
이전 글에서 Alexa Prize에 대해 간단하게 살펴봤는데, 이 글에서는 Socialbot challenge 2017의 우승작 Sounding Board – University of Washington’s Alexa Prize Submission을 리뷰해보려고 합니다. 현재 많은 챗봇들은 대화를 통해 특정 도메인의 문제(영화 추천/예매 봇 등)를 해결하기 위한 task-oriented 문제를 풀고 있습니다. 이 경우 대화의 범위(주제)가 좁혀짐으로써 비교적 잘 정의된 방법론들이 존재합니다. 이에 비해 open-domain 대화 시스템이란 “도메인이 열려있는”, 즉 주제에 제한이 없는 대화를 다루는 시스템이기 때문에 해당 접근법들로 풀기에는 여러 한계를 갖고 있습니다. Alexa prize는 소셜봇이 유저와 다양한 주제에 대해 대화를 진행하는 첼린지 이기 때문에 어느 정도 open-domain의 성격을 갖고 있습니다. 하지만 주제의 큰 영역들이 사전에 정해져 있고, 기존의 Alexa 시스템 자체가 특정 기능을 수행하는 목적을 갖고 있기 때문에, 완전히 open-domain 환경이라고는 볼 수 없습니다. 이에 따라 Sounding Board 팀은 task-oriented 문제로 해결하되 컨텐츠(정보)와 유저의 흥미를 집중적으로 고려하여 대답을 생성하는 접근법을 시도했습니다. 크게 Sounding Board 라는 소셜봇을 만들 때 고려된 디자인 철학과, 전체적인 구조와 상세 모듈들, 저자들의 분석에 대해 살펴봅니다.

1. Design Philosophy
Sounding Board의 디자인 철학은 대화 전략 및 시스템 엔지니어링에 반영되어 있습니다. 특히 대회 이전에 만들어 두었던 대화 시스템이 없었고 뉴럴넷을 학습시킬 데이터도 없는 환경이였기 때문에, 초기 시스템은 간단하게 구현하고 실 사용자와의 대화 데이터를 축적하면서 복잡한 구조와 머신러닝을 사용하는 방향으로 발전시켰습니다. 대회를 진행하면서 얻을 수 있는 사용자 피드백은 시스템 구조 결정에 있어서 큰 영향을 미쳤습니다. 대화 전략은 다음과 같이 두 개의 특징을 갖습니다.
contents driven: 사용자가 알지 못하거나 들어보지 못했을 관점의 정보를 제공하고, 이를 통해 사용자를 사로잡고자 했습니다. 따라서 정보 검색(Information retrieval)의 중요성이 높고, 다양한 범위의 토픽, 사용자의 흥미를 다룰 수 있도록 여러 개의 정보 소스를 이용했습니다. chit-chat은 일부 포함되어 있으나 주로 대화를 부드럽게 진행시키는 역할을 수행합니다.user driven: 사용자의 상태를 적극적으로 트래킹합니다. 발화의 감정, 태도, 의도 등을 다차원 표현으로 나타내고, 성격 퀴즈, 불만 감지 등을 통해 사용자의 상태를 지속적으로 인식하면서 대화를 진행하고자 했습니다.
시스템 엔지니어링 전략은 여러개의 컨텐츠 소스들을 적절히 이용하고자 했던 점, 학습을 위한 적절한 대화 데이터가 부족한점이 주로 고려되었습니다. (따라서 end-to-end generation 시스템 등은 시도하지 않았습니다.) 이에 따라 새로운 능력을 추가하고 기존의 기능을 업데이트하는 것이 쉬운 계층적이고 모듈화된 구조를 통해 대화 관리를 하는 전략을 선택했습니다. 발화 생성 또한 모듈화 되어있어, 여러 모듈들이 speech act에 따라 답변을 생성합니다. 몇몇 생성 모듈에는 여러가지 변형들 중 답변 형식을 선택하는 랜덤성을 부여하는 방식으로, 대화의 단조로움을 피하고 유의미한 대화 데이터를 축적하도록 의도했습니다.
