
이전 글에서 대화를 그래프 형태로 모델링 하고, 이를 이용하여 답변을 생성해내는 GSN을 리뷰 했었는데요, 이번 글에서는 Self-Attention을 이용해 Multi-turn 대화의 답변을 생성하는 방법론을 제시한 “ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation(ACL 2019)”를 리뷰하려고 합니다.
Main Idea
일반적인 대화에서는 이전의 모든 컨텍스트를 고려하기 보다는 일부 컨텍스트에 의존하여 답변합니다. 따라서 주어진 컨텍스트 중 적절한 컨텍스트를 고를 수 있는 능력은 매우 중요합니다.
Multi-turn 대화를 생성하기 위해 문장 인코딩과 컨텍스트 인코딩을 계층적으로 수행하고, 이를 이용하여 디코딩을 진행하는 HRED와 같은 방식이 가장 대표적으로 이용되었습니다. 이 구조에서는 컨텍스트 인코딩을 RNN기반 모듈로 진행하는데, RNN은 구조상 가장 가까운 컨텍스트에 bias가 있을 확률이 높습니다. 따라서 컨텍스트 중 가장 필요한 내용 보다는 마지막 발화에 의존하는 경향이 있습니다.
일반적으로 Self-Attention은 각 요소들 간에 직접적인 유사도를 이용하기 때문에, long-distance dependency를 조금 더 잘 모델링할 수 있다고 알려져 있습니다. 본 논문에서는 이를 이용하여 답변을 생성할 때, 어떤 컨텍스트에 집중할지(attend 할지)를 잘 모델링하는 방법론을 제시합니다.
Relevant Context Self-Attention Model(ReCoSa)
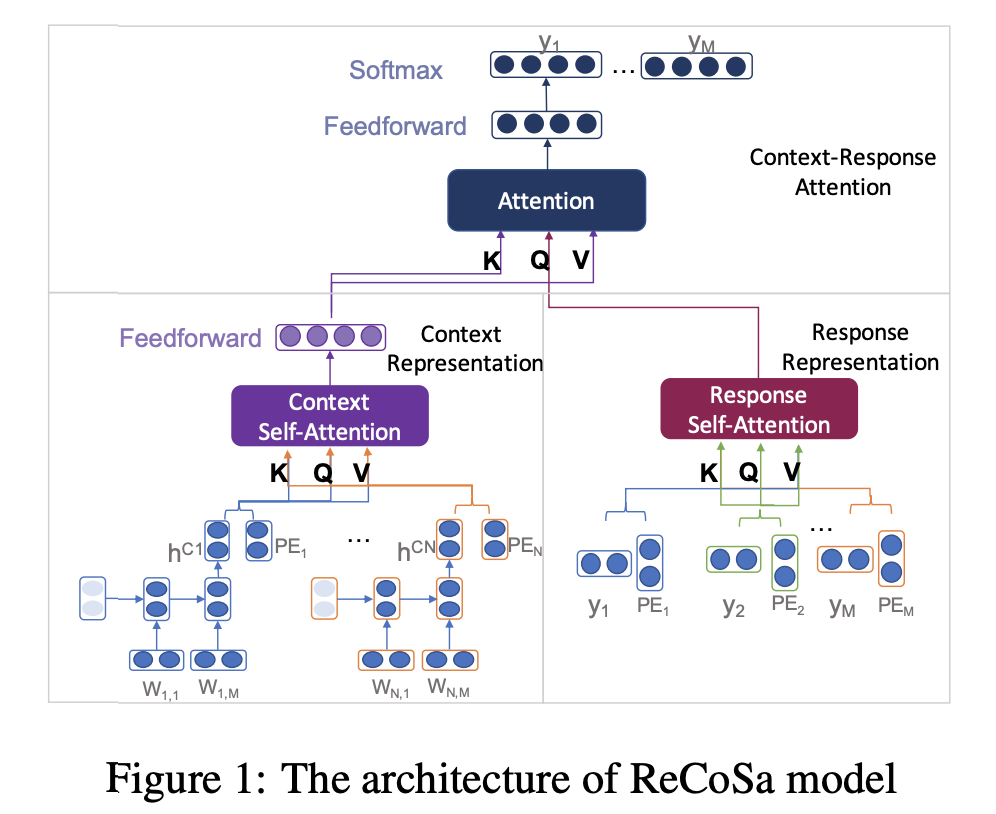
제시하는 모델(ReCoSa)의 구조는 위 그림과 같습니다. 다른 생성모델과 동일하게, 인코더와 디코더 구조를 가지고 있으며, 인코더(그림의 아래 부분)는 Word-level Encoder, Context Self-Attention, Response Self-Attention로 구성되고, 디코더(그림의 윗 부분)는 이를 이용한 Context-Response Attention decoder로 구성됩니다.
