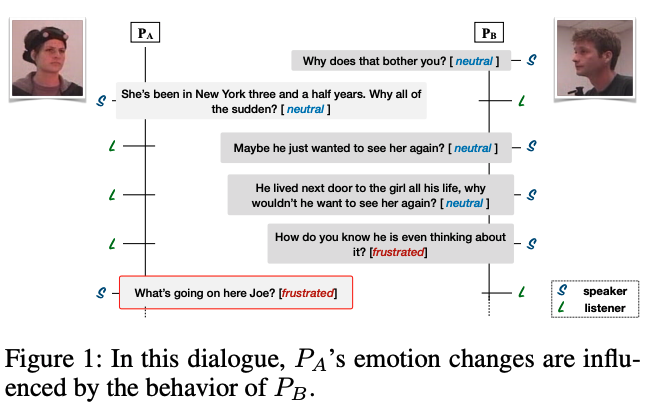
위의 그림과 같이, 대화에서 \(M\) 명의 화자(party)들 \(p_1, p_2, ... p_M\)이 있을 때, 각 화자들의 발화에 대해 6개의 감정 레이블(happy, sad, neutral, angry, excited, frustrated) 중 하나로 분류하는 문제를 풉니다.
Dialogue RNN
1. Unimodal Feature Extraction
본 논문이 이용했던 데이터셋은 대화에서 Textual(T), Visaul(V), Audio(A)의 3가지 정보를 제공합니다.(Multi-modal)
각 modal에 대해 이전의 State-of-the-art모델이였던 conversation memory networks(CMN)에서 사용했던 feature extraction 과정을 그대로 수행했습니다.
1.1 Textual Feature Extraction
텍스트의 feature extraction을 위해 CNN(Convolutional Neural Network)를 이용했습니다. 일반적인 char-CNN의 방법과 동일하게, 각 발화를 n-gram의 컨벌루션 필터를 이용하여 100차원의 벡터로 만들었습니다. 3,4,5 필터 사이즈 각각 50개의 피쳐맵을 갖도록 했고, 각 필터의 결과물은 Max pooling을 이용하여 하나의 벡터로 나타내어 집니다. 이 결과, 각 필터 사이즈 마다 50개의 피쳐가 만들어집니다.(총 150개) ReLU + Dense layer를 이용하여 이를 100차원의 벡터로 만듭니다.
1.2 Audio and Visual Feature Extraction
CMN과 동일하게 3D-CNN(Visual), openSMILE(Audio)을 이용하여, feature extraction을 진행하였습니다.
2. Model
대화 속 발화의 감정에는 아래의 3가지 요소가 중요한 역할을 한다고 가정하고, 이를 모델링 했습니다.
- 화자
- 이전 발화들에 의해 주어지는 대화 컨텍스트
- 이전 발화들의 Emotion
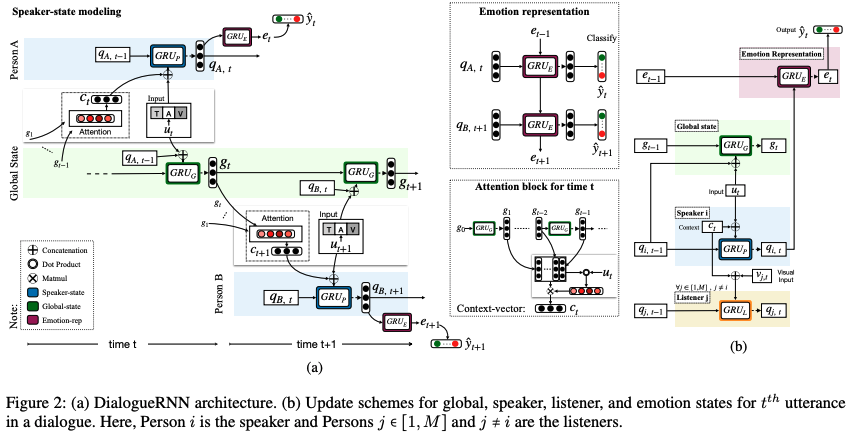
전체 구조는 위의 그림과 같이 구성됩니다. 화자를 모델링 하기 위해 특정 화자가 발화를 했을 때마다 업데이트 되는 party(화자들의) state(\(q_{i,t}\)), 전체 발화들의 컨텍스트를 담고 있는 global state(\(g_t\)), 발화들의 Emotion 정보를 담고 있는 Emotion representation(\(e_t\)), 이들을 동시에 업데이트 해가면서 최종적으로 Emotion representation을 이용해 특정 발화의 감정을 예측합니다. 각 상태들(\(q_{i,t}, g_t, e_t\))을 모델링하기 위해서 GRU(Gated Reccurent Unit)이 이용되었습니다.
