
Language model로 pre-training한 후에 특정 테스크에 적용하는 방법은 상당한 효과를 보여주었습니다. 이를 위해서는 두 가지 전략이 주로 이용됩니다. 첫 번째는 pre-training에서 얻어진 representation을 피쳐로 이용하여 특정 테스크의 모델을 학습하는 방법입니다. 즉 두 모델이 분리되어 있는 ELMo가 해당합니다. 두 번째는 pre-training에서 얻어진 모델을 그대로 이용해서(혹은 일부를 추가/변경해서) 특정 테스크의 데이터로 추가 학습(fine-tuning)하는 방법입니다. 즉 일종의 Transfer learning이라고 볼 수 있고 GPT-1, ULMFit 등이 해당합니다. 이번 포스트에서는 후자의 범위에 속하는 새로운 학습법을 제시한 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding를 리뷰합니다.
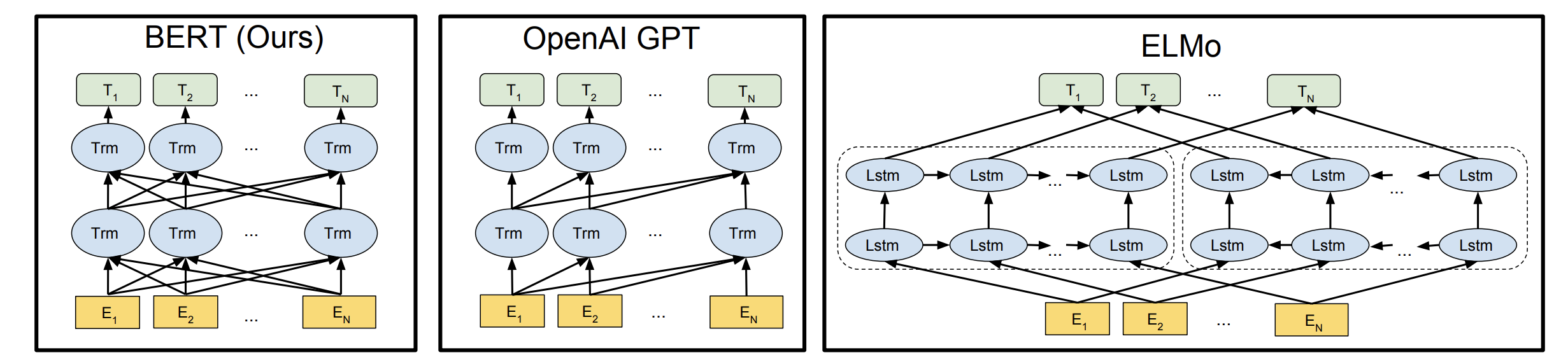
1. Main Idea
“BERT”는 Bidirectional Encoder Representation from Transformer의 약자로, 표현 그대로 pre-training된 양방향 트렌스포머 인코더로 부터 얻어진 representation을 이용하여 특정 테스크를 해결하는 방법입니다. 이때 기존의 Pre-training의 Language Modeling은 단방향 컨텍스트 만을 이용했는데, 이를 해결할 수 있는 “Masked Language Modeling”이라는 새로운 방식의 unsupervised objective를 소개합니다. 여러 문장들 사이의 관계를 학습할 수 있는 Next Sentence Prediction objective 또한 제시합니다. 이를 이용해 많은 양의 코퍼스로 트렌스포머 인코더를 pre-train하고, GLUE를 포함한 여러 NLP 테스크들에서 fine-tuning 하여 대부분의 밴치마크에서 SOTA를 기록했습니다.
2. BERT
2.1. Pre-training Tasks
Task #1: Masked Language Modeling(MLM)
왼쪽(혹은 오른쪽) n개의 토큰들(컨텍스트)를 보고 그 다음 토큰의 확률 분포를 예측하는 일반적인 Language Modeling(LM), \(p(X) = p(x_{< t} \mid x_t)\)은 단방향의 컨텍스트에만 의존합니다. ELMo에서는 정방향, 역방향 각각의 LM을 학습하여 해당 피쳐들을 단순히 합하는 형식으로 양방향의 정보를 얻으려고 시도했으나, 근본적으로 각각의 방향은 한쪽 컨텍스트만 고려할 수 있기 때문에 모델이 이를 제대로 이해하고 있다고 보기 힘듭니다.