-
입력으로 Multi-turn의 대화의 컨텍스트가 주어지면, Word-level Encoder가 컨텍스트의 각 문장을 인코딩합니다. 그리고 Context Self-Attention 모듈에서 컨텍스트의 관계를 고려한 representation을 만듭니다.
-
Response Self-Attention은 현재까지 생성된 답변의 단어들 사이의 Self-Attention을 이용해 단어들의 Representation을 구합니다.
-
마지막으로 Context-Response Attention decoder는 1번 단계에서 계산한 컨텍스트를 구성하는 각 문장들의 representation을
key,value로 2번 단계에서 계산한 답변의 단어 representation을query로 하여 컨텍스트를 고려한 답변 representation을 계산합니다. 이와 Softmax 연산을 통해 생성할 단어를 결정합니다.
1. Context Representation Encoder
위 그림에서 왼쪽 아래에 위치한 부분으로, 1번 과정의 연산을 담당하며 Word-level Encoder, Context Self-Attention로 구성됩니다.
1.1. Word-level Encoder
컨텍스트를 구성하는 각 문장들을 LSTM 기반 인코더로 하나의 벡터로 인코딩 하는 역할을 합니다. 컨텍스트 \(C=\{s_1, s_2, ..., s_N\}\)와, 각 문장 \(s_i = \{x_1, x_2, ... x_M\}\)이 주어졌을 때, LSTM 인코더는 각 \(s_i\)를 입력으로 받아 인코딩을 진행하고, 마지막 hidden state(\(h_M\))를 문장의 representation으로 이용합니다. 결과적으로 각 문장의 representation \(\{h^{s_1}, h^{s_2}, ... h^{s_N}\}\)을 얻을 수 있습니다.
Self-Attention 연산은 그 자체로 해당 representation의 위치를 구별할 수 없습니다. 따라서 각 문장의 위치를 나타낼 수 있는 Positional Embedding, \(P_i \in \mathbb{R}^{d}, i=1,...,N\)과 위 연산의 결과를 합쳐 문장의 representation으로 이용합니다. (\(\{(h^{s_1}, P_1), (h^{s_2}, P_2),..., (h^{s_N}, P_N)\}\))
1.2 Context Self-Attention
Self-Attention(Vaswani et al., 2017) 메커니즘은 representation의 시퀀스가 주어졌을 때, 해당 시퀀스들 사이의 자체 유사도만을 이용하여 representation을 계산해나가는 방식입니다. RNN계열의 방법에 비해 long-distance dependency를 잘 모델링할 수 있기 때문에, 많은 Sequence 모델링 테스크에서 뛰어난 성능을 보여주었습니다.
본 논문에서는 Word-level Encoder에서 계산한 각 문장의 representation을 Key, Query, Value로하여 Multi-head Self Attention 연산을 진행합니다. 이를 통해 컨텍스트의 다른 문장들을 고려한 각 문장의 representation을 얻을 수 있습니다.
2. Response Representation Encoder
위 그림에서 오른쪽 아래에 위치한 부분으로, 2번과정의 연산을 담당합니다. 생성하고 있는 답변의 representation을 만드는 역할을 합니다. Word Embedding 이후에 각 단어의 representation에 Positional Embedding 정보를 추가하여 multi-head Self-Attention 연산을 진행합니다.
일반적인 생성 모델의 decoder와 유사하게, 학습시에는 ground truth를 이용하고, 추론시에는 이전 time step에서 생성된 결과를 이용합니다.
2.1 Training Phase
학습을 진행할 경우, 이미 답변을 구성하는 토큰들의 ground truth가 주어지기 때문에 각 time step에서 이전 step까지의 ground truth를 이용합니다.
