
이번 글에서는 “Transformers to Learn Hierarchical Contexts in Multiparty Dialogue for Span-based Question Answering”을 리뷰합니다. Transformer 기반의 컨텍스트를 반영한 임베딩을 만드는 접근법들(BERT, RoBERTa, XLNet 등)은 QA의 SOTA를 갱신해왔습니다. 하지만 일반적인 도메인에서 학습된 모델들로 대화를 잘 표현하기는 어렵고, 주어진 대화에 대한 QA 테스크에서 저조한 성능을 보입니다. 이 원인으로 두 가지를 꼽을 수 있습니다. 1) 대화들은 구어체인 반면에 대부분의 모델들은 격식이 갖춰진 문어체로 학습되었습니다. 2) 한 명의 저자가 관련이 있는 토픽에 관해쓴 wiki나 뉴스 기사와 같은 글과 달리 대화는 다른 주제와 각자의 방식을 가진 여려명의 화자들의 발화로 구성됩니다. 따라서 단순히 합치는 방법(concat)을 통해 보다는 내부적으로 서로 연결되어있는 방식의 표현법이 필요합니다. 본 논문에서는 이를 해결하기 위해 멀티파티(여러 명의 화자) 대화에서 “컨텍스트를 더 잘 이해할 수 있는” 토큰과 발화의 계층적 임베딩을 학습하는 Transformer를 제안합니다.
1. Main Idea
- 토큰 단위와 문장 단위의 임베딩의 질을 높일 수 있는 대화체에 적합한 새로운 pre-training 테스크(토큰 단위, 발화 단위의 LM, 발화 순서 예측)를 제시합니다.
- pre-training으로부터 생성된 계층적인 임베딩의 이점을 잘 이용할 수 있고, span-based QA에 적합한 새로운 Multitask learning Finue-tuning 접근법을 제안합니다.
- 이 방법들을 이용하여 이전 SOTA인 BERT와 RoBERTa를 큰 격차로 능가했습니다.
2. Transformes for Learning Dialogue
2.1. Pre-training Language Models
Pre-training과정은 토큰 단위, 발화 단위의 Languague Modeling, 문장 순서 예측의 3가지 테스크를 순차적으로 학습합니다. 각각의 테스크에서 학습된 가중치는 다음 테스크에 전이됩니다. 모델은 토큰 임베딩을 입력으로 받는 Transformer 인코더(\(TE\))와 문장 임베딩을 입력으로 받는 2개의 Transformer Layer(\(TL1, TL2\))로 구성됩니다. 이 때, \(TE\)의 초기 시작점은 BERT나 RoBERTa의 공개된 가중치로 이용합니다. 이를 통해 구어체, 문어체를 모두 다룰 수 있습니다.
