
Transformer 구조와 self-supervised learning(pretrian -> finetune) 학습법은 여러 NLP 테스크들에서 표준으로 자리잡고 있음. 이러한 성공에 힘입어, 최근에는 Vision 테스크들 에서도 Transformer 구조를 적용 하려는 시도들이 많이 이루어지고 있음. 이번 글에서는 별도의 Convolution 연산 없이, Transformer 구조 만으로 이미지 인식 문제를 풀고자 했던 “An Image Is Worth 16X16 Words:Transformers for Image Recognition at Scale”를 리뷰함.
1. Main Idea
-
NLP분야에서 Transformer 구조는 하나의 좋은 선택지로 자리 잡았음. GPT-3에서 증명했듯이 이 구조를 이용해 100B개가 넘는 파라메터를 학습했고, 학습에서 계산적인 효율성, 확장성을 증명했음. 본 논문에서는 이러한 구조적 이점을 Vision 테스크로 확장하고자 함.
-
이전에는 Transformer 구조를 직접적으로 이미지에 바로 적용한다기 보다, CNN과 Attention의 결합하는 방향의 연구가 시도되었음. 하지만 이는 구조적 이점을 완전히 이용할 수 없었음. 본 논문에서는 이미지 패치(NxN의 이미지 조각)을 NLP의 토큰과 동일하게 취급하여 직접적으로 Transformer 구조를 이용하고자 했음.
-
충분한 양의 데이터로 사전학습 한 경우, CNN기반의 기존 SoTA 모델들을 뛰어넘는 결과를 보여줌.
2. Vision Transformer(ViT)
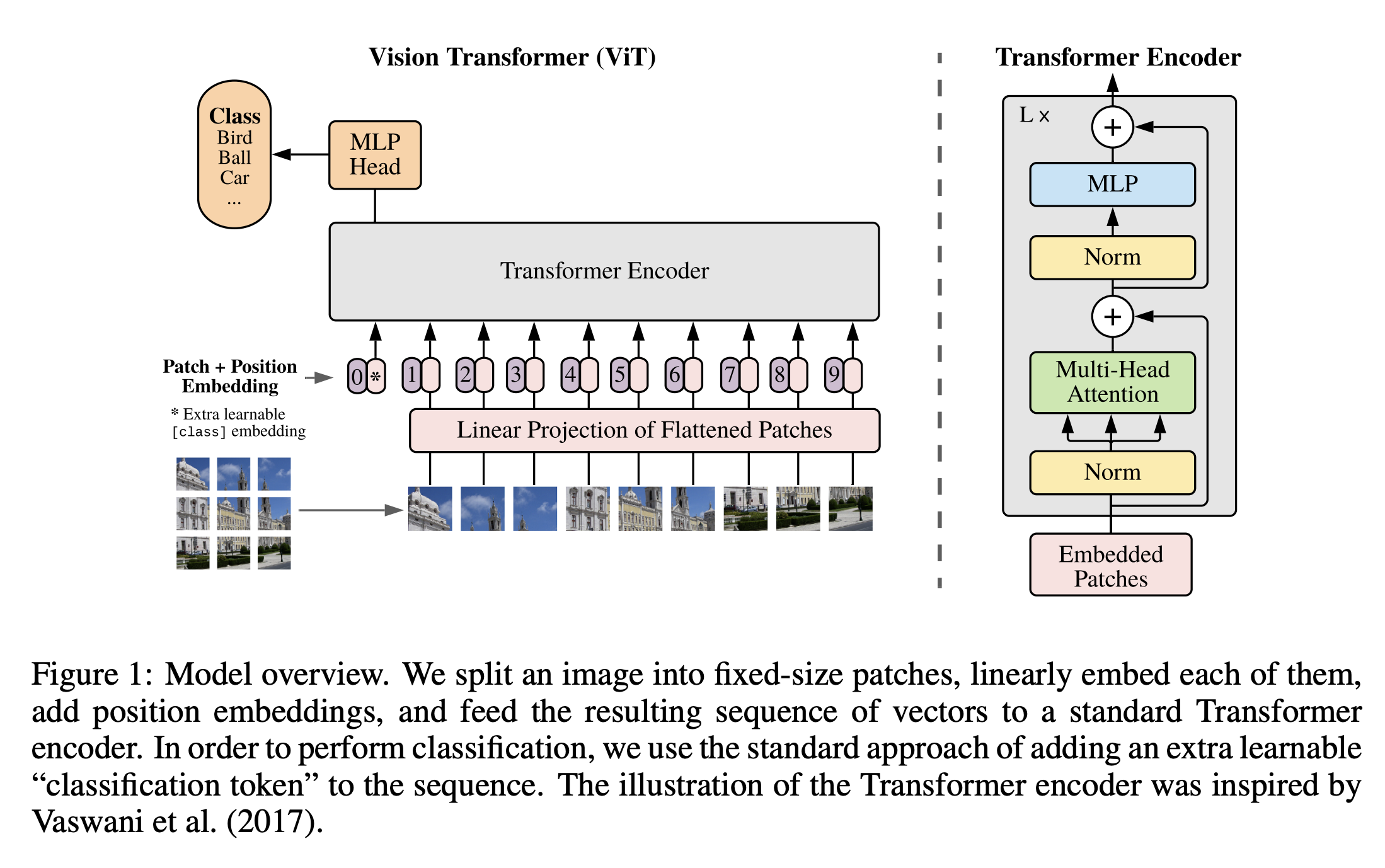
위 그림과 같은 모델 구조를 이용함. 인코더 부분은 기존의 Transformer의 인코더와 완전히 동일하게 Multi-head Attention 연산으로 구성됨. 해당 구조는 입력으로 1차원의 sequence를 입력으로 이용하는데,(NLP에서는 입력 문장/문서를 구성하는 토큰들의 sequence) 이미지 입력을 1차원 sequence를 만드는 방법은 다음과 같음.