이를 해결하기 위해 전체 토큰 시퀀스에서 몇몇 토큰들을 마스킹하고, 그 토큰이 원래 어떤 토큰이였는지 예측하는 문제를 풉니다. 즉 \(p(X \mid \widehat{X})\)과 같이 마스킹된 시퀀스\((\widehat{X})\)가 주어졌을 때, 이를 원래의 시퀀스 \((X)\)로 복구합니다.
Masking 전략
주어진 시퀀스에서 랜덤으로 15%의 토큰을 [MASK]라는 특수 토큰으로 치환합니다. 트랜스포머의 최종 출력 중, [MASK] 위치의 출력 값을 이용하여 해당 토큰이 어떤 토큰일지 예측합니다. 이 때, [MASK]는 pre-training시에만 등장하는 토큰으로, fine-tuning시에는 등장하지 않아 이 두 과정 사이의 불일치 문제를 야기할 수 있습니다. 그래서 마스킹을 하기로 결정한 15%의 토큰에 대해 다음과 같은 전략을 적용하여 이 문제를 해결(완화)하고자 했습니다.
- 80%의 확률로
[MASK]토큰으로 치환:- “나”, “는”, “밥”, “을”, “먹는”, “다” → “나”, “는”,
[MASK], “을”, “먹는”, “다”
- “나”, “는”, “밥”, “을”, “먹는”, “다” → “나”, “는”,
- 10%의 확률로 다른 랜덤 토큰으로 치환:
- “나”, “는”, “밥”, “을”, “먹는”, “다” → “나”, “는”, “책”, “을”, “먹는”, “다”
- 10%의 경우에는 원래 토큰을 유지:
- “나”, “는”, “밥”, “을”, “먹는”, “다” → “나”, “는”, “밥”, “을”, “먹는”, “다”
Task #2: Next Sentence Prediction(NSP)
문장 사이의 관계를 파악하는 것은 많은 테스크들(QA, NLI,…)에서 중요합니다. LM에서 내재적으로 학습할 수도 있지만(기대하기 힘들고), 조금 더 명확하게 이 능력을 학습하기 위해 새로운 objective를 제시합니다. 두 시그먼트(임의의 연속적인 텍스트, 여러 문장이 될 수도 있음.) A,B가 주어졌을 때, 두 시그먼트가 자연스럽게 이어지는지/아닌지를 예측하는 이진 분류 문제를 풉니다.
- Positive 샘플: 50%의 확률로 코퍼스에서 실제로 등장하는(자연스러운) 시그먼트 A-B쌍을 이용합니다.
- Negative 샘플: 50%의 확률로 시그먼트A를 고정하고, 시그먼트B를 코퍼스에서 랜덤으로 샘플링합니다.
2.2. Model Architecture
BERT의 모델 구조는 트렌스포머의 인코더를 동일하게 이용합니다. 이 때, 각 트렌스포머 블록은 양 방향을 모두 attend할 수 있는 Multi-head Attention으로 구성됩니다. 다음과 같이 두 가지 크기의 모델로 실험을 진행했습니다.
- \(BERT_{Base}\): \(L=12, H=768, A=12\) (\(110M\)개의 파라메터)
- \(BERT_{Large}\): \(L=24, H=1024, A=16\) (\(340M\)개의 파라메터)
- \(L\): 트렌스포머 블록 수, \(H\): 각 블록의 hidden 크기, \(A\): 각 블록의 head수
- Position wise Feed-forward layer size: \(4H\)
트렌스포머 인코더 구조는 입력으로 각 토큰의 representation(임베딩) 값을 받아서 각 블록의 Attention 연산을 거친 각 토큰별 (컨텍스트를 고려한) representation을 출력으로 계산합니다. (각 입력 토큰별로 하나의 출력 값을 갖습니다. - I/O의 형식, 차원이 같습니다.)
2.3. Input Representation
pre-training/fine-tuning의 objective를 풀 수 있으면서, 트렌스포머 구조에서 이용할 수 있는 입력의 형태를 다음과 같이 정의합니다.