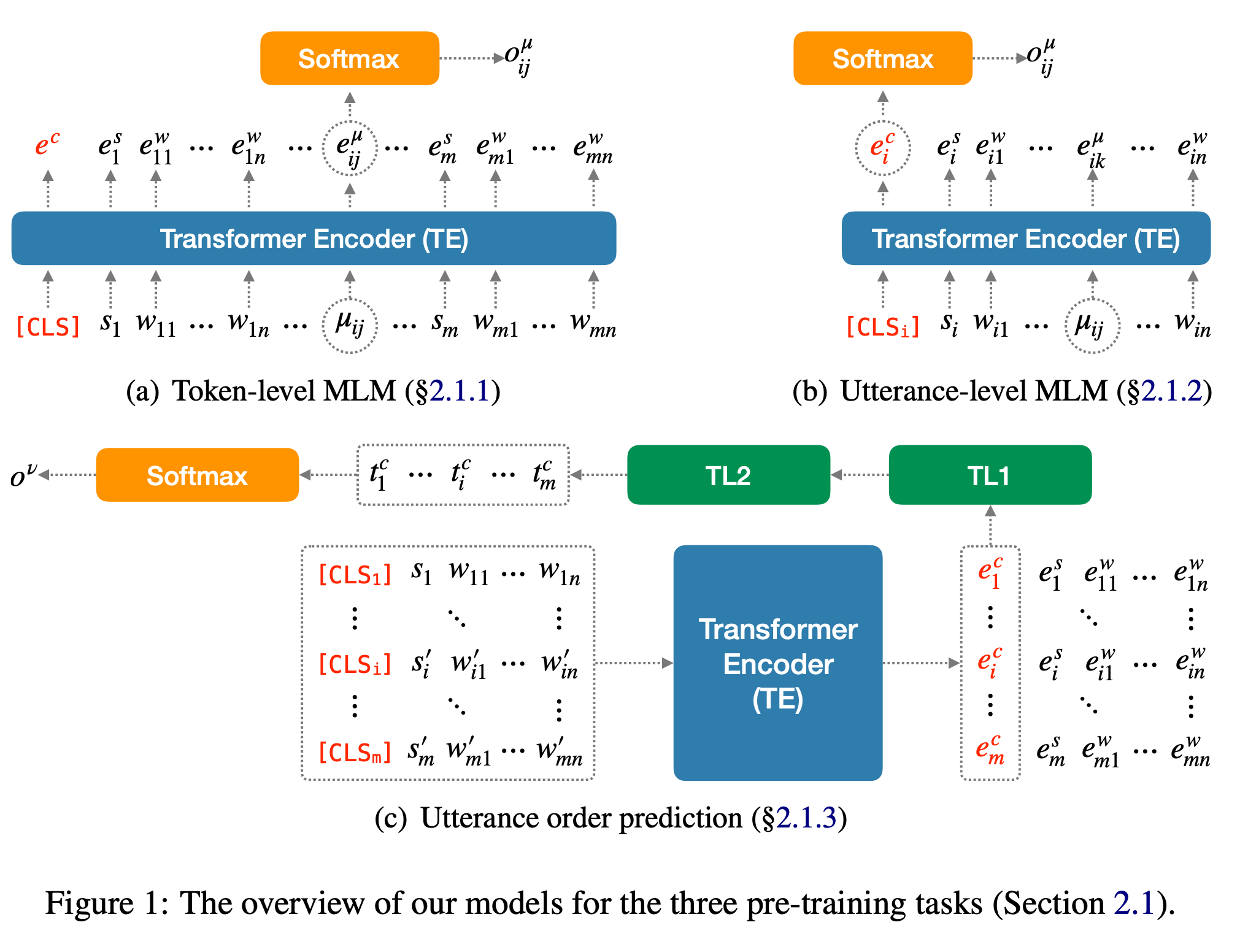
2.1.1. Token-level Masked LM(t-MLM)
BERT와 유사한 설정으로 Masked Language Modeling 테스크를 풉니다. 이 때, 입력은 위 그림의 (a)와 같이 구성되는데, 하나의 대화(\(D\))가 주어지면, 특수 토큰 \([CLS]\) 를 시작으로 하여 대화 내의 발화들\((D = \{ U_1, U_2, ... U_m \})\)을 순서대로 이어붙입니다. \(i\) 번째 발화(\(U_i\))들은 화자를 나타낼 수 있는 토큰(\(s_i\))와 단어 토큰들(\(w_{ij}\))로 구성됩니다. 결과적으로 \(I = [CLS] \oplus U_1 \oplus ... \oplus U_m\)의 형태가 만들어집니다. 이 때 각 발화의 토큰들 중 일정 비율을 마스킹하고 이를 \(TE\) 를 이용하여 예측합니다.
2.1.2. Utterance-level Masked LM(u-MLM)
Token단위의 MLM은 발화의 경계에 관계 없이 모든 토큰 사이의 (넒은 컨텍스트의 모든 토큰과 비교하는) 어텐션을 학습합니다. 하지만 이 방식은 대화에서 중요할 수 있는 각각의 발화에 대한 독특한 양상을 잡아내기 힘듭니다.
이를 위해 위 그림의 (b)와 같이 발화 단위의 MLM을 통해 각각의 발화에 해당하는 임베딩을 학습합니다. 발화(\(U_i\))는 \(I = {[CLS]_i, s_i, w_{i1}, w_{i2}, ... }\) 과 같은 형식으로 \(TE\)에 입력됩니다. \([CLS]_i\) 토큰은 문장을 대표하는 토큰으로 볼 수 있습니다.(t-MLM의 \([CLS]\) 와 다른 토큰입니다.) 이 때, \(w_i1 ... w_in\) 중 “한 개”의 토큰을 마스킹하고 이를 예측합니다. t-MLM이 마스킹된 토큰 위치의 출력 값 대신에 \([CLS]_i\) 토큰의 출력값을 이용하여 예측을 진행합니다. 여기에는 “일단 \([CLS]_i\) 를 이용하여 발화의 어떤 토큰이든 정확히 예측할 수 있을 정도로 충분한 컨텐츠를 학습했다면, 해당 발화의 가장 중요한 특징들로 구성되어 있다고 볼 수 있다”는 가정이 깔려있습니다.