아래 그림과 같이, 3차원의 이미지 \(\mathbf{x} \in \mathbb{R}^{H \times W \times C}\) (\(H\): Height, \(W\): Width, \(C\): Channel) 가 있을 때, 이를 2차원의 이미지 패치 \(\mathbf{x}_p \in \mathbb{R}^{N \times (P^2 \cdot C)}\) 로 변경함. \(P\)는 각 패치의 가로/세로에 해당하는 크기, \(N = HW/P^2\) 으로 이미지 패치의 개수이자 입력 sequence의 길이임. (즉 NLP 문장에서 1개의 토큰 == Vision 이미지에서 1개의 패치)
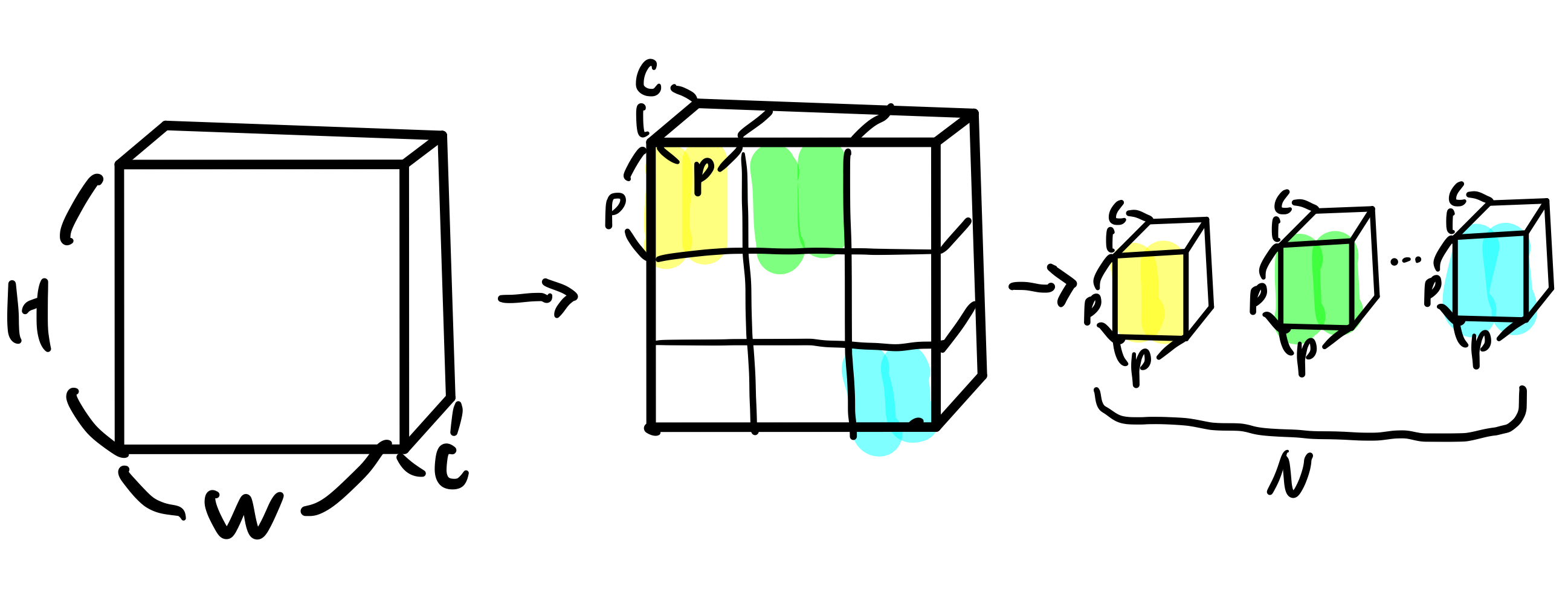
Transformer 인코더는 [batch size, sequence length, hidden size] 과 같은 모양의 입력을 이용함. 이 때, hidden size(\(D\))는 모든 인코더 layer에서 유지되는 latent vector 크기임. 따라서 각 이미지 패치(\((P^2 \cdot C)\))를 학습가능한 파라메터(\(\mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times D}\))를 이용하여 \(D\) 크기의 벡터로 선형 변환함. 이 결과를 patch의 embedding(\(\mathbf{z}_0\))으로 정의함.
BERT의 [Class] 토큰과 유사하게, pretrain, finetuning에서 이미지의 representaiton으로 이용될 학습가능한 임베딩 \(\mathbf{x}_{class}\)을 시퀀스의 첫번째 위치에 추가함.