주어진 ground truth, \(Y = \{y_1, y_2, ..., y_M\}\)에 대해 word Embedding을 진행하고, Self-Attention 연산을 위해 위치 정보를 추가하여 \(\{(w_{1}, P_1), (w_{2}, P_2),..., (w_{M - 1}, P_{M - 1}) \}\)를 얻습니다. 이를 key, query, value로 이용하는 Self-Attention 연산을 진행합니다. 이를 통해 이전 time step까지의 단어들을 고려한 representation을 얻을 수 있습니다. 이 때, 생성될 토큰을 미리 보면 안되므로, \(t\)번째 step에서는 \(t-1\)까지만 attend할 수 있도록 masking 처리를 진행합니다.(일반적으로 attention연산에서 Softmax연산 이전에 attend를 원하지 않는 represenation에 큰 음수를 더하여 attention prob이 가지 않도록 하는 방법을 이용합니다.)
2.2 Inference Phase
다른 생성 방법과 동일하게, <Start> 토큰으로 시작하여 연산을 진행하고, 다음 step부터는 생성된 토큰을 이용하여 동일한 연산을 진행하고 <End> 토큰이 생성될 때까지 이 과정을 반복합니다. (이전의 생성된 결과물 까지만 볼 수 있기 때문에, 별도의 masking이 필요하지 않습니다.)
3. Context-Response Attention Decoder
Context Self Attention의 결과를 Key, Value로 이용하고 Response Representation Encoder 의 결과를 value로 이용하여 Self-Attention 연산을 진행합니다. 이를 통해 컨텍스트의 각 발화들과 현제까지 생성된 답변을 고려한 representation을 만들 수 있습니다. 즉 현재까지의 답변을 고려했을 때, 답변의 다음 토큰 생성에 있어서 컨텍스트의 각 발화 중 어떤 발화를 고려할지 결정합니다. 최종적으로, Vocabulary의 토큰 갯수로 transform하는 feedforward network와 Softmax 연산을 통해 어떤 단어를 생성할지 결정합니다.
주어진 컨텍스트 \(C=\{s_1, s_2, ..., s_N\}\), 답변 ground truth \(Y = \{y_1, y_2, ..., y_M\}\)에 대해 생성한 문장의 log-likelihood는 다음과 같습니다.
\[\log{P(Y\mid C; \theta)} = \sum\limits^M_{t=1} \log{P(y_t \mid C, y_1, ... y_{t-1};\theta)}\]이 식을 최대화 하는 쪽으로(negative log-likelihood를 최소화 하도록) 학습이 진행됩니다.
Experiments
1. Settings
1.1 Dataset
두 개의 Multi-turn 대화 데이터를 이용했습니다.
- JDC: 중국어 커스터머 서비스데이터 셋으로, 515,686개의 context-response 쌍을 포함합니다. 500,000개의 학습셋, 7,843개의 검증, 테스트셋으로 분리하여 이용했습니다.
- Ubuntu dialogue corpus: Ubuntu의 질문-대답 포럼의 데이터를 뫃아놓은 것으로, 700만 대화 데이터를 포함합니다. 공식 토크나이즈 과정을 거치고, 일부 부정확한 데이터를 제거함으로써 약 400만개의 학습셋, 10,000개의 검증, 테스트셋을 이용했습니다.
1.2 Baselines and Parameter Setting
6개의 baseline method를 이용했습니다.
- traditional Seq2Seq
- HRED
- VHRED
- Weighted Sequence with Concat(WSeq)
- Hierarchical Recurrent Attention Network(HRAN)
- Hierarchical Variational Memory Network(HVMN)
모델 파라메터 세팅은 다음과 같습니다.
- Vocab 크기: 69,644(JDC), 15,000(Ubuntu)
- Hidden size: 512 (baseline 모델도 모두 동일)
- Batch size: 32
- 각 발화의 max length: 50
- 각 대화의 max turn: 15
- RoCoSa의 head 수: 6
- Optimizer: Adam
- Learning rate: 0.0001
1.3 Evaluation Measures
정량적 평가와 정성적 평가를 모두 진행했습니다.