2.1.3. Utterance Order Prediction(UOP)
u-MLM의 임베딩은 발화 \(U_i\) 안에 있는 컨텐츠를 학습했지만 다른 발화들에 대한 정보는 포함하지 못합니다. 대화는 여러 발화에 의해 컨텍스트가 완성됩니다. 따라서 발화 사이의 관계(어텐션)을 학습하는 것은 필수적입니다. 여러 발화들을 거쳐 형성되는 특징들을 담고 있는 임베딩을 학습하기 위해 위 그림의 (c)와 같이 발화 순서 맞추기(Utterance Order Prediction)를 학습합니다.
주어진 문서(\(D\))를 반으로 나눠서 두 부분으로 만들고\((D = D_1 \oplus D_2)\), 일정 확률로 \(D_2\) 발화들의 순서를 섞어 \(D' = D_1 \oplus D_2'\) 을 만듭니다. 모델은 주어진 대화의 문장들의 순서가 올바른지(\(D\)) 섞였는지(\(D'\)) 예측합니다.
u-MLM으로 학습된 모델을 이용해 \(D\) 에 있는 모든 발화(\(U_i \in D\))들을 인코딩하고, 각 발화의 대표 토큰(\([CLS]_i\))의 임베딩\((E_i = \{ e_1^c, e_2^c, ... e_n^c \})\)을 뽑습니다. 이 임베딩들은 두 개의 Transformer Layer(\(TL1, TL2\))를 거쳐 컨텍스트(다른 발화들)가 고려된 새로운 문장 임베딩 \(T^c = \{ t_1^c, t_2^c, ... t_n^c \}\) 를 만듭니다. 최종적으로 이를 이용하여 이진 분류값(순서가 올바른지/섞였는지) 중 하나로 예측합니다.
2.2. Fine-tuning for QA on Dialogue
Fine-tuning은 발화 ID 예측과 token span 예측 문제(QA)를 함께 Multitask로 학습합니다. UOP로 학습된 모델은 두 테스크에 모두 이용됩니다. QA테스크는 질문, \(Q = \{ q_1, q_2,..., q_n \}\) (\(q_i\) 는 질문의 각 토큰)와 대화, \(D = \{ U_1, U_2, ... U_m \}\) (\(U_i\) 는 대화의 각 발화) 가 주어지고 해당 질문의 답을 대화의 span으로 예측하는 문제를 풉니다. 먼저 질문(\(Q\))과 각 발화들(\(U_*\))을 pre-training된 \(TE\)로 질문의 임베딩 \(E_q = \{ e_q^c, e_1^q, ... e_n^q \}\)과 각 발화의 임베딩 \(E_i=\{ e_i^c, e_i^s, e_{i1}^w, ..., e_{in}^w \}\)을 만듭니다.