추가적으로 각 패치의 위치 정보를 제공하기 위해 추가적인 각 위치별로 학습가능한 positional embedding(\(\mathbf{E}_{pos} \in \mathbb{R}^{(N + 1) \times D}\))를 이용함. 저자들은 2D상에서 패치의 상대적인 위치를 인코딩 할 수 있는 positional embedding 방식을 시도해봤지만 눈에 띄는 성능 향상을 관찰하지 못했다고 함.
\[\mathbf{z}_0 = [\mathbf{x}_{class}; \mathbf{x}^1_p \mathbf{E}; \mathbf{x}^2_p \mathbf{E}; ...; \mathbf{x}^N_p \mathbf{E}] + \mathbf{E}_{pos}\]위 과정에서 만들어진 입력(\(\mathbf{z}_0\))이 Transformer 인코더의 입력으로 들어가게 되고, 인코더는 MSA(multiheaded self-attention)과 LN(LayerNorm), MLP(multi layer perceptron, 2-layer GELU non-linearity) residual connection 연산으로 구성됨.(위 그림위 오른쪽) 결과적으로 이미지의 representation(\(y\), 마지막 layer 출력값의 시퀀스에서 첫번째 값)을 얻음.
\[\mathbf{z}'_l = MSA(LN(\mathbf{z}_{l-1})) + \mathbf{z}_{l-1}\] \[\mathbf{z}_l = MLP(LN(z'_{l})) + \mathbf{z}'_l\] \[\mathbf{y}=LN(\mathbf{z}_L^0)\]제안한 논문에서는 hybrid architecture라는 방법으로도 실험을 진행했는데, CNN의 피쳐맵을 Transformer 인코더의 입력 시퀀스로 넣는 방법임. 즉, CNN 위에 Transformer encoder를 쌓은 구조를 이용함.