- 정량적 평가: PPL, BLEU score, distinct(생성된 결과의 유니크한 unigram, bigram의 갯수를 세어 diversity를 측정)
- 정성적 평가: 3명의 annotator가 ReCoSa와 Baseline 사이의 win,lose,tie를 평가
2. Results
2.1 정량적 평가
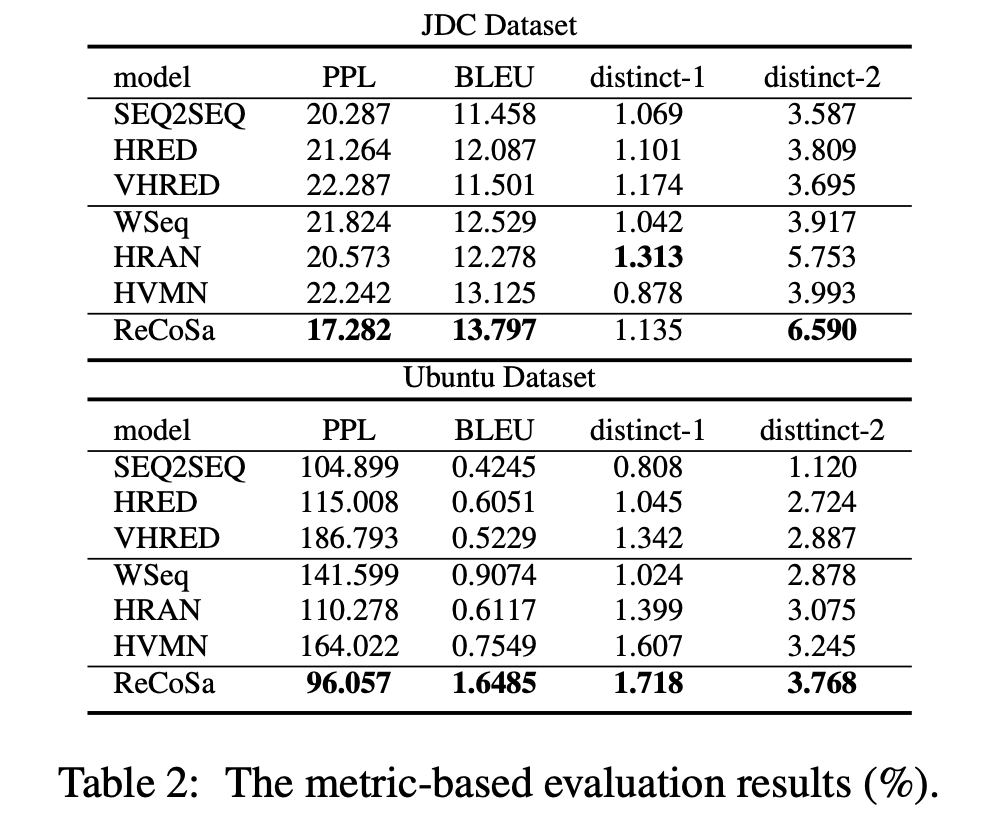
위의 결과와 같이 정리할 수 있으며, 이를 분석하면 다음과 같습니다.
- Attention based 모델(WSeq, HRAN, HVMN, ReCoSa)은 전통적인 Seq2Seq, HRED를 능가했습니다. 이는 Attention 연산을 통해 모든 모델이 컨텍스트의 연관성을 조금 더 잘 고려했기 때문입니다.
- 모든 baseline에 비해 ReCoSa는 PPL/BLEU, distinct-2에서 뛰어난 결과를 보입니다. 이는 제시한 모델이 다른 방법들에 비해 생성 자체를 잘할 뿐만 아니라 좀 더 다양한 답변을 할 수 있음을 의미합니다.
2.2 정성적 평가
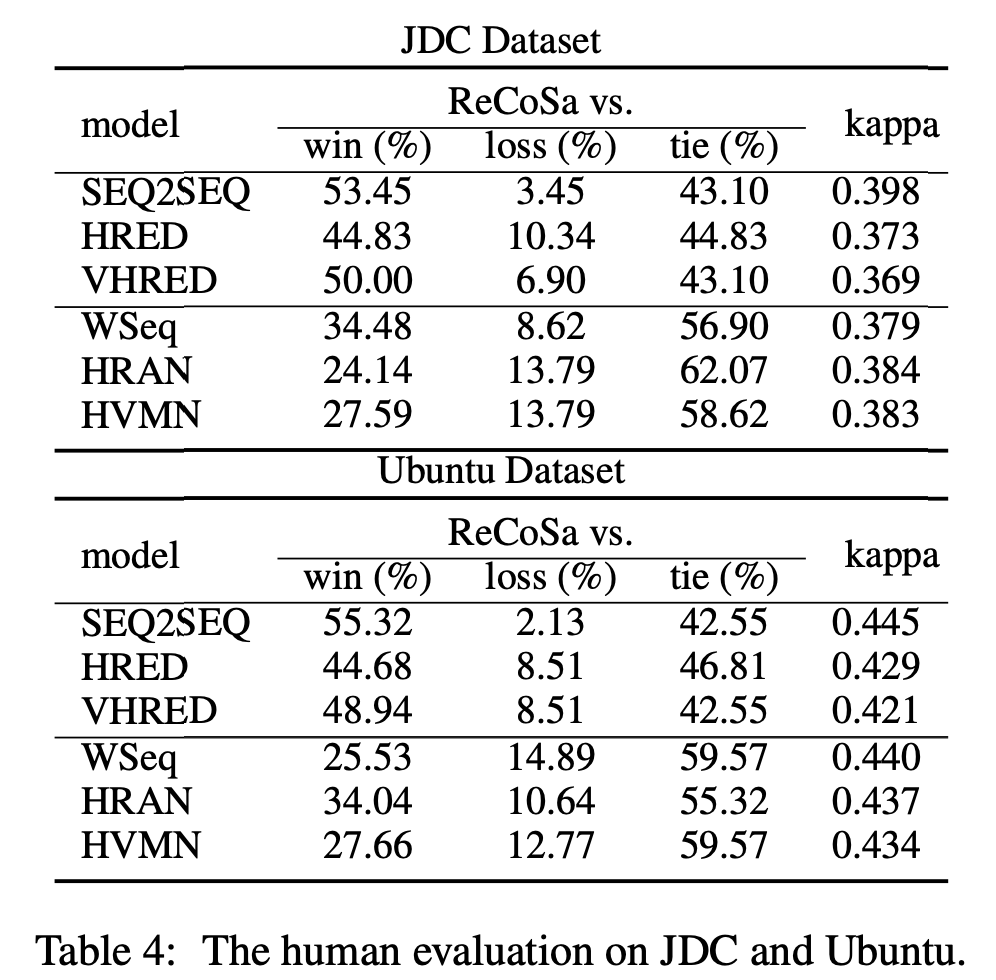
위의 결과와 같이 정리할 수 있으며, 모든 경우에서 제시한 모델이 이긴 경우가 많음을 볼 수 있습니다.
3. Analysis on Relevant Contexts
JDC 데이터셋에서 500개의 context-response 쌍을 랜덤으로 샘플링하고, 컨텍스트의 발화 중 답변과 관계있는 발화에 대해 레이블링을 진행했습니다.(관계 있는 경우 1, 아닌 경우 0)