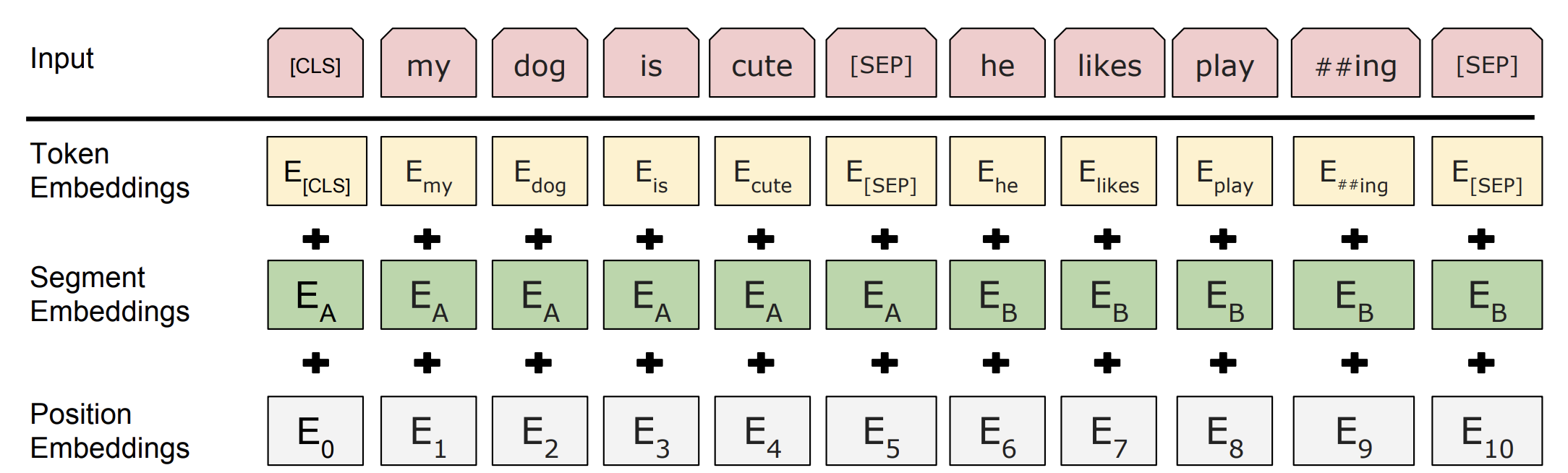
- 위 그림과 같이 트렌스포머 인코더의 입력은 토큰 임베딩, 시그먼트 임베딩, 포지션 임베딩값들을 더한 값입니다. 각 임베딩들은 모두 학습 가능한 임베딩 lookup테이블로 구성되며, 동일한 차원을 가지기 때문에 더하는 연산이 가능합니다.
- 토큰 임베딩은 사전에 정의된 30000 Vocab의 토큰들 중 하나의 임베딩을 갖습니다. 즉 \([30000 \times 768]\)의 테이블을 lookup하여 해당 토큰의 임베딩 값을 얻을 수 있습니다.
- BERT는 기본적으로 여러 테스크들(pre-training에서 NSP, fine-tuning에서 QA, NLI 등)의 학습을 고려하여 두 시그먼트를 입력으로 받습니다. 이 때 모델이 각 시그먼트를 분리해서 이해할 수 있도록 각 시그먼트 의 마지막에 특수토큰
[SEP]을 추가하고, 시그먼트 임베딩(시그먼트A/시그먼트B에따라 다르게 부여되는 임베딩)을 이용합니다. 각 시그먼트에 따라 \([2 \times 768]\)의 테이블을 lookup하여 임베딩 값을 얻을 수 있습니다.- 시그먼트의 정의는 임의의 연속적인 텍스트입니다. 경우에 따라 한 문장으로 구성될 수도 있고, 한 문단 전체가 될 수도 있습니다. BERT의 공식 구현체를 보면, 랜덤으로 시작점/끝점을 정하는 로직을 확인할 수 있습니다.
- 포지션 임베딩은 “Attention is All You Need”에서 트렌스포머 구조와 함께 소개된 방법입니다. 트렌스포머 구조는 어텐션과, 위치 단위의 feed-forward 등의 연산으로 구성되어 그 자체로 위치에 대한 정보를 얻을 수 없습니다. 따라서 해당 논문에서는 위치에 대한 정보(포지션 임베딩)를 임베딩 값에 추가적으로 더해줍니다.
- 위 논문에서는 위치에 따라 다른 주파수의 사인\((sin)\)/코사인\((cos)\) 함수를 이용했지만, BERT에서는 각 위치별로 학습가능한 파라메터(\([Max \space length(512) \times 768]\)임베딩 테이블)로 두고 학습했습니다.
- 또한 텍스트 분류 문제(Pre-training에서 NSP, fine-tuning에서 GLUE에 속한 테스크들)를 풀기 위해서 모든 입력 시퀀스의 첫 번째 토큰은
[CLS]로 통일합니다. 이 토큰의 최종 출력 representation을 이용해 분류 문제를 풉니다.