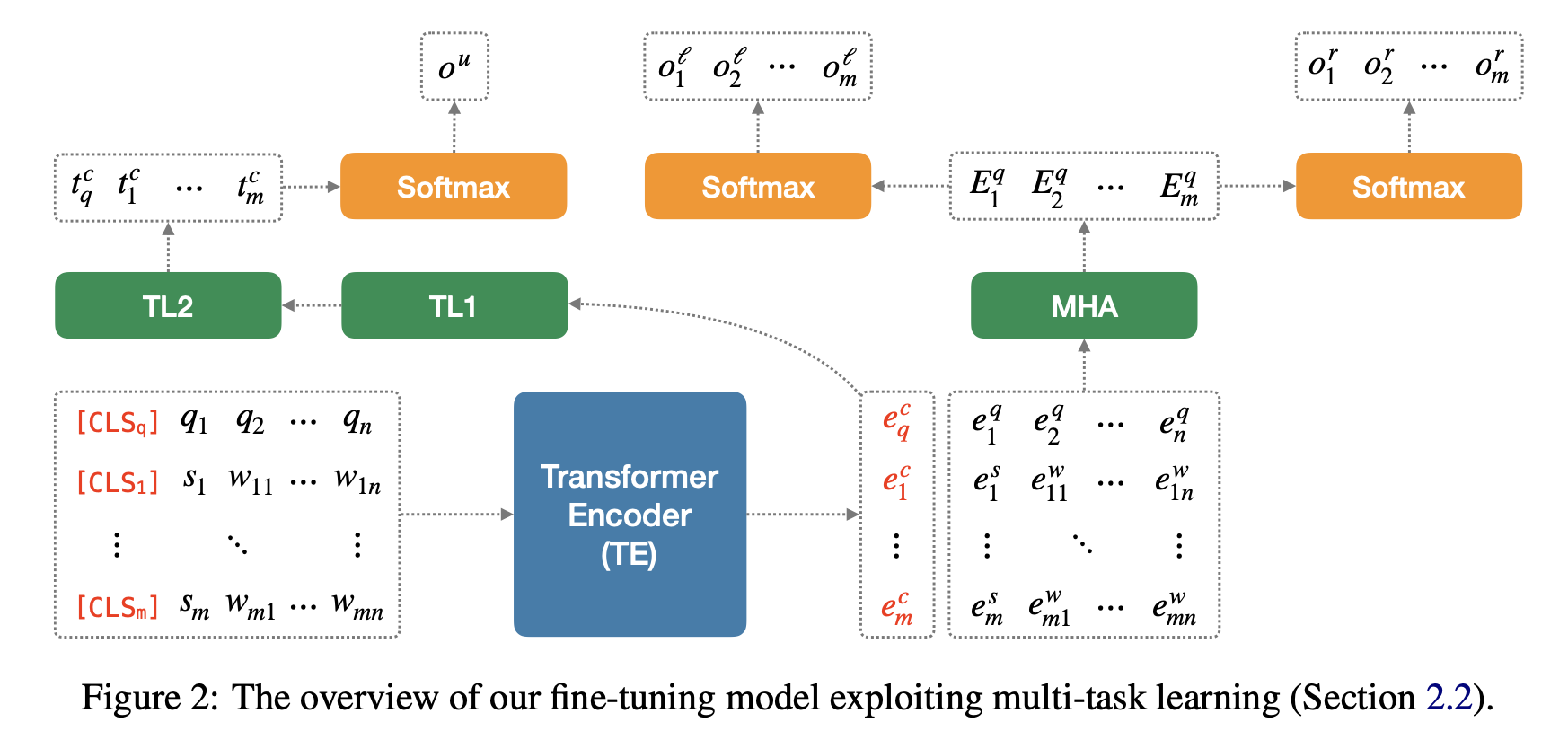
2.2.1. Utterance ID Prediction
위에서 계산했던 질문과 발화의 대표 임베딩(\([CLS]\) 토큰의 임베딩) \(E^c = \{ e_q^c, e_1^c, ... e_n^c \}\)을 \(TL1, TL2\)를 이용하여 컨텍스트를 반영한 임베딩 \(T^c = \{ t_q^c, t_1^c, ... t_n^c \}\)로 만듭니다. 이를 이용해 질문에 대한 정답 span을 포함하고 있는 발화의 ID를 예측합니다. 여기서 0을 예측하면 정답이 \(D\) 안에 존재하지 않음을 의미합니다.
2.2.2. Token Span Prediction
모든 발화의 임베딩 \(E_i\)에 대해 \((E_q', E_i')\)쌍을 새로운 Multi-head Attention(MHA) layer로 인코딩합니다. \(E_q', E_i'\)는 \(E_q, E_i\) 에서 \([CLS]\) 를 제외한 나머지 토큰들의 임베딩입니다. 이를 통해 각 발화마다 결과 값 \(T_1^a, ... T_m^a, T_i^a = \{ t^s_i, t^w_{i1}, ..., t^w_{im} \}\)를 얻을 수 있습니다. 전형적인 QA문제와 동일하게 구해진 토큰단위의 임베딩(\(T_i^a\))와 span 시작점/끝점 분류기를 이용해 span을 예측합니다. 여러 발화에서 정답이 예측될 수 있는데, 이 경우 발화 ID 예측에서 가장 높은 점수를 받은 발화의 답을 선택합니다.
3. Experiments
3.1. Corpus
대화를 답변의 선택지로 이용하는 공개된 데이터셋은 DREAM과 FriendsQA 두 가지 입니다. DREAM은 대화에 대한 객관식 문제를 푸는 데이터이고, FriendsQA는 TV 프로그램 Friends의 대본으로 구성되며 질문과 span 기반의 답변이 포함되어 있습니다. DREAM은 제시한 방법으로 풀기에 적절하지 않기 때문에 FriendsQA를 이용했습니다.