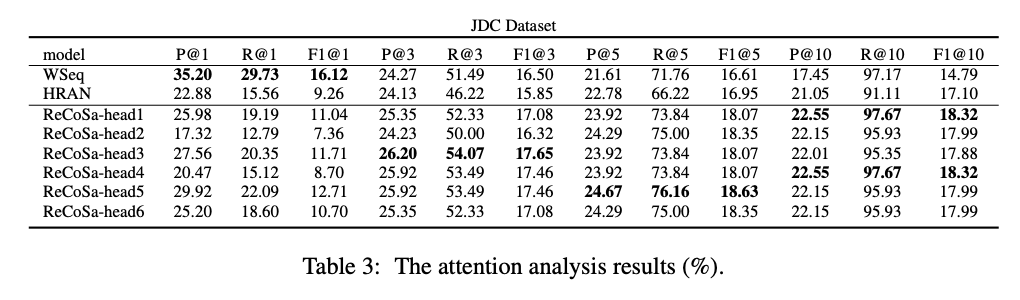
Attention 메커니즘을 이용하여 Context 중 어떤 발화를 attend하고 있는지 명확하게 알 수 있는 모델들 (HRAN, Wseq, ReCoSa)에 대해 정량적 평가를 진행했습니다. Context-Response 사이의 Attention score를 바탕으로 Ranking을 매기고, precision@K, recall@K, f1@K metric으로 평가를 진행했습니다.
결과는 위의 표와 같으며 이를 분석해보면 다음과 같습니다.
- 전체 셈플 중 80%가 마지막 발화의 label이 1이였습니다. WSeq는 이와 같은 양상 때문에, P@1, R@1, F1@1에서 가장 좋은 성능을 보이지만(마지막 발화를 top1으로 뽑을 가능성이 높기에), 나머지에서는 좋지 못한 성능을 보였습니다.
- @1을 제외한 대부분의 경우에서 ReCoSa가 좋은 결과를 보여주었습니다. 이를 통해 ReCoSa는 인간의 연관성 평가와 상당히 유사한 양상을 보인다는 점을 알 수 있습니다.
Reference
- Hainan Zhang, Yanyan Lan, Liang Pang, Jiafeng Guo and Xueqi Cheng. 2019. ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation. ACL, 2019.