2. System Architecture
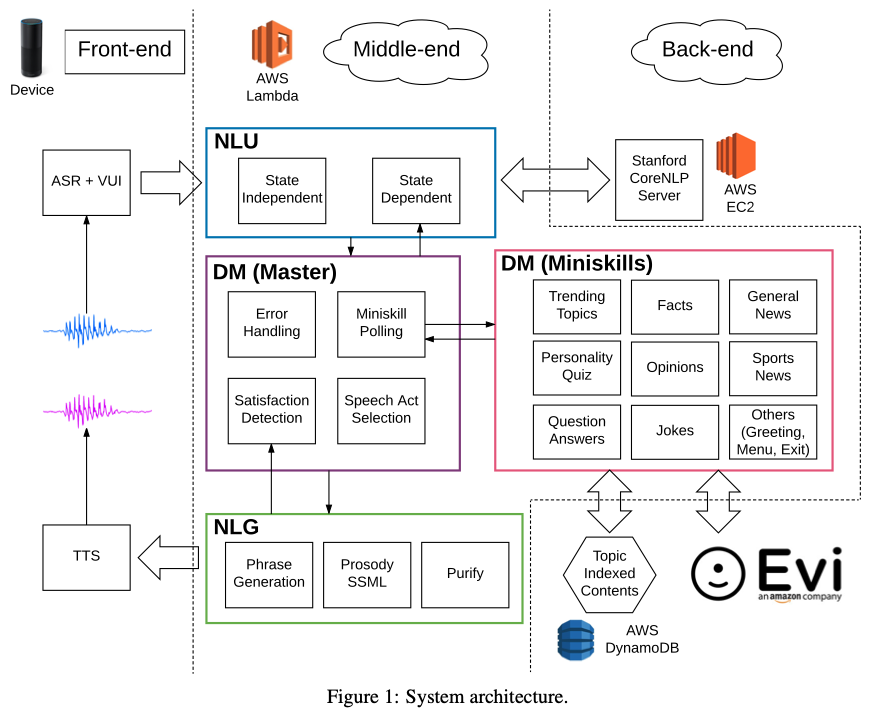
위 그림과 같이 프론트 엔드, 미들 엔드, 백 엔드로 구성되며, 이들 또한 각각의 세부 구성 요소들로 나눠지는 모듈화된 구조입니다.
-
프론트 앤드: 유저와 소통하는 부분으로, Sounding Board는 Alexa Skill Kit(ASK)에 포함된 음성 인식(Automatic Speech Recognition - ASR), 텍스트-음성 변환(Text-to-Speech TTS)을 이용합니다.
-
미들 엔드(AWS Lambda 서비스 이용): 다양한 대화 전략을 가지고 유저의 발화에 대한 답변을 생성하는 부분으로, 크게 Natural language understanding(NLU), Dialogue management(DM), Natural language generation(NLG) 3개의 주요 시스템 모듈로 구성됩니다. 각 모듈에서 필요시 백앤드와 통신합니다.
-
백 엔드: 각 대화 전략에서 이용할 수 있는 데이터와 정보를 제공하는 부분으로, 파싱 서비스를 제공하는 스탠퍼드 CoreNLP, 토픽으로 인덱싱된 컨텐츠가 저장되어 있는 AWS DynamoDB, QA, 조크 서비스를 위한 Evi.com 등으로 구성됩니다.
Alexa Prize라는 특수한 환경이기에 필수적인 모듈들을 제외하면, Sounding Board팀의 전략은 미들 엔드의 NLU, DM, NLG 모듈들에 의해 구현되었습니다. 대화가 진행되는 과정은 다음과 같습니다.
- 유저가 말을 하면 ASR의 인식 내용, Voice User Interface의 결과를 얻습니다.
- 이 정보들과 현재의 dialogue state를 바탕으로 NLU가 DM의 입력으로 이용될
입력 프레임을 만듭니다. - DM은 이 프레임을 이용하여 대화 전략을 실행하여 Speech act와 컨텐츠를 결정하고, dialogue state를 업데이트 합니다.
- NLG모듈은 DM의 결과물들을 이용해 답변을 생성하고, ASK에 반환합니다.
2.1. Natural language understanding

NLU는 표현 그대로 언어를 이해하는 기능을 수행합니다. 프론트에서 제공되는 정보들로 부터 화자의 발화를 이해하고 의도 혹은 목적, (잠재적인) 토픽, 감정, 스텐스 등 여러 타입의 정보들을 추출하여 input frame으로 만드는 모듈입니다. 이는 위의 표와 같이 크게 5개의 attribute로 구성됩니다.
문어체에서는 Ganeral Language Understanding Evaluation(GLUE) 등 자연어 이해 관련 테스크들이 비교적 잘 정리되어 있지만, 대화체에서는 여전히 정의되지 않은 테스크들이 많고 분산되어 있는것 같습니다. 본 논문에서도 아래와 같이 주어진 환경에 맞춰 여러 NLU 피쳐들을 정의하고 이를 통해 발화를 표현하고자 했습니다.