3. 학습 방식
finetuning 방법: 저자들은 ViT를 large dataset으로 pre-train하고, 이를 작은 downstream 테스크에 파인튜닝 했음. 이를 위해 일반적으로 BERT류의 LM을 이용하는 방법과 동일하게, 사전학습된 ViT의 head를 파인 튜닝용 head로 대체하여 학습을 진행함. (인코더 부분만 이용)
고화질의 finetuning 이미지: 사전학습에 이용된 이미지들 보다 고화질의 이미지를 fine-tuning해야할 상황이 있을 수 있음. Transformer 구조는 입력 시퀀스 길이에 대한 제약이 없기 때문에, 이미지 패치 사이즈를 고정하여 더 긴 이미지 시퀀스를 이용함. 하지만 이 방식을 이용하면, 사전학습때 학습된 position embedding을 이용하지 못함.(시퀀스 길이가 달라지기 때문에) 저자들은 2D interporation 방법으로 원래 이미지의 위치에 따라 사전학습된 position embedding을 늘려줬음.
4. 실험
CNN(ResNet 계열의 기존 SoTA), Vision Transformer(ViT), hybrid 3가지 모델 구조를 비교했음. 각 모델별 사전학습에서 데이터 요구량을 이해하기 위해 다양한 크기의 데이터로 사전학습 -> 평가 진행했음.
4.1. Setup
Datasets
사전학습 데이터
- ILSVRC-2012 ImageNet: 1k-classes, 1.3M
- ImageNet-21k: 21k-classes, 14M, ImageNet을 포함함
- JFT: 18k-classes, 303M 고화질 이미지
- 사전학습 데이터셋과 downstream 테스크의 테스트 데이터셋이 겹치지 않도록 분리함.
파인튜닝 데이터
- ImageNet: 원래의 validation label + 잘 정제된 ReaL label
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- 19-task VTAB classification suite: 테스크 별로 적은 양의 데이터(1000개의 학습셋)가 존재하는 다양한 테스크, 테스크는 크게 3가지 분류로 나뉨.
- Natural: 위의 CIFAR, Pets와 같이 일반적인 데이터셋
- Specialized: medical, satellite 이미지
- Structured: 위치와 같이 기하학적인 이해가 필요한 테스크
Model Variants
1) ViT: BERT의 설정과 유사하게, “Base”(L-12, H-768, A-12), “Large”(L-24, H-1024, A-16)와 추가적으로 더 큰 크기의 “Huge”(L-32, H-1280, A-16)모델을 이용
-
notation:
ViT-{Model Size}/{Patch Scale},Model Size는 B-Base, L-Large, H-Huge,Patch Scale는 Patch Scale * Patch Scale 개의 Patch를 이용.ex) ViT-L/16은 Large size에 입력으로 16*16개의 패치를 이용
2) CNN: ResNet(Batch Normalization -> Group Normalization, standardized convolutions)을 이용. ResNet(BiT)로 표기.
3) hybrids: ResNet50의 intermediate 피쳐맵을 ViT의 입력 시퀀스로 이용.(1 pixel을 하나의 패치로 이용) 여러 시퀀스 길이를 이용하기 위해 두 개의 설정을 이용함.