2.4. Pre-training
데이터
BookCorpus(800M 단어)와 영어 위키피디아(2500M 단어)를 이용하여 학습을 진행했습니다. 입력의 형식은 [CLS] + Segment_A + [SEP] + Segment_B + [SEP]로 NSP와 MLM을 함께 학습할 수 있도록 구성됩니다. 각 시그먼트는 50%의 확률로 positive/negative 샘플로 구성되며, 기본적으로 최대 길이(512)를 채운 입력을 만들지만 fine-tuning에서 입력이 짧을 수 있는 점을 감안해 10%의 확률로 최대 길이보다 짧은 입력을 만듭니다.
학습 하이퍼 파라메터
- 배치 사이즈: 256 → \(256 \times 512(max \space length) = 12800(tokens/batch)\)
- Optimizer: Adam(\(lr=1e-4, \beta_1=0.9, \beta_2=0.999, L2 \space weight \space decay=0.01\))
- LR Scheduler: 10000 step까지 warm up후 linear deacay
- Dropout: 모든 layer에 0.1로 부여
- Activation: gelu(Gaussian Error Linear Unit)
학습 과정
위에서 제시한 두 가지 Objective를 동시에 학습합니다.
- 마스킹이 된 두 개의 시그먼트가 입력으로 주어집니다.
- 트렌스포머 인코더를 이용해 해당 입력을 인코딩합니다.
[CLS]토큰의 representation을 이용해 두 시그먼트가 자연스러운지(NSP)를 예측하고 loss를 계산합니다.- 각
[MASK]토큰 위치의 representation을 이용해 원래 어떤 토큰인지(MLM)를 예측하고 loss를 계산합니다. - 두 loss를 동일한 비율로 더해 최종 loss를 계산하고, backpropagation으로 학습을 진행합니다.
2.5. Fine-tuning
학습 하이퍼 파라메터
대부분 pre-training과 동일하게 유지했고 변경점은 다음과 같습니다.
- 배치 사이즈: 16, 32
- learning rate: 5e-5, 3e-5, 2e-5
- Epoch: 3, 4
위의 세 가지 하이퍼 파라메터 중 각 테스크 별로 가장 성능이 좋은 설정으로 이용했습니다. 실험 결과 데이터의 양이 많은 테스크의 경우 하이퍼 파라메터의 영향을 크게 받지 않았다고 합니다.
학습 과정
트랜스포머 최종 출력 representation을 이용해 fine-tuning을 진행합니다. 테스크의 종류에 따라 출력 값들 중 일부를 이용합니다.(위에서 잠깐 언급했듯이 트렌스포머 인코더는 입력으로 주어진 각 토큰별로 하나의 출력을 갖습니다. - 아래 그림의 \(C, T_1, ... T_N\))