입력: 프론트 엔드의 ASK로 부터 얻을 수 있는 정보들입니다.
ASR hypotheses: Autometic Speech Recognition 모듈의 결과VUI output: Voice User Interface 의 결과Dialogue State: 현재 까지 저장된 대화의 상태(대화가 진행됨에 따라 DM에서 지속적으로 업데이트 됨.)
출력: 위 입력으로 5개 타입의 정보를 추출하여 input frame을 만듭니다.
primaryIntent- DM의 대화 전략을 결정하는데 사용하기 위해, 유저 발화의 의도를 22개로 구분합니다.
- 크게
contents retrieval commands,nevigation commands,common Alexa commands,converse intent의 4종류로 구분됩니다. contents retrieval commands:popular topics,facts,opinions,jokes,general news,sports news,personality quiz,question answers,unspecified의 9종류가 있습니다. 유저의 발화가 특정 컨텐츠를 요구할 때 컨텐츠의 종류에 따라 이 중 하나로 매핑됩니다.navigation commands: 인간과 봇의 대화이기 때문에, 사용자가 봇에게 명령을 내릴 수 있는데,help,repeat,next,cancel등이 해당됩니다.standard Alexa command: Alexa가 기본적으로 지원하는 기능에 대한 명령입니다. 8개의 Amazon의 built-in 의도들(“음악 켜줘”, “책 읽어줘” 등의 발화)에 해당됩니다. Sounding Board는 이에 대한 권한이 없기 때문에, 이러한 커멘드가 감지되면 제약사항과 지침에 대해 응답합니다.converse intent: 위의 커멘드들이 아닌 나머지 모든 발화들에게 할당하는 의도입니다. 일반적으로 일상대화에서 이용되는informing,decision/answer,expressing opinions/feelings,asking questions, 등이 해당합니다. 이 의도들 중 대부분은 이전 턴들을 참조해야 하기 때문에, 컨텍스트 또한 의존관계가 있습니다.
questionType- 유저 발화의 질문 종류입니다. 저자들은 다양한 유저 대화 분석을 통해, 대부분을 질문은 4가지 유형 중 하나로 대응시킬 수 있다는 결론을 내렸습니다. 이들은 DM에서 각각 다른 전략으로 다뤄집니다.
command: 정중한 방식(질문 형태의) 명령입니다. - “우리 Mars mission에 대해 이야기 해볼까?”backstory/ personal question: socialbot의 페르소나에 관한 질문입니다. - 이름, 생일, 취미 등등factual quesion: 사실에 근거한 명확한 답이 있는 질문입니다. - “미국의 대통령은 누구야?”question on sensitive topics, advice questions: socialbot이 대답하기 민감하거나 할 수 없는 성이나 폭력성, 마약 등에 관련된 질문들과 “내가 어떤 주식을 사야할까?” 등의 어려운 질문입니다.
-
candidateTopics: 토픽의 후보들입니다. 모든 명사구가 토픽이 될 수 있다고 가정하고, 파싱 결과에서 모든 명사구를 저장합니다. 그 후에 적절하지 못한 토픽(“this”, “yep”, “something” 등)과 민감한 토픽을 제거합니다. 토픽의 다양화를 위해primaryTopic에 대한 컨텐츠 부족 등의 문제에 대응하기 위해 후보들을 유지합니다. primaryTopic: 대화의 주 토픽입니다.VUI에서 인식된 토픽이 있다면 해당 토픽이 선택됩니다. 그 외의 경우, 가장 긴 명사구가 선택됩니다.- 긴 명사구일 수록 구체적인 토픽일 것이고, 주 토픽일 가능성이 높을 수 있지만 각 명사구의 의미와 관계 없이 길이로만 결정하기 때문에 나이브한 접근인 것 같습니다. 그러나 2017년이라 만족스러운 기술이 없었거나, 이 방법으로도 충분히 잘되었기 때문에 이 방법을 이용했을 수도 있을 것 같습니다.