- ResNet50의 4단계 출력값을 이용
- 4단계를 제거하고 3단계 layer로 대체(1과 같은 layer 수 유지) - feature map의 크기가 커져 총 sequence length가 1에 비해 4배 증가
Training & Fine-tuning
사전학습
- Optimizer: Adam(\(\beta_1 = 0.9\), \(\beta_2=0.999\), weight decay 0.1)
- Batch size: 4096
파인튜닝
- Optimizer: SGD + Momentum
- Batch size: 512
5. 결과
5.1. 기존 SoTA와 비교
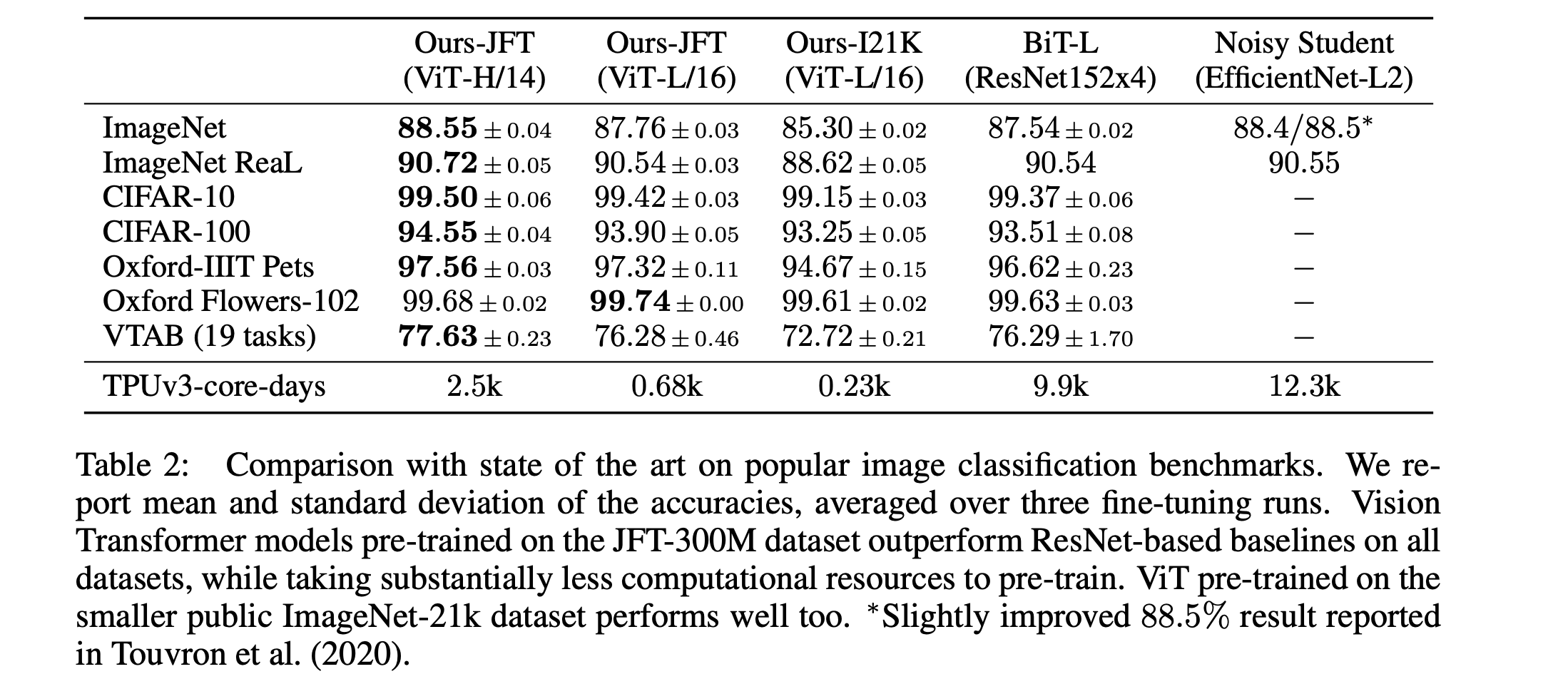
ViT의 가장 큰 두 가지 모델(ViT-H/14, ViT-L/16)을 다른 SoTA모델과 비교함. 비교 대상은 다음과 같은 두 개의 SoTA 방법임, 1) Big Transfer(BiT)라고 표시, ResNet구조로 supervised transfer learning을 함, 2) Noisy Student라고 표시, EfficientNet구조로 label이 제거된 ImageNet, JFT-300M을 이용해 semi-supervised learning함.