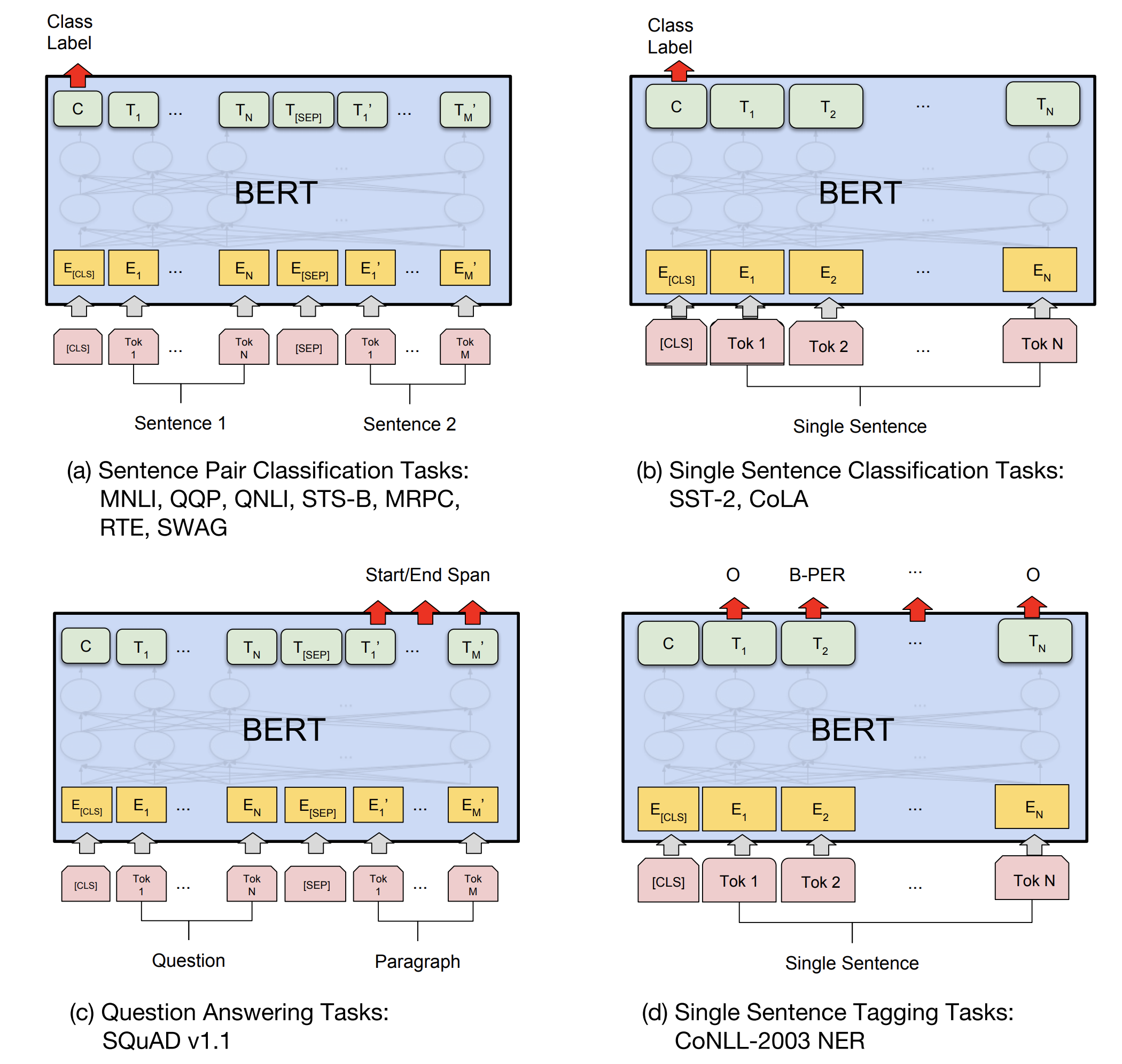
- 텍스트 분류 문제(위 그림의 상단): pre-training의 NSP와 동일하게
[CLS]토큰의 representation을 이용해 분류 문제를 풉니다. 이 때 문장 쌍에 대한 테스크(STS, NLI 등)는 두 개의 시그먼트로 구성된 입력([CLS]+Segment_A+[SEP]+Segment_B+[SEP])을, 단일 문장에 대한 테스크(SST, CoLA 등)는 하나의 시그먼트로 구성된 입력([CLS]+Segment_A+[SEP])을 이용합니다. - Span-level의 예측 문제(위 그림의 좌측 하단): SQuAD와 같은 QA는
본문과질문을 주고 해당 질문에 대한 답을 본문에서 찾는 문제입니다.(주로 정답의 시작 index와 끝 index를 예측합니다.) 이 경우 질문과 본문을 각 시그먼트에 대응시킨[CLS]+질문+[SEP]+본문+[SEP]와 같은 입력의 형식을 이용합니다. 그리고 정답의 시작점을 예측하는 분류기, 정답의 끝점을 예측하는 분류기를 이용해본문에 해당하는 최종 representation들(위 그림에서 \(T_1', ... T_M'\))을 시작/끝점으로 분류합니다. (inference시에는 시작점이 끝점보다 앞에 있어야 하는 제약사항 들을 추가적으로 이용합니다.) - Token-level의 예측 문제(위 그림의 우측 하단): NER(Named Entity Recognition, 각 토큰이 어떤 Named Entitiy에 속하는지 분류하는 문제)과 같이 각 토큰별로 예측을 해야하는 문제는 각 토큰별 최종 출력(\(T_1, ... T_N\))을 이용합니다.
3. Experiment & Result
3.1. BERT vs Open AI GPT
BERT와 GPT는 다음과 같은 차이점을 갖습니다.
- Pre-training Objective: Pre-training단계에서 BERT는 MLM + NSP를 학습했고, GPT는 일반적인 Auto Regressive Language Modeling을 학습했습니다.
- 학습 데이터: BERT는 BookCorpus + Wikipedia를 이용했고, GPT는 BookCorpus만 이용했습니다.
- 특수 토큰: BERT는 pre-training에서부터
[CLS],[SEP]를 이용했고, GPT는 fine-tuning에서만 이용했습니다. - 학습량: BERT는 128000 tokens/batch 로 1M 스텝을 학습했고, GPT는 32000 tokens/batch로 1M 스텝을 학습했습니다.
- Fine-tuning Learning rate: BERT는 테스크에 따라 변화시켜가며 실험했고, GPT는 5e-5로 고정했습니다.