userReaction: 소셜봇이 컨텐츠를 제공했을 때, 유저들은 이에 대한 답변(리엑션)에서 감정을 표현하거나 긍정 혹은 부정적인 스텐스로 반응할 수 있습니다. 리엑션을 3개의 차원으로 나누가 각 차원의 정도를 분류하는 3개의 리엑션 분류기를 만들었습니다.- 확인에 대한 사용자의 반응: 승인, 거부, 확실하지 않음,
null - 의견적인 부분에서 유저의 스텐스: 동의, 동의하지 않음, 확실하지 않음,
null - fake나 joke에 대한 사용자의 감정: 호/불호, neutral,
null null은 classifier의 컨텍스트와 일치하지 않는 경우에 매핑됩니다. - 확인 질문이 아닌경우 첫번째 분류기는null, 인식기가 오류인 경우 등
- 확인에 대한 사용자의 반응: 승인, 거부, 확실하지 않음,
2.2. Dialogue management
DM은 전체적인 대화의 흐름을 관리하는 모듈입니다. NLU에서 얻은 사용자 발화에 대한 이해(input frame)를 바탕으로 “어떤 내용”을 이용해서 “어떤 전략”으로 대응할지 결정합니다. Sounding Board에서는 계층적 구조를 갖고, state에 기반해서 대화를 관리합니다. state는 상호작용의 타입, personality quiz의 결과, 이전에 다뤄졌던 컨텐츠에 대한 기억 등 이산적인 요소들의 집합입니다.
계층적 구조는 대화를 전체적으로 관리하는 마스터 프로세싱 - 상위레벨와 대화의 각 시그먼트를 다루는 미니스킬(대화 모드) - 하위 레벨로 구성됩니다. 이러한 구조를 통해 새로운 능력을 추가하는 과정이 쉬워지고, 상위 레벨에서 대화 모드의 잦은 변동을 다루기에 유용합니다. 마스터 프로세싱에서는 유저의 의도/토픽 제약조건을 만족시키는 미니 스킬을 결정하고 미니스킬에서는 NLG 모듈에서 발화를 생성하기 위해 이용될 speech act를 만듭니다. 또한 현재 대화를 바탕으로 state의 변화를 업데이트 합니다.
마스터 프로세싱: 대화 시그먼트가 명확히 초기화 되는 경우(명확한 토픽 요청, 다른 명령 타입으로 전환 등)에 따라 기존의 state를 이용할지 결정합니다. 각각의 경우 모두 제약조건(사용자 의도/토픽)을 만족하는 미니스킬을 선택합니다. 이 때 가장 자세한 토픽에 대응하는 미니스킬이 있는 경우 우선권을 갖지만, 나머지의 경우 연속된 턴에서 같은 미니스킬의 사용을 피하기 위해 제약조건을 만족하는 미니스킬들 중에서 랜덤하게 선택합니다.미니 스킬: 여러 미니스킬은 서로 다른 대화 전략을 갖고 다른 시스템 액션을 취하며, 특정 대화모드의 시그맨트를 관리합니다. 정리해보면, DM모듈은 NLU모듈의 출력(input frame)을 이용하여 NLG모듈에서 이용될 speech act를 만들고, dialogue state를 업데이트 합니다. 기능을 크게 나눠 살펴보면 다음과 같습니다.
Content retrieval: DM모듈에 포함된 특정 미니스킬에서는 컨텐츠 검색에 대한 명령, 새로운 컨텐츠를 제시하여 대화를 이끌어 나가고 싶은 경우 등 컨텐츠를 찾아야 하는 엑션을 포함합니다. 컨텐츠 검색 시에는 input frame을 만족하는 컨텐츠를 찾으려고 시도합니다. 이 때 실패를 줄이기 위해, 검색의 제약 조건을 점점 완화시켜나가는 backoff 전략이 사용됩니다. 먼저 primaryIntent(컨텐츠의 타입), primaryTopic을 모두 만족하는 컨텐츠를 찾고, 이를 만족하지 못하는 경우 primaryIntent, primaryTopic 순으로 조건을 완화시킵니다. 컨텐츠 타입의 경우 조건을 완전히 제거하고, 토픽 조건은 candidateTopic을 이용합니다. 완화를 진행했음에도 불구하고 컨텐츠가 검색되지 않는 경우, 사용자에게 이 토픽에 대해 말할 것이 없음을 알리는 실패 액션이 실행됩니다.
Error handling: DM은 시스템 에러, 이해 에러를 다룹니다.
- 시스템 에러는 서비스에서 발생한 예외(request time-out), 버그로 인한 실패 등을 포함하는데, 이 경우 현재 dialogue state를 초기화하고 적절한 사과와 함께 부드럽게 대화를 재시작하도록 시도합니다.