위의 표와 같이 JFT로 학습된 ViT-H/14의 경우 모든 데이터셋에서 기존의 SoTA를 능가함. ViT-L/16(JFT)의 경우도 마찬가지로 비슷한 성능을 보임. 하지만 학습시간 같은 경우 Transformer 구조 기반의 ViT의 경우가 훨씬 적게 걸리는 것을 볼 수 있음.
5.2. 사전학습 데이터 요구량
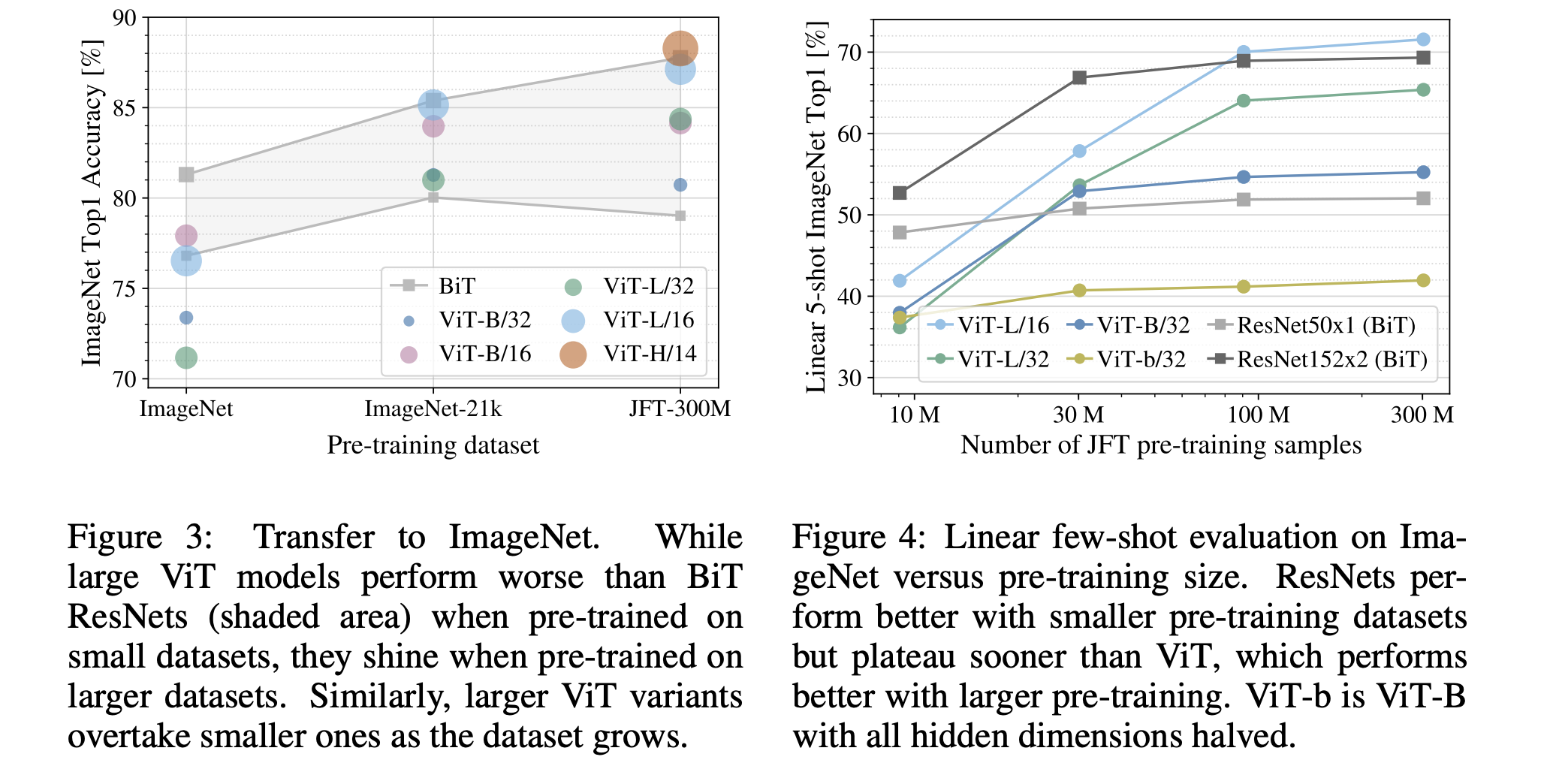
사전학습에 이용하는 데이터 양을 다르게 해가면서 실험결과를 비교했음.
