
Self supervied learning은 사람이 만든 정답 없이 데이터 자체(self)에서 만들어진 정답(supervised)으로 학습하는 방법이고, 현재 여러 모달리티(이미지, 텍스트, 음성 등)에서 잘 동작하고 있는 아이디어이다. 지금까지 방법론들은 특정 모달리티에 집중하였기 때문에, 각 모달리티별로 학습 방법(objective, algorithm 등)이 다르다. 이를 더 일반적인 방법으로 확장하기 위해 data2vec이라는 self supervised learning 방법을 제안하는 data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language을 리뷰한다.
1. Main Idea
- 모달리티에 관계없이 일반적으로 잘 적용될 수 있는 Self supervised learning 방식을 제안한다.
- Teacher-Student 구조: 같은 구조(Transformer)의 모델을 Teacher-Student로 구성한다. Teacher의 경우 Student 모델 가중치의 exponentially moving average이다.
- learning latent target representation: Teacher의 latent representation(Transformer 의 출력값)을 Student가 예측한다. 이 representation(Student의 Target 값) 값은 연속적(continuous)이고, 주어진 컨텍스트를 인코딩(contextualize) 한다.
- 이 의미가 직관적으로 와닿지 않을 수 있는데, 이와 반대로 BERT는 마스킹되기 이전 토큰을 Target값으로 하기 때문에 discreate 하고, contextualize되어있지 않다고 볼 수 있다.
- Masked prediction: Teacher은 full input을, Student는 masked input을 이용하여 각각 representation을 만든다.
- 실험을 진행한 3개의 모달리티(이미지, 텍스트, 음성)에 대해 SoTA에 준하는 성능을 달성했다.
2. Related Work
제안한 연구의 동기가 되는 이미지, 텍스트, 음성 모달리티의 기존 self supervised learning 방법을 살펴본다.
Self-supervised learning in computer vision
컴퓨터 비전 분야에서 레이블 없이 사전학습을 하는 방법은 활발하게 연구되고 있다. (비전 관련 self-supervised learning에 관련해서는 잘 모르기때문에 틀린 정보가 있을 수 있음.)
- 같은 이미지를 다르게 augmentation 한 것(positive)와 완전히 다른 이미지(negative)를 contrastive learning 방식으로 학습
- oneline clustering
- 본 논문에서 제안한 방식과 유사하게 모멘텀 인코더의 representation을 regression 하는 방식
- visual token이나 입력 픽셀 자체를 masking하고 예측하는 masked prediction
Self-supervised learning in NLP
사전학습을 이용한 방법들은 Natural Language Understanding(NLU) 태스크들에서 매우 좋은 성능을 보이고 있다. 대표적으로 BERT에서 이용한 Masked Language Modeling은 입력 토큰을 일정 확률로 마스킹하고 이를 예측하는 문제를 푼다.
Self-supervised learning in speech
autoregressive(단방향)과 bi-directional(양방향) 모델링을 모두 시도하고 있다. wav2vec2.0과 HuBERT가 가장 유명한 방법이며, 음성의 discreate한 단위를 예측하는 문제를 푼다. (음성도 비전과 마찬가지로 잘 모르기 때문에 틀린 정보가 있을 수 있음.)
전반적으로 Transformer 구조 & 입력을 마스킹하고 이를 예측하는 objective는 모달리티에 관계없이 시도되고 있는 듯 하다. 하지만 입력 구성등 디테일은 차이가 있는 것 같다. 아마 데이터 자체만으로 문제를 만들기에는 마스킹 -> 예측이 접근하기 쉬운 방법이고, 이에 적합한 구조가 Transformer여서 이러한 경향이 나타나는 것 같다.
3. Data2Vec
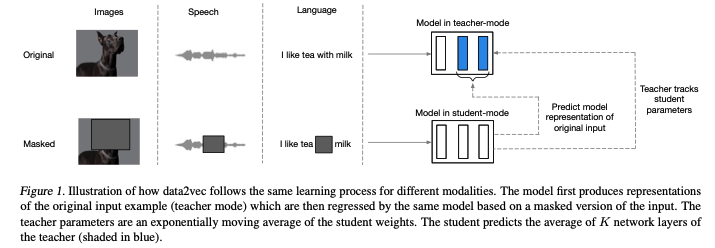
Data2Vec의 전체적인 학습 과정은 위 그림과 같다. 1) full input을 이용한 represenation을 2) partial input을 이용하여 예측하는 문제를 푼다. 학습되는 모델은 하나만 존재하며, Teacher, Student두 개의 모드로 동작할 수 있다. Teacher 모드의 경우, 모델 파라메터의 exponential moving average 값으로, Student모드의 경우 모델 파라메터를 그대로 이용한다. Meta AI 블로그에는 다음과 같이 표현되어 있다. “The teacher network is identical to the student model but with weights that are slightly out of date.” 즉 두 모드는 같은 모델로부터 나오지만 Teacher의 경우 EMA값을 이용하기 때문에 약간 out of date되어 있다는 것이다. 1번의 representation은 Teacher 모드로 부터 얻어지고, 2번의 예측은 Student 모드로 진행한다.