- 이해 에러는 ASR에러, 예상치 못한 유저의 의도, 언어 처리 에러(파싱 에러)등이 해당됩니다. 미니스킬에서 이용하는 대화 전략이 요구하는
input frame이 (NLU 과정에서의 문제 등으로 인해) 없는 경우 이러한 에러로 처리합니다. 이 경우 시스템은 잘못된 이해를 인정하고 대화를 계속할 것을 유저에게 제안합니다. 이러한 상황이 여러 번 발생하여 이를 계속적으로 인정하고, 새로운 대화를 유저에게 요청하는 것은 랜덤한 토픽 변화보다 유저의 경험을 안좋게 만든다고 판단하였기 때문에, 에러가 두 번 이상 감지된 경우 DM모듈은 새로운 토픽 혹은 미니스킬을 새로 선택합니다.
Satisfaction detection: 시스템이 불쾌하거나 모욕적인 컨텐츠 혹은 지루한 컨텐츠를 제공했을 때, 문제가 발생할 수 있습니다. 이러한 경우가 발생했을 때 사용자의 반응을 살펴보면, 명확하게 토픽 변화를 요청하기 보다는 불만을 표시하는 경우가 많았습니다. 그러므로 시스템에서 이러한 문제를 자동으로 발견하고 토픽 변화, 초기화 등의 해결을 시도하는 전략을 취했습니다. 저자들은 이 문제를 발견하기 위한 이진 분류기를 만들고자 했습니다. 하지만 단순히 만족도를 명확하게 판단하기 힘들고, 따라서 학습을 위한 데이터를 만들때 일관성있는 레이블을 받기 힘듭니다. 그래서 사용자 만족도는 토픽의 변화와 관련이 있다고 판단하고, 만족도를 직접 분류하기 보다는 토픽이 바뀌는 시점을 만족도가 하락한 시점으로 가정했습니다. 토픽 변화 시점을 감지하는 모델을 만들기 위해 2381개의 데이터를 만들었고, 적은 양의 데이터로 인해 n-gram(1,2,3 gram) 피쳐를 이용한 logistic regression classifier를 만들었습니다.
Speech act selection: DM은 유저의 대화(턴)을 다루기 위해, 미니스킬에 따라 여러 액션을 실행합니다. 여기서 미니스킬은 결과로 사전에 정의된 speech act 중 1개 이상을 선택합니다. speech act는 크게 grounding, inform, request, instruction의 대분류로 구분됩니다.
grounding: grounding은 “접지”라는 사전적 의미가 있는데, 대화에서는 참가자들이 해당 대화에 대해 충분히 싱크가 맞고 있는지 의미합니다. 따라서 이는 대화를 충분히 이해하고 있음을 알려주기 위한 speech act입니다.back-channel,유저 요청 확인, 3종류의문제 인정,감사의 6개로 세분화 됩니다. 이러한 피드백은 사용자의 발화를 잘 받았고, 이해하고 있다는 것을 알릴 수 있으므로 중요한 역할을 합니다.input frame과 컨텐츠 검색 결과, 토픽 변화 감지, 에러 헨들링 등에 의해 결정됩니다.inform: 유저에게 컨텐츠가 제공되어야 하는 경우에 제대로된 컨텐츠가 찾아져서 쌍이 이뤄진 경우 사용됩니다.request: 확인 질문, 토픽에 대한 요청, 사용자가 의견을 제시하도록 제안하는 것 등이 포합됩니다.inform은request와 주로 결합되고, 이를 통해 시스템이 제공한 정보(inform)에 대한 사용자의 반응 및 커멘트(request)를 받도록 유도합니다. 하지만 사용자에게 자극/반감을 줄 수 있는 확인과정은 최소화합니다.
instruction: dialogue state나 error detection에 따른 도움 메세지를 내보내는 경우입니다.