FriendsQA에서는 각 장면이 독립적인 대화로 다뤄집니다. 데이터셋의 저자들은 이를 랜덤으로 학습/검증/평가 셋으로 나눴는데, 이렇게 되면 같은 에피소드의 여러 장면들이 각 셋에 분포할 수 있습니다. 따라서 학습셋에 있는 장면과 유사한 장면들이 검증/평가 셋에 존재하여 정확도가 부풀려질 수 있습니다. 본 논문의 저자들은 이를 에피소드 별로 다시 학습/검증/평가 셋으로 나눠서 실험을 진행했습니다.
3.2. Models
BERT와 RoBERTa의 가중치는 본 논문의 모든 실험에 전이학습되었습니다. 실험은 BERT/RoBERTa를 단순 fine-tuning한 모델(BERT/RoBERTa), 각 모델을 FriendsQA의 데이터로 추가적으로 pre-training(t-MLM)으로 추가학습 한 후 fine-tuning한 모델(BERT_pre/RoBERTa_pre), 새로 제시한 방법으로 학습한 모델(BERT_our, RoBERTa_our)를 비교했습니다.
3.3 Results
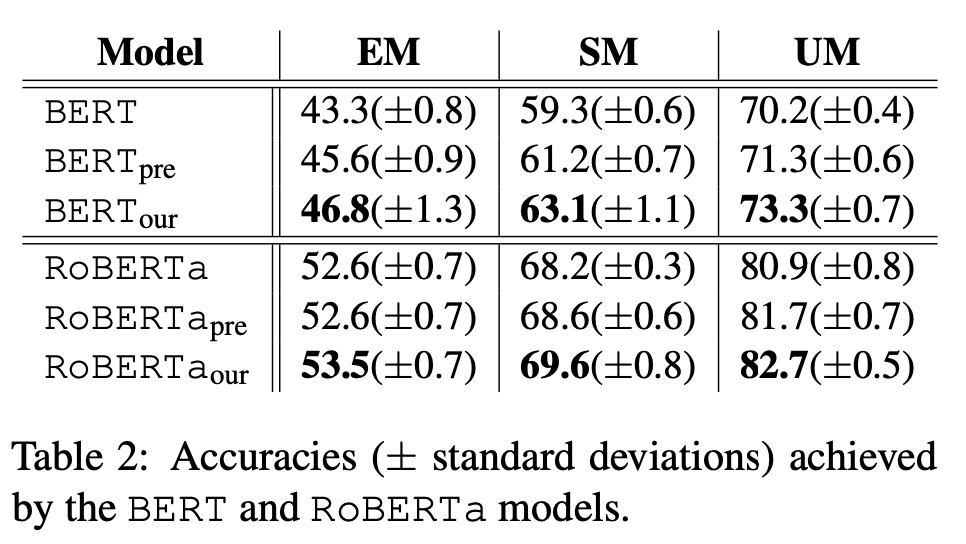
성능은 EM(Exact Matching), SM(Span Matching), UM(Utterance Matching)의 세 가지 지표로 측정되었으며, 위 표와 같습니다. 전반적으로 RoBERTa기반의 모델들이 더 많은 데이터로 pre-training 되었기 때문에 BERT보다 뛰어난 성능을 보입니다. FriendsQA데이터를 이용해 추가적인 pre-training을 진행한 *pre의 경우 일종의 Domain adaptation 효과로 기본 모델보다 좋은 성능을 보입니다. 이를 통해 원래의 모델들은 이러한 QA테스크를 풀기에는 부족하다는 결론을 얻을 수 있습니다. *our 모델의 경우 모두 가장 좋은 성능을 달성했습니다.
3.4. Ablation Studies
논문에서 제시한 각각의 접근법들의 효과를 검증하기 위해 여러 실험들을 진행했습니다. 제시한 u-MLM과 UOP의 효과를 검증하기 위해 *pre 방법에서 u-MLM(ULM)과 UOP를 추가적으로 학습시킨 경우를 실험했습니다. 또한 발화 ID 예측의 효과를 검증하기 위해 *pre 의 설정에서 fine-tuning과정에 발화 ID예측을 추가한 *uid 실험과 여기에 u-MLM(ULM)과 UOP를 추가한 경우에 대해 실험을 진행했습니다.