2.1 Global State(Global GRU)
Global State는 Unimodal Feature Extraction에서 만들어진 특정 시점 \(t\) 발화의 feature(\(u_t\))와 해당 발화를 한 화자의 이전 party state(\(q_{s(u_t),t-1}\))를 이용해, 주어진 발화의 컨텍스트를 모델링합니다.
\[g_t = GRU_G(g_{t-1}, (u_t \oplus q_{s(u_t),t-1}))\]여기서 \(s(u_t)\) 는 \(u_t\)를 해당 발화를 말한 화자로 메핑하는 함수입니다.
입력으로 이전 step의 party state(\(q\))를 받기 때문에, 화자-specific한 발화 representation을 인코딩하는 것, 화자간, 발화간 의존성을 잘 모델링하여 향상된 컨텍스트 representation을 만드는 것을 기대할 수 있습니다.
2.2 Party State(Party GRU)
Party State는 대화에 참여하는 각 화자들의 상태를 모델링합니다. 각 상태는 Null 벡터로 초기화 되고, 대화가 진행됨에 따라 업데이트 됩니다. 현재 time step에서 화자의 역할에 따라 각 상태를 업데이트 하고자 합니다. 본 모듈의 목적은 모델이 각 화자를 인식하고, 이를 적절하게 이용하게 하는 것입니다.
하나의 발화가 추가되었을 때, 해당 발화를 말한 화자(Speaker)와 나머지 청자들(Listener)의 상태를 독립적으로 업데이트 했으며 방식은 다음과 같습니다.
Speaker Update(Speaker GRU): 대화에서 화자는 주로 이전 발화들(컨텍스트)에 기반해 답변을 합니다. 따라서 다음과 같이 Global State와의 Attention 연산을 통해 현재 발화의 feature와 가장 관계있는 컨텍스트 representation(\(c_t\))를 만듭니다.
\[\alpha = softmax(u_t^TW_{\alpha}[g_1,g_2,...g_{t-1}])\] \[c_t = \alpha[g_2,g_2,...,g_t]^T\]이렇게 만들어진 컨텍스트 representation(\(c_t\))과 현재 발화의 feature(\(u_t\))를 이용하여 현재 시점의 화자의 상태\(q_{s(u_t), t}\)를 업데이트 합니다.
\[q_{s(u_t), t} = GRU_P(q_{s(u_t), t-1}, (u_t \oplus c_t))\]Listener Update: 화자가 발화를 함에 따라 다른 청자들의 상태가 어떻게 업데이트 할지를 모델링합니다. 본 논문에서는 두 가지 방법을 시도했습니다.
- 모든 청자들의 상태를 이전과 동일하게 유지합니다. 즉, 특정 발화가 추가 되었을 때, 해당 발화를 말한 화자의 상태만 업데이트 되고, 나머지 화자들의 상태는 유지됩니다.
- 또다른 GRU(\(GRU_L\))를 이용해 청자들의 상태를 모델링합니다. 이 때, visaul cue들을 이용합니다. 이 feature는 7차원의 벡터로 FER2013데이터를 이용해 pretrain된 모델을 이용합니다.
2.3 Emotion Representation(Emotion GRU)
특정 시점 \(t\)에서 발화와 감정적으로 관련있는 representation(\(e_t\))를 모델링합니다. 해당 발화를 한 화자의 상태(\(q_{s(u_t), t}\))와 이전 발화의 감정 representation(\(e_{t-1}\))을 이용합니다. \(e_{t - 1}\)는 감정과 관련된 이전 컨텍스트에 대한 정보와, 또 다른 화자의 상태(\(q_{s(u_{< t}), < t}\))에 대한 정보를 함께 제공할 수 있습니다.
\[e_t = GRU_E(e_{t-1}, q_{s_(u_t), t})\]Speaker update에서 화자의 상태를 업데이트 할 때, Global state를 참조하기 때문에 \(q_{s(u_t), t}\)에 이미 다른 화자들의 상태에 대한 정보가 제공되었다고 볼 수도 있지만, emotion GRU를 사용함으로써 이전 화자들의 상태를 직접적으로 연결하는 것이 조금 더 효과적입니다.(Ablation study에서 증명합니다.)