3.2. GLUE Result
GLUE(General Language Understanding Evaluation)는 다양한 Natural Language Understanding 테스크들을 모아놓은 벤치마크입니다. 각 테스크에 해당하는 학습/검증셋을 제공하고, 평가를 위한 테스트 서버를 제공합니다. 이를 통해 테스트에 일관성을 부여하고, 테스트 셋에 오버피팅 되는 것을 막을 수 있습니다.
논문에서는 GLUE 에 포함되는 9개의 데이터셋에 대해 BERT(Base, Large) 모델로 실험을 진행하였습니다. 결과는 아래 표와 같으며, 모든 테스크에서 두 모델 모두 기존의 성능을 크게 뛰어넘는 결과를 달성했습니다. 특히 BERT Large는 모든 테스크에서 BERT Base를 뛰어 넘으면서 모델 크기의 효과를 보여줍니다.
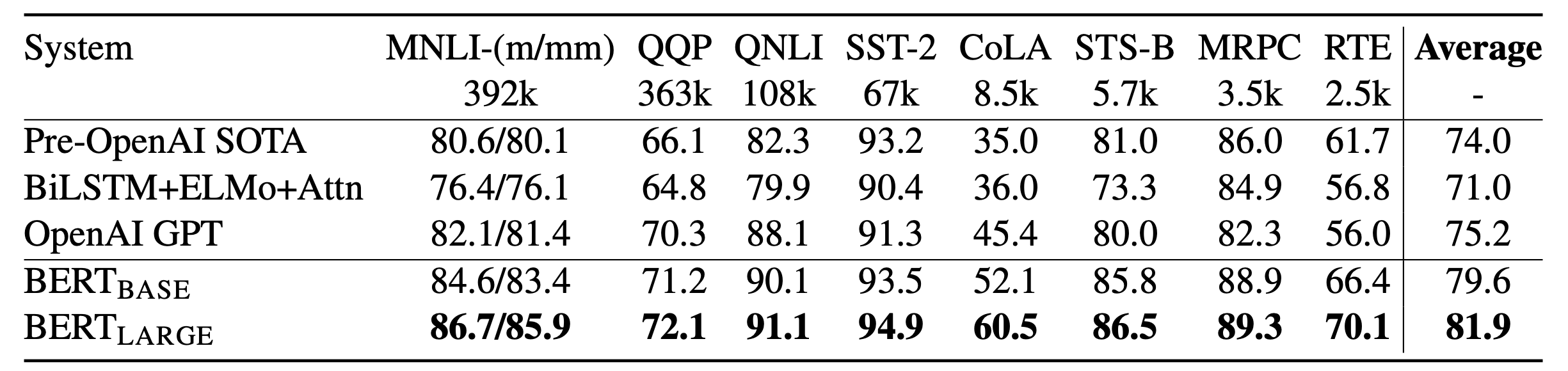
GLUE 뿐만아니라 SQuAD, NER, SWAG등의 데이터셋에서도 기존의 성능을 뛰어넘는 결과를 얻었습니다.
3.3 Ablation Study
Pre-training task
제시한 pre-training 테스크들의 효과를 증명하기 위해 다음과 같이 두 가지 설정의 실험을 추가로 진행했습니다.
- No NSP: MLM만 학습하고, NSP는 학습하지 않음.
- LTR & No NSP: GPT와 동일하게 left-to-right Language Model을 이용, NSP도 학습하지 않음.