2.3. Natural Language Generation
NLG는 speech act과 컨텐츠를 입력으로 받아 답변을 생성하는 모듈입니다. 답변은 4개의 큰 종류 중 최대 3개의 speech act를 포함할 수 있습니다. Amazon TTS API의 요구사항대로 답변은 message와 reprompt로 구성되어야 합니다. 장치(Alexa)는 항상 message를 읽는데, reprompt는 장치가 주어진 기간동안 아무것도 듣지 못했을 때 옵셔널하게 사용됩니다. grounding act에 의한 답변은 주로 message의 시작에 위치하고, instruction은 reprompt에 위치합니다.
groundingact의 답변을 생성할 때에는 다음과 같이 세부 카테고리와 관련된 구절/문장들의 모음들 중 랜덤으로 답변을 선택합니다.back-channeling: “I see”, “Cool”user request echoing: “Looks like you want to talk about news”misunderstanding apology“Sorry, I’m having trouble understanding what you said.”unanswerable user follow-up questions: “I’m sorry. I don’t remember the details.”gratitude“I’m happy you like it.”
informact는 시작 구절(“Someone on Reddit said”, “My friend in the cloud told me that” 등)과 DM에 의해 제공된 컨텐츠를 결합한 간단한 템플릿에 의해 답변이 구성됩니다.requestact는 유저의 입력을 요청하는 slot-level의 변형의 형태로 구성됩니다.instructionact는 변형이 적고 상황에 맞는 도움말 메시지 모음으로 구성된다.
이렇게 만들어진 답변은 발음을 보다 정확하게 전달하기 위해 ASK SSML을 활용하며, 마지막으로 욕설 단어/구절을 비 공격적인 단어로 대체하는 발화 정화기를 거칩니다.
3. Miniskills
Sounding Board는 여러 개의 다른 미니스킬들을 갖고 있는데 이들은 dialogue state를 관리하고, 대화 시그먼트의 일관성을 책임집니다. 계층적 구조에 의해 세부 대화 전략/대화의 디테일은 미니스킬 부분에서 담당하기 때문에 실제 대화의 퀄리티는 미니스킬들의 능력에 따라 결정됩니다. 그래서 가능하면 대화의 많은 영역을 다룰 수 있도록 다양하고 많은 미니스킬들이 구현되어 있습니다. (마지막 분석 부분에서도 미니스킬을 많이 추가할 수록 사용자 만족도가 높아졌습니다.)
3.1. content-oriented miniskills
많은 미니스킬들은 컨텐츠에 기반하는데, 주로 컨텐츠는 외부 소스로 부터 얻어집니다. 따라서 다음과 같이 두 가지 측면을 집중적으로 고려할 필요가 있습니다.
- 컨텐츠의 수집: 여러 소스(Amazon이 제공하는 트렌딩 토픽, Reddit으로 부터 생성된 컨텐츠, 뉴스 기사, QA, joke)로부터 컨텐츠를 얻습니다. 소스는 대화채에 맞는가와 충분히 정보력이 있는지, 넓은 관심사의 뉴스 혹은 논평을 제공하고 있는지, 정보를 이해하기 위해 적은 컨텍스트를 요구하는지, 쉽게 추출할 수 있는지 등의 기준으로 선택되었습니다.
- 컨텐츠의 관리: 컨텐츠들 중 욕설, 불쾌한 주제는 필터링 됩니다.
Sounding Board에는 다음과 같이 컨텐츠에 기반한 미니스킬들이 구현되어 있습니다.
Tranding topics: 유저가 선택할 수 있는 토픽을 추천합니다. Amazon에 의해 제공됨.Facts: TodayILearned 라는 subreddit에는 흥미로운 사실들이 많이 올라오는데, 이 포스트의 제목들을 컨텐츠로 이용합니다. 제목에 등장하는 토픽들로 제목을 인덱싱 했습니다. (토픽 → 제목)Opinions: ChangeMyView subreddit을 이용합니다. 여기의 포스트들은 대부분 논쟁의 여지가 있는 것들인데, “~~한 레딧의 게시물에 대해 어떻게 생각하는지 궁금합니다.” 와 같은 방식을 이용합니다.General News: UpliftingNews subreddit에서 검색을 진행하는데, 더 긍정적인 컨텐츠를 담는 것을 기대할 수 있습니다. 뉴스 제목은 위의 두 레딧에 비해 정보량이 적으나 본문은 매우 깁니다. 따라서 처음에 뉴스 타이틀을 읽어주고 4문장까지 요약문을 읽어주는데, 요약문은 Gensim의 TextRank 알고리즘을 이용했습니다.Sports News: 스포츠는 많은 사람들의 삶에서 큰 부분을 차지하고 있고, 사용자들은 소셜봇이 이러한 사실들에 대해 의미있게 이야기하기를 원합니다. 이 주제는 시간에 민감하므로, 최근 스포츠 이벤트를 위주로 크롤링합니다. 하지만 스포츠 기사는 너무 긴 문제가 있는데, Washington Post 기사에 제공되는 “blurb”와 헤드라인을 결합하면 자세한 정보를 제공하지 않고도 훌륭한 컨텐츠를 제공할 수 있었습니다. 하지만 이들 중 상당수가 컨텍스트가 누락되어 있었기 때문에 이를 필터링할 수 있는 필터를 개발했습니다.Jokes:Evi로 부터 조크를 요청합니다.Question Answering:Evi의 QA엔진으로 연결합니다. Evi의 컨텐츠가 토픽과 관련이 있는지에 따라 다음 미니스킬을 제안합니다.(이 부분이 유저 경험을 향상시킴, 특히 Evi가 답을 제공하는데 실패한 경우) Alexa의 이름, 생일, 민감한 토픽, 충고등을 요구할 때에는 피하고, 트랜딩 토픽을 다음 미니스킬로 제공하는 전략을 취했습니다.