Model Architecture
인코더는 Transformer 구조를 이용했다. 각 모달리티별로 인코더의 입력을 구성하는 방식은 조금씩 다르다.
- 이미지 피쳐의 경우 16x16패치 영역의 픽셀을 하나의 토큰으로 인코딩하는 ViT의 전략을 이용했다.
- 텍스트의 경우 sub word단위로(토크나이즈) 전처리하고, 이를 임베딩 벡터로 인코딩했다.
- 음성의 경우, multi-layer 1-D Convolution 연산을 이용해 16kHz waveform을 50Hz의 representation으로 매핑했다.
- 무슨 의미인지 잘 모르지만, 음성 데이터를 고정된 입력 사이즈로 매핑하는 방법인 것 같다. (정확한 내용은 논문 참고)
Masking
각 모달리티의 입력이 토큰의 시퀀스(Transformer 입력의 형태)로 임배딩 되었을 때, Student의 입력으로 이용하기 위해 마스킹을 수행한다. 마스킹은 시퀀스(입력 단위)의 일부를 학습가능한 MASK 토큰 임베딩으로 대체한다. (위 그림의 Masked 입력의 형태)
- 이미지 피쳐의 경우 인접한 여러 패치(block)를 함께 마스킹하는 block-wise 마스킹 전략(BEiT의 전략)을 수행한다.
- 텍스트의 경우 토큰 중 일부를 마스킹한다.
- 음성의 경우 latent speech representation의 span을 마스킹한다.
Teacher parameterization
위에서 잠깐 언급했듯이, Teacher 모드는 모델 파라메터의 Exponentially Moving Average(EMA)로 구성된다. Teacher의 가중치 \(\Delta\) 를 식으로 나타내면 \(\Delta \leftarrow \tau \Delta + (1 - \tau) \theta\) 와 같다.
논문에서는 \(\tau\)를 constant로 사용하지 않고 학습 진행정도에따라 스케쥴링했다. 학습의 첫 \(n\)번의 업데이트 동안 \(\tau_0\)에서 \(\tau_e\) 까지 선형적으로 증가하고, 남은 학습동안은 상수로 유지한다. 이는 학습의 시작부에서는 파라메터가 랜덤으로 초기화되어있기 때문에, \(\tau\)를 작게하여 변화량을 더 크게 반영하고, 파라메터가 어느정도 학습되고 난 후에는 \(\tau\)를 크게하여, 변화량을 적게 반영하기 위함이다.
실험에서 피쳐 인코더와 positional encoder의 경우 EMA를 하지 않고, teacher와 student에서 공유하는 것이 조금 더 효율적이고, 정확하다고 한다. 코드 구현을 확인해보면, ema_transformer_layers_only 인자를 이용해 trasnformer layer 이외의 연산들(positional encoder, layer normalization 등)을 EMA의 대상에서 제외시켜 주는 로직을 확인할 수 있다.
Training targets
모델은 unmasked 샘플(full input)으로 인코딩된 representation을 masked 샘플(partial input)으로 인코딩해서 예측하도록 학습된다. 모델(Transformer)은 입력 시퀀스의 time-step당 하나의 출력 representation을(출력 차원은 [batch_size, time_step, hidden_size]) 갖는데, 이 중 masking된 time-step의 representation만 예측한다.
학습하고자하는 타겟(Teacher의 출력값)은 특정 time-step의 값이지만, self-attention 알고리즘에 의해 “contextualize”되어 있다. 이는 contextual 정보가 부족한 타겟(BERT의 경우 마스킹된 위치의 토큰, MIM의 경우 마스킹된 지역의 픽셀값 등)을 예측했던 기존의 방법들 (BERT, wave2vec, BEiT, SimMIM 등)과 대비된다.
학습 타겟은 \(L\) 개의 Transformer 블록(layer)로 구성된 Teacher의 출력값 중 상위 \(K\)개의 블록 출력값을 평균하여 민들어진다. \(l\) 번째 블록의 \(t\) time-step의 출력값을 \(a_t^l\) 이라 했을 때 다음과 같은 과정으로 타겟값을 구성한다. (실험적으로 평균을 타겟으로 학습하는 것이 각 출력값 각각을 분리해서 학습하는 것보다 좋은 성능을 보였다고 한다.)