- (+) BiLSTM: 위 설정의 최종 출력값을 BiLSTM에 통과시켜 이를 fine-tuning에 이용함. (최종 예측시에 양 방향의 정보를 모두 이용하기 위해서)
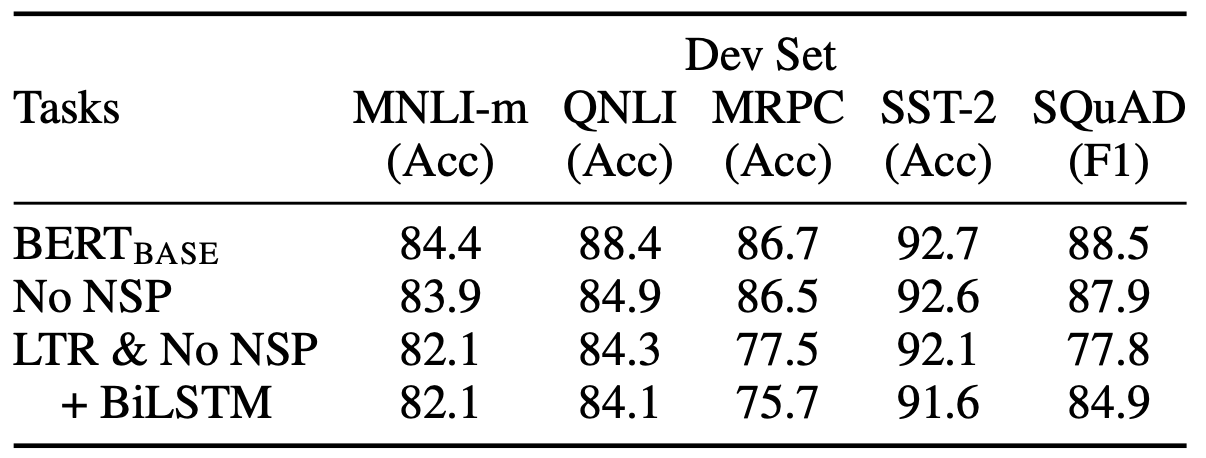
- No NSP vs BERT_Base(NSP 유무에 따른 비교): A,B Sentence 간의 관계정보가 중요한 QNLI, MNLI, SQuAD에서는 큰 성능차이를 보입니다. → NSP pre-training는 시그먼트 사이의 관계정보가 중요한 테스크에서 큰 영향을 준다. (하지만 후속 논문들에서 이 실험 설정에서 데이터 형식을 유지한체 NSP만 제거했기 때문에 이와 같은 결과를 얻었다고 증명됨.(RoBERTa))
- No NSP vs LTR & No NSP(MLM 유무에 따른 비교): 모든 테스크에서 성능 차이를 보이나 특히 span-level 테스크인 SQuAD에서는 큰 폭의 차이가 발생합니다. → No NSP의 경우 최종 출력이 오른쪽 컨텍스트를 이용하지 못하기 때문에 성능이 떨어지는 것은 당연한 결과입니다. MRPC는 성능 차이의 명확한 이유를 찾기 힘든데, 데이터셋의 크기/테스크의 특성등으로 추측됩니다.
- (+) BiLSTM(token-level 테스크에서 MLM유무의 비교적 공정한 비교): BiLSTM을 통해 양방향 컨텍스트를 이용할 수 있어서 추가하기 이전보다는 SQuAD에서 큰 성능향상이 있었으나 여전히 No NSP보다 낮은 성능을 보입니다. 그리고 기존 GLUE Task의 성능은 오히려 떨어지는 모습을 관측할 수 있습니다. → 양 방향 컨텍스트를 학습하기 위해서는 MLM이 LTR + BiLSTM에 비해 좋은 성능을 보입니다.
Model Size
모델 크기에 따른 성능을 비교하기 위해 모든 학습 파라메터를 고정하고, 다음과 같이 모델 크기만 다르게 하여 실험을 진행합니다.
- \(L\): 트렌스포머 블록(layer)의 수
- \(H\): 각 트렌스포머 블록의 hidden 크기
- \(A\): 각 트렌스포머 블록의 head 수
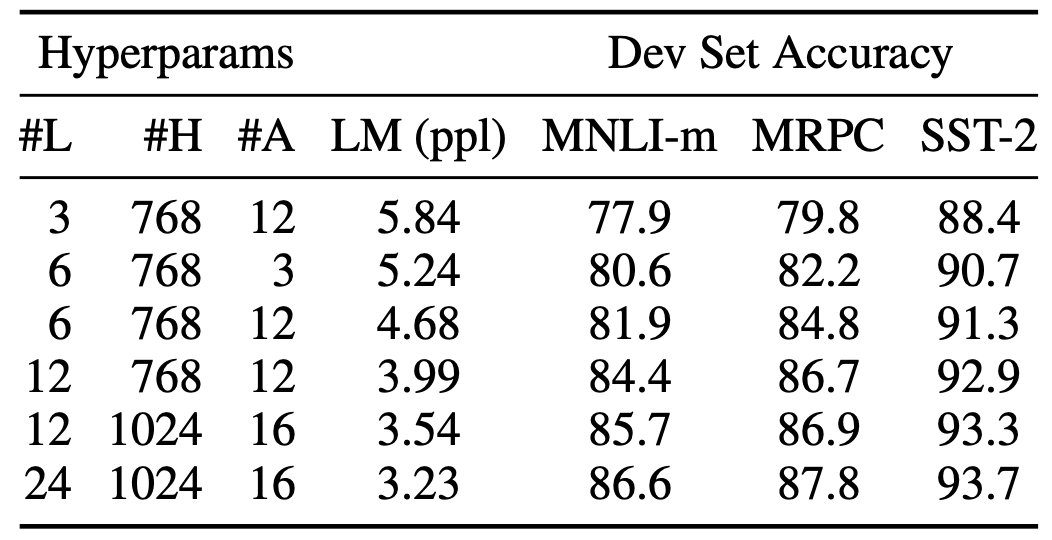
위 표와 같이 모델 사이즈가 클수록 더 좋은 성능을 보여줍니다. 이전 연구들에서 데이터가 많은 테스크들에서는 모델이 커질수록 성능이 향상되는 것을 증명했습니다. 하지만 데이터가 적은 경우, 오버 피팅 등의 문제로 모델의 크기가 커져도 성능 향상을 보장할 수 없었습니다. 위 표의 MRPC의 경우 3600개의 데이터만 존재함에도 불구하고, 모델 크기가 커질수록 성능이 좋아짐을 볼 수 있습니다. 따라서 적은 양의 데이터를 가진 테스크들도 충분한 pre-training과정을 거친 후에 fine-tuning한다면 모델 크기의 이점을 가져갈 수 있다는 것을 증명했습니다.