왼쪽 그래프는 Transfer Learning(Fine-tuning)설정의 결과인데, 데이터의 양이 작을 경우(ImageNet) 큰 모델(ViT-L)이 작은 모델(ViT-B)보다 성능이 떨어짐. ImageNet-21k의 경우 ViT-L과 ViT-B가 비슷한 성능을, JFT-300M을 이용했을 때 비로소 ViT-L이 ViT-B보다 좋은 성능을 보여줌. 즉 모델 크기의 이점을 완전히 가져가려면 그만큼 많은 데이터가 필요함.
오른쪽 그래프는 few-shot설정의 정확도인데, 비슷한 경향성을 보여줌. 데이터셋의 양이 적은경우 BiT » ViT이지만 양이 많아지면 ViT의 성능이 우세한 것을 볼 수 있음. 작은 데이터셋의 경우 ViT가 ResNet(CNN)보다 더 빨리 오버핏 되는 경향이 있음. (ViTB/32는 ResNet50보다 9M데이터의 경우 더 빠름.)
결과적으로 작은 데이터셋에서는 Convolution 연산의 inductive bias를 배우는 능력이 유용하지만, 큰 데이터셋의 경우 연관 패턴을 배우는 것만으로도 충분하고, 오히려 유익할 수 있음.
5.3. Vision Transformer 해석
4가지 방법 정도로 Vision Transformer의 결과를 해석했음.
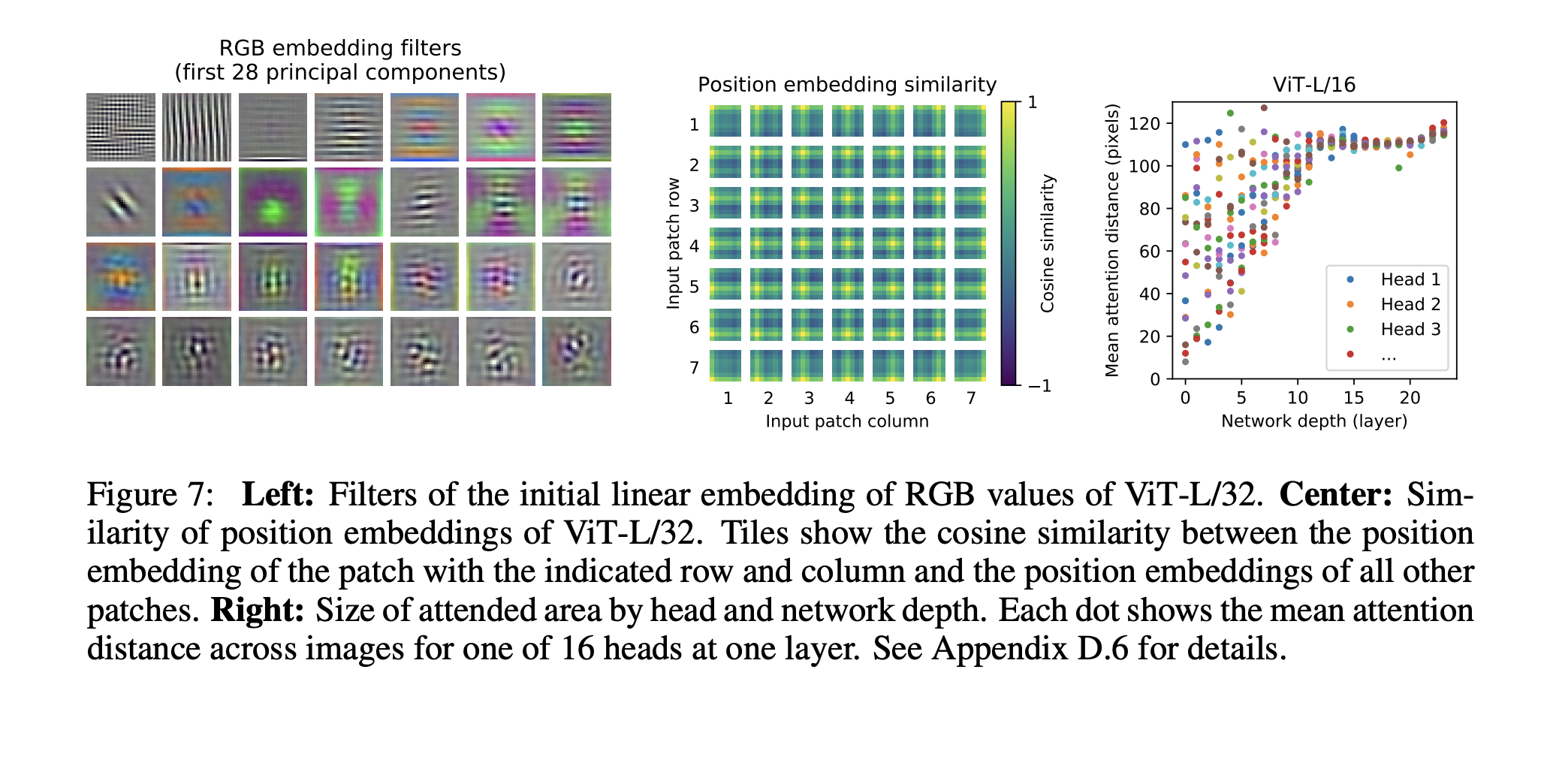