또한 저자들은 \(GRU_P, GUR_G\)는 각각 화자, 컨텍스트에 대한 정보를 인코딩하는 인코더 역할을, \(GRU_E\)는 이를 이용하여 감정적인 요소를 해석하는 디코더 역할을 할 것이라고 기대했습니다.
2.3. DialogueRNN Variants
- DialogueRNN + Listner State Update(\(DialogueRNN_l\)): 위의 Listener Update에서 두 번째 방법을 이용하여 각 화자 state를 업데이트 하는 모델.
- Bidirectional DialogueRNN (\(BiDialogueRNN\)): Emotion GRU를 Bidirectional로 이용한 모델. 따라서 최종 emotion representation은 미래의 발화와 이전 발화들의 정보를 모두 갖고 있음.
- DialogueRNN + attention (\(DialogueRNN + Att\)): Emotion GRU를 통해 계산된 \(e_t\)와 이전 감정 state들(\(e_1, ...e_N\))을 이용하여 attention 연산을 통해 최종 state(\(\tilde e\))를 만든 모델. 이 방법또한 미래의 발화(\(e_{t + 1} ~ e_N\))들에 대한 정보를 볼 수 있음
- Bidirectional DialogueRNN + Emotional attention (\(BiDialogueRNN+Att\)): Emotion GRU를 Bidireactional로 하고, Attention 연산을 통해 최종 emotion representation을 만드는 모델.
Experiment Setting
1. Dataset
IEMOCAP, AVEC 2개의 데이터셋을 이용했습니다.
- IEMOCAP: 10명의 화자들이 진행한 대화에 대한 비디오를 포함합니다. 각 비디오는 양자간의 대화이며, 발화 단위로 나뉘어 있습니다. 각 발화는 6개의 감정 레이블(happy, sad, neutral, angry, excited, frustrated)이 분류되어 있습니다.
- AVEC: 사람과 인공지능 에이저트의 대화로 이루어진 데이터셋입니다. 각 발화는 4개의 attribute(valence, arousal, expectancy, power)에 대해 실수의 점수를 갖고 있습니다. anntation은 0.2초에 하나씩 이용할 수 있지만, 발화 단위로 평균해서 이용했습니다.
2. Modality
본 논문에서는 주로 textual modality에 집중했지만, Multi-modal환경에서 우수성을 입증하기 위해 해당 feature들을 이용했습니다.
Results and Discussion
1. Comparison with SOTA
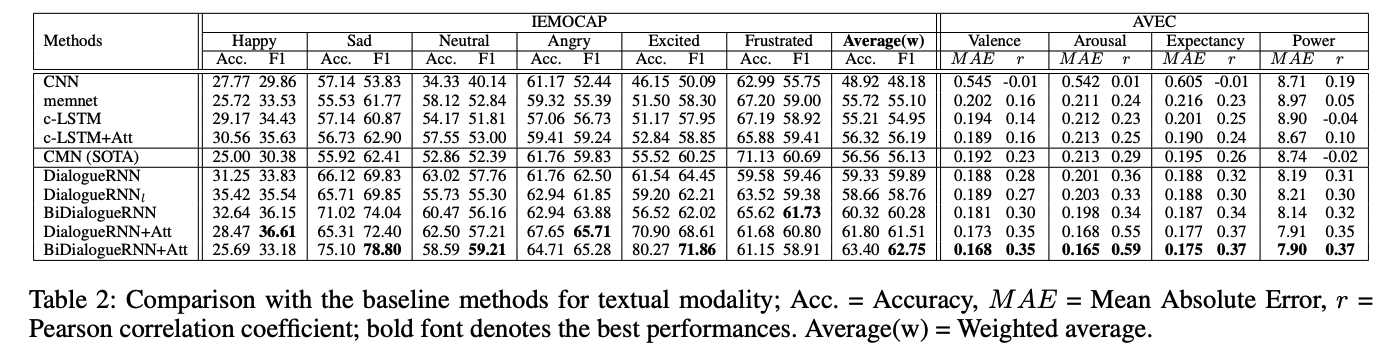
IEMOCAP: 위 결과와 같이 이전 SOTA모델(CMN)을 크게 뛰어넘는 결과를 보여주었습니다. CMN과의 차이점은 다음과 같습니다.