- normalization을 수행해 \(\hat{a_t^l}\) 을 얻는다. 이를 통해 모든 time-step이 constant representation으로 수렴하는 것*과 타겟 값이 high norm을 갖는 문제를 방지한다.
- 음성의 경우, instance normalization을, 이미지와 텍스트의 경우 layer normalization을 이용한다.
- \(L\)개의 출력값 중 상위 \(K\)개의 출력을 평균한다. \(y_t = \frac{1}{K} \sum_{l=L-K+1}^{L}\hat{a_t^l}\)
*) 더 자세한 설명이 논문 마지막의 Discussion의 Representation Collapse에 정리되어 있는데, 유의미한 내용이라 여기에 정리한다. 자기자신의 출력값을 타겟으로 예측하는 알고리즘에서 representation collapse라는 현상이 발생할 수 있는데, 모델이 모든 출력에대해 비슷한 representation(타겟)을 만들어서 문제 자체가 풀기 쉬워지는 것이다. 이를 해결하기 위해, positive-negative 쌍을 이용하는 contrastive 방식, teacher의 파라메터를 학습하지 않는 방식, loss에 명시적으로 다양한 representation을 만들 수 있는 텀을 추가하는 방식 등이 제안되었다.
본 논문에서 진행한 실험에서 다음의 상황에서 collapse현상이 발생했다고 한다. (이 상황을 피해야한다.)
- learning rate가 너무 큰 경우 / warmup이 너무 짧은 경우, 하이퍼파라메터 튜닝으로 해결
- EMA에서 decay가 너무 낮은 경우, 하이퍼파라메터 튜닝(\(\tau_0, \tau_t, n\))으로 해결
- 인접한 타겟이 상관관계가 높은 음성과 같은 모달리티의 경우, 입력에서 더 긴 span을 마스킹해서 해결 추가적으로 명시으로 낮은 variance의 패널티를 부과하거나 타겟을 normalize함으로써, 문제를 해결하고자 했다.
이전 연구의 방법들은 작은 모델에서 잘 동작했지만, 더 큰 모델에서는 추가적인 튜닝이 필요했다. 하지만 본 논문에서 제안한 타겟을 평균하기 전에 normalization을 수행하는 것과 모멘텀 tracking(EMA)을 적용하는 것 만으로 represntation collapse현상을 방지하기 충분하다고 한다.
Objective
주어진 타겟(\(y_t\))과 Student의 출력값(\(f_{t}\))에 대해 Smooth L1 loss를 이용해 regression을 수행한다.
\[\mathcal{L}(y_t, f_t(x)) = \begin{cases} \frac{1}{2}(y_t - f_t(x))^2 / \beta & \left\vert y_t - f_t(x) \right\vert \leq \beta \\ (\left\vert y_t - f_t(x) \right\vert - \frac{1}{2}\beta) & \mbox{otherwise} \end{cases}\]위 식에서 볼 수 있듯이 타겟과 출력값의 차이가 \(\beta\) 보다 작으면 squared(L2) loss를, 크면 absolute(L1) loss를 이용한다. \(\beta\)는 이 경계선을 컨트롤한다. 이 loss는 outlier에 덜민감한 이점을 갖지만, \(\beta\)를 튜닝해야할 필요가 있다.
4. Result
실험은 Base(L=12, H=768, A=12), Large(L=24, H=1024, A=16) 두 크기의 모델로 진행했고, 실험 세팅(하이퍼 파라메터, 각 모달리티별 디테일)은 논문에서 확인할 수 있다.
Computer Vision
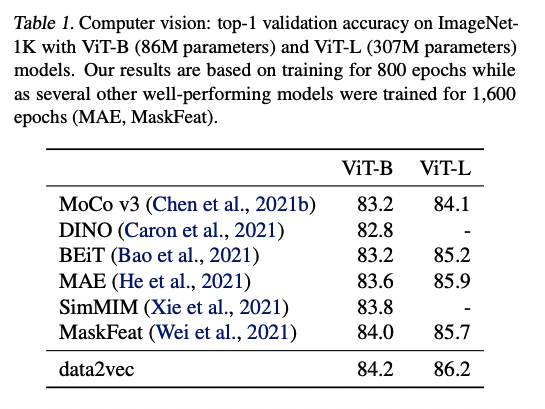
Imagenet-1K 벤치마크를 이용해서 성능을 비교했으며, 다른 self-distillation이나 masking된 pixel을 예측하는 방법으로 사전학습된 다른 모델들보다 좋은 성능을 보인다.