- (위 그림의 왼쪽) 처음 이미지 패치를 Transformer의 입력으로 만드는 임베딩의 경향성을 확인함. 이 임베딩 필터의 상위 principal component를 확인했을 때, 각 패치 내의 구조를 저 차원으로 표현할 수 있는 그럴듯한 기저의 형태를 보임.
- (위 그림의 중간) 학습이 끝난 포지션 임베딩의 경향성을 확인함. 각 패치의 위치에 해당하는 포지션 임베딩을 다른 위치의 포지션 임베딩과 유사도를 구해봤을 때, 가까운 위치일 수록 유사도가 높은 경향이 나타남.(거리의 개념이 인코딩됨.) 또한 해에열의 구조도 나타나는데, 같은 행, 열의 경우 유사도가 높게 나타남.
- (위 그림의 오른쪽) ViT에서 이용된 Self Attention연산은 각 층을 거치면서 입력시퀀스의 정보들을 통합하는 역할을 함. 각 층의 Attention Weight를 이용하여 평균적으로 attend하는 거리를 측정했음.(“attention distance”) 하위 layer는 가까운 거리의 패치를 attend하고 상위 layer는 대부분 먼 거리의 패치를 attend 함. 하지만 몇몇 하위 layer의 head도 모든 이미지 패치들을 attend하는 모습을 볼 수 있음. 이를 통해 실제로 모델에서 (하위 층에서도) 글로벌한 정보를 통합(이용)하도록 의도됨을 알 수 있음.
- (아래 그림) 결과적으로 분류 문제를 풀기 위해 의미적으로 관계있는 부분을 attend하는 경향을 확인할 수 있었음.