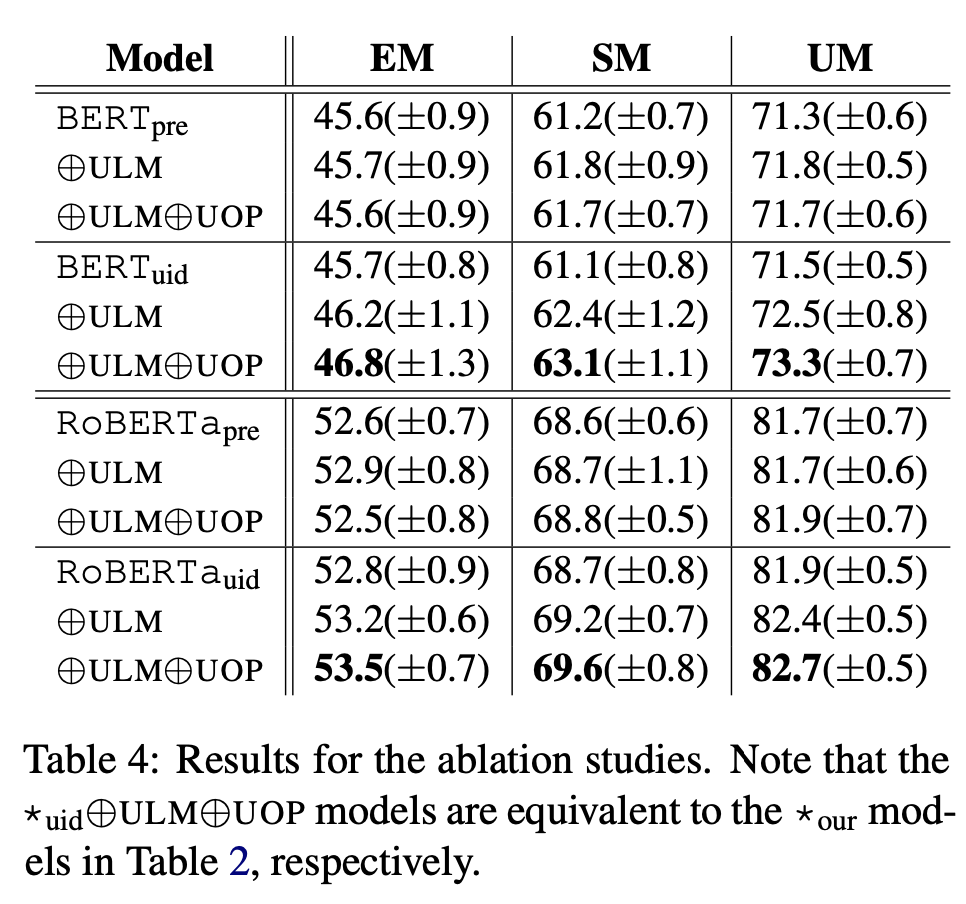
위의 표와 같이 본 논문에서 제시한 두 가지 새로운 pre-training objective와 fine-tuning에서 이용하는 발화 ID 예측 모두 효과가 있음을 알 수 있습니다. 특히 발화 ID 예측 테스크는 다른 pre-training objective와 결합될수록 좋은 성능을 보였습니다. 이를 통해 fine-tuning 단계에서도 적절한 방법을 선택하면 더 좋은 성능을 얻을 수 있음을 알 수 있습니다.
4. 마무리
이 논문은 이번 ACL 2020에 어셉되었다고 나와있는데, 논문 길이로 봤을 때 아마 short paper일 듯하다. 그렇다 보니 아무래도, 논문에 명시되지 않은 디테일이 있어서 몇가지 궁금한 점이 남는다.
- 대화에서 발화의 위치(순서)정보는 매우 중요할 것 같은데, 논문에서는 이에 대한 구체적인 언급이 없다. 위치 정보를 줄 수 있는 요소를 예측해보자면 \(s_i\)와 \(CLS_i\), UOP objective인데 이들의 조합으로 충분히 학습될 수 있을지 의문이 남는다.
- MHA에서 KQV가 어떻게 구성되는지에 대한 명시도 없다. \(K,V=E_q\), \(Q=E_i\) 이여서, 각 발화 토큰들과 질문 토큰사이의 어텐션으로 계산하는 것으로 예측해볼 수 있다.
뭔가 이러한 부분들 때문에 상세한 구현에 있어서 “?”가 남는 부분이 많을 것 같고, 바로 적용해보기엔 무리가 있을 것 같다.
5. Reference
- Changmao Li and Jinho D. Choi. Transformers to Learn Hierarchical Contexts in Multiparty Dialogue for Span-based Question Answering. arXiv preprint arXiv:2004.03561, 2020