- party state 모델링(\(GRU_P\))
- 화자-specific한 발화의 표현(global state를 이용해 화자의 발화 모델링)
- global state 모델링(\(GRU_G\))
기본 DialogueRNN이 Frustrated감정을 제외한 모든 감정에서 CMN을 능가했고, 다른 Varients들에서는 Frustrated 또한 CMN을 능가함을 볼 수 있습니다.
AVEC: 위 그림과 같이, valence, arousal, expectancy, power의 모든 attribute에 대해 Mean Absolute Error(MAE)가 낮고, Pearson correlation coefficient가 높음을 볼 수 있습니다.
2. Varients
\(DialogueRNN_l\): 추가적인 청자의 상태를 업데이트 하는 방법은 약간의 성능 하락을 보였습니다.(IEMOCAP 결과) 따라서, 특정 화자가 말을 할 때에만 해당 화자의 상태와 연관이 있다고 추측할 수 있습니다. 또한 화자 상태를 업데이트 할 때 컨텍스트(\(c_t\))를 이용하는데, 이 때 다른 화자의 발화들 또한 포함되기 때문에 청자의 상태를 따로 업데이트할 필요가 없다고도 볼 수 있습니다.
\(BiDialogueRNN\): 미래의 발화에 대한 정보도 얻을 수 있기 때문에, 당연히 향상된 결과를 기대할 수 있고, 두 데이터셋에 대해 모두 향상된 결과를 보였습니다.
\(DialogueRNN + Att\): 이 방법도 미래의 발화에 대한 정보를 얻을 수 있습니다. 또한 Attention을 통해 감정적으로 중요한 컨텍스트 발화를 선택하여 이용할 수 있고, \(BiDialogueRNN\)에 비해 향상된 결과를 보였습니다.
\(BiDialogueRNN + Att\): 위의 두 방법을 동시에 적용한 것으로, 더 좋은 결과를 보였습니다.(결과적으로 두 데이터셋에 대해 가장 좋은 결과를 보였습니다.)
3. Multimodal Setting
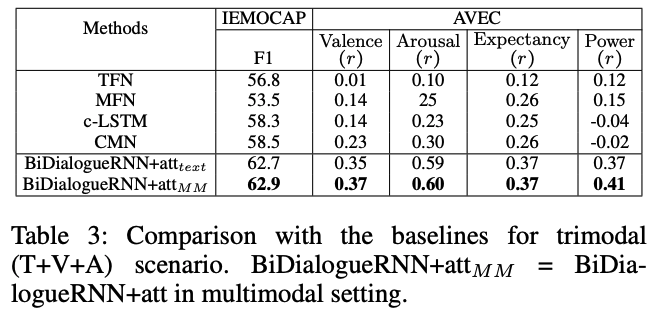
본 논문에서는 Multi-modal feature들을 잘 혼합시키는 것에 주목하지 않았기 때문에, 모든 feature들을 Concat하여 이용했고, 위 결과와 같이 text만 이용한 경우보다 조금 향상된 결과를 얻을 수 있었습니다.
4. Case Studies
Dependency on preceding utterances(DialogueRNN):\(GRU_P\)를 계산할 때, \(GRU_G\)의 state들에 대해 Attention 연산을 통해 \(c_t\)를 얻는데 이 때 \(\alpha\)값의 분포를 분석했습니다.(과거 발화에만 attend할 수 있습니다.)
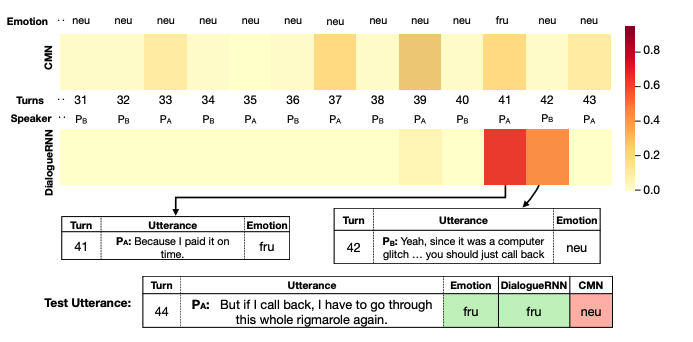
위 그림과 같이 CMN의 attention 분포에 비해 특정 발화에 “집중됨”을 볼 수 있습니다. 저자들은 이러한 경향들이 dialogueRNN에서 자주 발생함을 관찰했고, 이를 신뢰 지표로 해석할 수 있다고 주장합니다. (채리피킹일 수 있지만) 해당 예시에서는 neutral -> frustrated의 감정 변화를 정확한 근거(attention)에 따라 인지함을 볼 수 있습니다.