Pre-training Step
각 LTR과 MLM의 각 pre-training 스텝별로 fine-tuning을 진행하고 결과를 확인합니다.
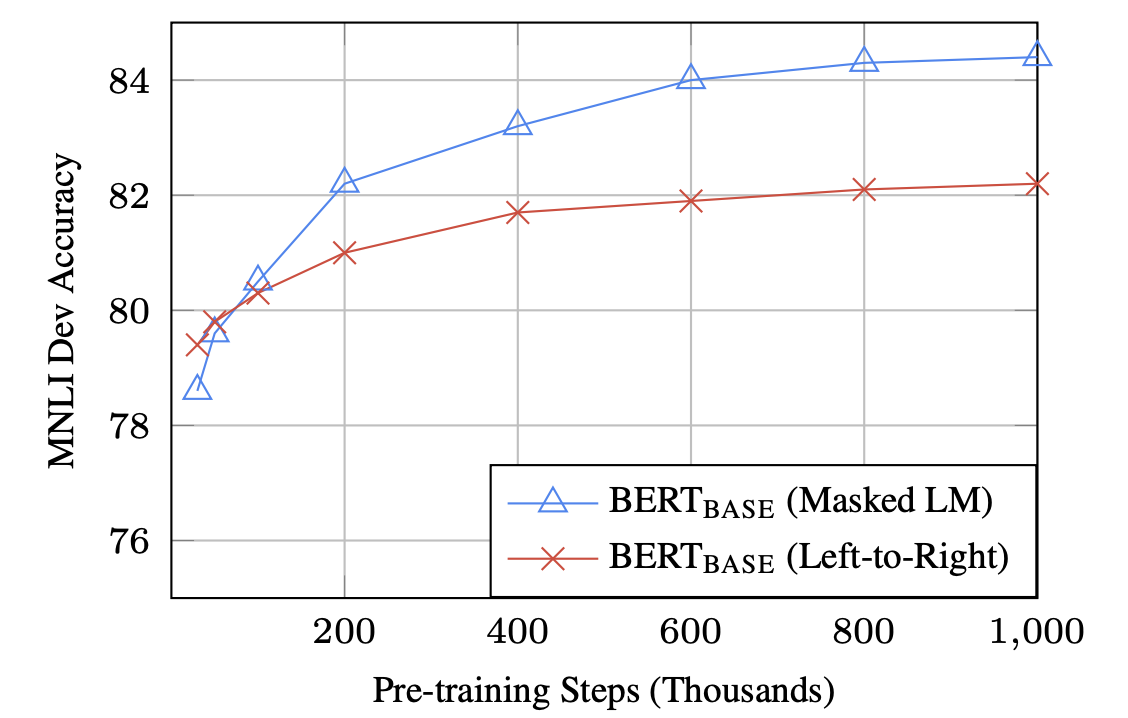
Pre-training 스텝이 많아질수록 fine-tuning 성능이 좋아집니다. 또한 MLM이 LTR에 비해 pre-training 단계의 수렴은 느리지만, finr-tuning테스크에서는 초반부부터 즉각적으로 높아지는 것을 볼 수 있습니다.
4. Reference
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep idirectional transformers for language understanding. In Proceedings of the 2019 Conference of he North American Chapter of the Association for Computational Linguistics(NAACL), 2018.
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems(NeurIPS), 2017.