3.2. Personality Assessment
Sounding Board는 사용자들의 성격을 특정 타입중 하나로 구분합니다. 몇 개의 짧은 질문을 통해 사용자를 4가지 성격 사분면 중 하나에 위치시켰는데, 4분면의 두축은 외향성(Extraversion)과 솔직함(Openness)으로 외향성은 얼마나 수다스럽고 사교적인지를 나타내고, 솔직함(개방성)은 지적, 예술적으로 호기심을 드러내는 것과 관련이 있습니다.
5개의 질문을 진행한 후에 해당 사용자의 성격 결과를 얻을 수 있는 옵션을 제공합니다. 이 때, 중간중간에 대화를 지속하기 위한 “goofy” 질문을 끼워넣는 전략을 이용했습니다. 각 질문에 대한 대답을 얻었을 때, 다음 질문을 하기 전에 반응(리액션)또한 제공했습니다. (유저 피드백에서 이 반응이 유저 경험에서 큰 향상을 가져옴.) 각 성격 질문은 각 차원에 긍정적/부정적으로 로드되며 이를 통해 사용자를 사분면 상에 위치 시킵니다. 그 후에 사용자를 디즈니 캐릭터에 할당하고 이를 알려줍니다. 성격 질문에 답한 사용자에게는 각 사분면의 유형이 관심을 가질만한 것에 기초하여 토픽을 갱신합니다.
3.3. General miniskills
- 인사말: 오프닝에서 사용되며, 대화에서 한번만 사용됩니다. how-are-you 질문으로 대화를 초기화하고, 사용자의 대답에 공감하고 다음 대화로 진행합니다.
- 메뉴: 사운딩보드의 기능을 사용자에게 소개합니다. 시스템이 대화를 진행시키기 위해 다음 컨텐츠 기반 미니 스킬을 결정할 수 없는 경우 이용합니다.
- 종료: 유저가 사운딩보드를 종료하기 위해 명시적으로 중지를 말한 경우 발동됩니다. 발동 조건에 따라 사운딩 보드는 다른 grounding speech act를 instruction 전에 더합니다. Alexa command에 의해 문제가 발생한 경우에는 시스템의 한계를 설명합니다. stop command에 의해 발동되었을 때에는 채팅에 대한 감사 표현이 추가됩니다.
4. Rating insights
논문의 마지막 부분에는 저자들이 Sounding Board를 만들고 테스트 해보면서, 유저가 어떤 접근법을 선호했는지에 대해 분석합니다. 대화에서 여러 특징들을 추출하고, 사용자의 투표를 통해 선호도를 분석했습니다.
4.1. Miniskill performance
Sounding Board는 여러 미니스킬들이 집합체로 유저들의 발화에 대응하는데, 미니스킬들 각각이 대화에 미치는 영향을 분석했습니다. joke, personality quiz가 사용자의 선호도와 높은 상호 관계를 갖고 있었는데, 이는 사용자가 이러한 스킬들의 장난스러운 면을 좋아하기 때문이라고 분석했습니다. 이 외의 스킬들은 유저 선호도와 두드러지는 상호관계가 없었는데, 그 이유는 미니스킬 그 자체보다 해당 스킬이 제공하는 컨텐츠의 본질이 더 큰 영향을 미치는 것으로 해석했습니다. 더 많은 미니스킬을 가지고 더 다양한 컨텐츠를 제공할수록 유저의 만족도가 높아질 것이라고 가정하고, 많은 기능들을 추가함으로써 유저 선호도가 눈에 띄게 향상되는 결과를 얻었습니다.