NLP
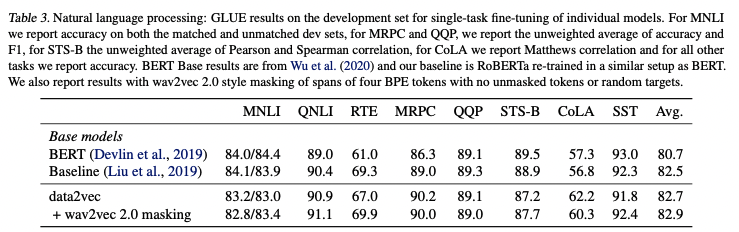
GLUE 벤치마크를 이용해서 성능을 비교했으며, BERT와 RoBERTa(Baseline, BERT와 동일한 데이터로 학습)에 준하는 성능을 보인다. 4개의 연속된 토큰을 마스킹하는 wav2vec 마스킹을 적용해서 사전학습 했을 때, 조금 더 좋은 성능을 보이는 것을 확인할 수 있다.
Speech
음성에 대한 배경지식이 부족해서 결과는 생략한다. 음성도 마찬가지로 기존의 벤치마크들에 비해 좋은 성능을 보였다.
5. Ablations
Layer-averaged targets
masked prediction을 할 때, 다른 연구와 차이점은 여러 layer의 출력값을 평균하는 것이다. 저자들은 3가지 모달리티와 \(K=1,...,12\)에 대해 top-K의 출력 평균을 이용해서 학습하고, 성능을 측정했다.
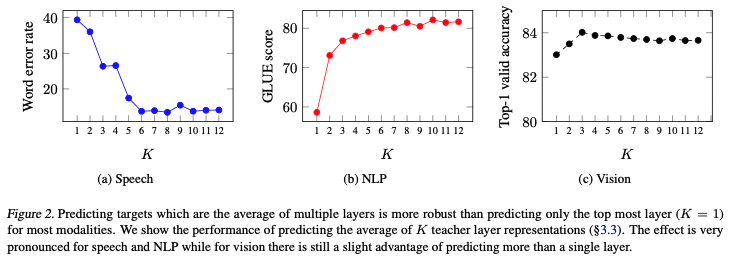
위 그림처럼 모든 모달리티에서 마지막 출력값(\(K=1\))을 이용할때보다 여러 레이어의 평균을 이용했을 때, 더 좋은 성능을 보이는 것을 확인할 수 있다. \(K\)를 튜닝할 것이 아니라면 일반적으로 모든 레이어를 모두 이용하는것이 좋은 선택이 될 수 있다. 현대 뉴럴 넷은 여러 레이어를 거치면서 서로다른 종류의 피쳐를 추출하는데, 여러 층의 출력값을 이용함으로써, self-supervised 태스크를 조금 더 풍부하게할 수 있고 이는 성능 향상으로 이어진다고 볼 수 있다.
Target feature type
Transformer의 각 레이어 블록은 복잡하게 구성되어 있다. 따라서 해당 블록이 만들어내는 출력 값들 중 어떤 값을 타겟으로 이용할지 선택할 수 있다. 저자들은 1) self-attention의 출력값, 2) feedforward network(FFN)의 출력값, 3) FFN + residual(2번 출력에 residual connection을 더함), 4) End of block 3번 출력에 layer normalization 연산을 수행한 결과에 대해 실험을 진행했다.
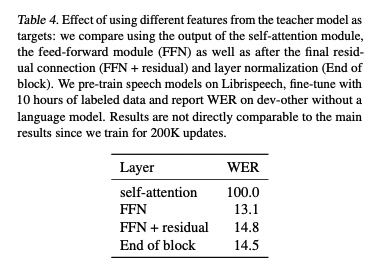
위 표처럼 FFN을 이용하는 경우 성능이 가장 좋았고, self-attention의 경우 이용하기 힘든 성능을 보여주었다. 저자들은 Self-attention 출력은 다른 time-step들에 강하게 bias되어 있어서 이러한 결과가 나타났으며, 이어진 residual connection과 FFN이 이를 완화하는 것으로 언급했다.
6. 마무리
NLP에서 ELECTRA 이후로 self-supervised learning 방법들에 관심을 두지 않고 있었는데, 이 논문을 읽으면서 reference에 등장한 다양한 방법들이 궁금해졌다. 시간이나면 비전 분야도 하나씩 읽어봐야겠다.