Dependency on future utterances(BiDialogueRNN + Att): \(\tilde e_t\)를 계산하기 위해 이용했던 \(\beta\)의 분포를 시각화하고, 이를 분석했습니다. (미래 발화에도 attend할 수 있습니다.)
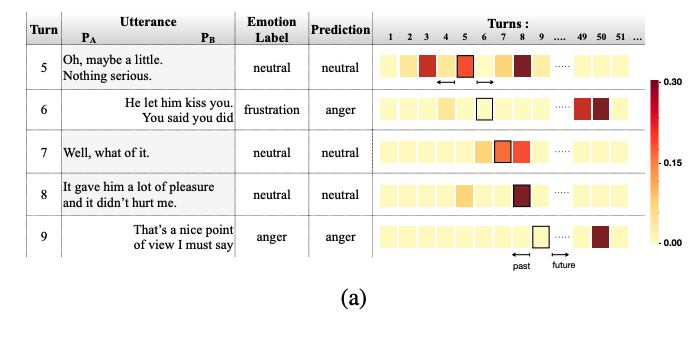
위 예시는 두 커플들 사이의 대화로, \(P_A\)는 여성 화자로 neutral 상태이고, \(P_B\)는 남성으로 화(angry)를 내고 있는 상태입니다. attention 분포에서 알 수 있듯이 여성의 감정은 여성의 neutral state의 기간에 지역화되어 있습니다. (5,7,8 발화는 8을 강하게 attend함.) 또한 미래와 과거의 발화를 동시에 attend하기도 합니다.(5번턴은 3,8을 attend함.) 6,9번의 경우를 통해 미래 발화의 고려가 유의미함도 볼 수 있습니다.
Dependency on distant context: IEMOCAP의 테스트셋에서 정답인 예측들에 대해 test utterance와 2번째로 높은 attention값을 가지는 발화 사이의 상대적인 거리를 시각화했습니다.
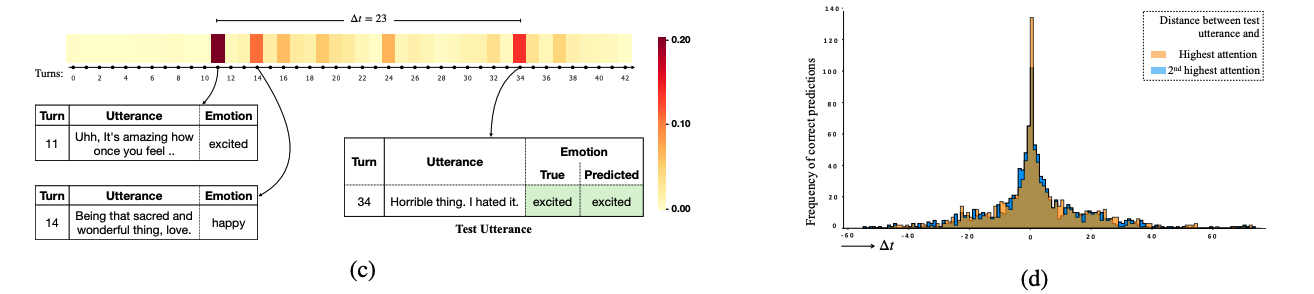
일반적으로 지역적인 컨텍스트에서 가장 높은 의존성을 보이고 거리에 따라 점점 감소하는 추세를 보입니다. 하지만 약 18%가 20~40턴에 attend하고 있어 장기 의존성은 여전히 중요한 역할을 하고 있습니다. 이러한 경우는 대화에서 감정적인 톤을 유지하고, 잦은 감정적 변화를 일으키지 않을 때 발생합니다. 위 그림의 왼쪽 예시는 장기 의존성의 케이스를 보여줍니다. “Horrible thing. I hate it”이라는 부정적인 표현임에도 불구하고, 전체 컨텍스트를 봤을 때, exciment에 해당합니다. 이 경우, 약 20턴 이전에 있는 발화에 적절히 attend하여 옳은 판단을 하는 모습을 볼 수 있습니다.