4.2. Impact of ASR
대회 기간 도중에 ASR이 업데이트 되었는데, 이 시점 이전/이후로 나누어 ASR이 사용자 선호도에 미치는 영향을 분석했습니다. 예상과 달리 ASR 업데이트 전/후에 사용자 선호도는 크게 달라지지 않았습니다. 하지만 ASR confidence(길이로 정규화된 confidence 점수, 자세한 계산 방법은 나와있지 않음.)과 선호도 사이의 관계를 분석해 봤을 때에는 당연하게도 신뢰도 점수가 높을수록 사용자 선호도가 높았습니다. 결과적으로 신뢰도가 ASR의 정확도를 나타낸다면, 이 점수가 높을수록 사용자 등급이 높아지지만 그 효과는 적다고 볼 수 있습니다.
4.3. Personality insights
Personality Assessment 미니스킬 에서 보았듯이 저자들은 사용자를 2가지 축(외향성, 솔직함)을 기준으로 4가지의 유형으로 구분했습니다. 여기서 특정 타입의 성격이 시스템을 더 높게 판단하는지, 시스템과 더 길게 이야기하는지, 더 긴 발화를 말하는지에 대해 분석했습니다.
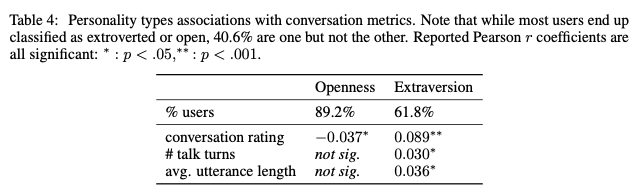
위 결과와 같이, 외향적인 유저는 봇을 조금더 좋아하는 경향이 있지만, 솔직함(개방성)은 낮은 선호도와 상관관계가 있었습니다. (이러한 경향은 대화의 턴 수를 제한할 때 유지됩니다.) 외향적인 사용자들은 각 대화의 턴에서 더 많이 말하는 경향이 있습니다.(평균 발화 길이가 깁니다.) 이는 외향성과 수다스러움(talkativeness)을 직접적으로 연관시키는 사회 심리학 이론의 검증으로 볼 수 있습니다. 흥미로운 점은 외향성과 대화 자체의 길이(턴 수)는 약한 상관관계를 갖습니다. 저자들은 이 성격 분포가 불완전한 신뢰성을 갖고 있고 성격을 구분하기 위해 던지는 질문에 사용자가 정확한 대답을 한다고 보장할 수 없기 때문에, 여기서 얻은 결과들을 작은 인사이트 정도로 가져갔습니다.
마무리
여기 까지 Sounding Board 논문을 정리했는데, 대화 시스템의 구성에 대해 생각해볼 수 있었습니다. 일반적으로 대화시스템은 NLU, DM, NLG모듈 + 알파로 구성된다고 볼 수 있는데, 각 모듈의 세부 사항은 대화 시스템의 목적에 따라 다른 양상을 보입니다. Sounding Board에서는 디자인 철학에서 드러나듯이 “컨텐츠”와 “사용자”에 집중하려고 노력했던 부분들을 느낄 수 있었습니다. 특히 사용자의 대화 데이터를 분석하여 얻은 인사이트로 많은 전략들이 결정되었는데, “인과 관계”를 잘 파악했다는 느낌을 받았습니다. 어떤 요인들에 의한 효과인지 잘 파악할 수 있도록 모듈화된 구조와 각 모듈의 구성요소/피쳐들 또한 잘 설계되었다고 생각합니다. 한편으로는 실시간으로 사용자의 피드백을 받을 수 있는 Alexa 플랫폼을 제공해주는 것은 Alexa Prize의 상금 이상의 엄청난 혜택으로 느껴졌습니다. 그리고 한국어 대화 시스템을 개발하고 있는 입장에서, 이미 여러 레퍼런스들과 소스들이 존재하는 영어가 부러웠습니다. 특히 사전에 구축된 백앤드 시스템들(QA, Knowledge base, parsing 시스템 등)이 한국어로도 이용할 수 있다면 조금 더 다양한 시도들을 해볼 수 있지 않을까라는 생각이 들었습니다. 하지만 최근에 여러 한국어 NLP 데이터와 테스크들이 만들어지는 걸 보면서, 곧 비슷한 환경이 만들어질 것이라는 기대를 갖고 있습니다. 다음 글에서는 2018년도 우승 작품을 리뷰하겠습니다.