
Pre-trained LM은 많은 양의 데이터로 부터 컨텍스트를 반영한 representation을 학습합니다. 이를 통해 NLU-BERT, RoBERTa, NLG-GPT 와 같이 각각의 downstream 테스크에서 좋은 성능을 보여주고 있습니다. 이번 포스트에서는 NLU와 NLG를 함께 pre-train하여 하나의 pre-trained 모델이 각 테스크에 “모두” fine-tuning될 수 있는 방법인 “Unified pre-trained Language Model(UniLM)”를 제시한 논문 “Unified Language Model Pre-training for Natural Language Understanding and Generation (NeurIPS 2019)”를 리뷰하려고 합니다.
1. Main Idea
- 마스킹된 토큰을 예측하는 pre-training 테스크와 어텐션 마스킹 방식을 조합하여 3가지 Language Modeling Objective(
Uni-directional,Bi-directional,Sequence-to-Sequence)를 학습합니다. - 각 LM 테스크 사이의 파라메터와 모델 구조를 단일 Transformer로 통일함으로써, 여러 LM을 만들어야 했던 필요성을 완화합니다.
- 각 objective 사이의 파라메터 공유를 통해 컨텍스트를 여러 방향으로 이용할 수 있는 능력을 학습하고, 오버 피팅을 방지하여 일반화 능력을 향상시킵니다.
- NLU테스크 뿐만 아니라 Sequence-to-Sequence LM으로써, 요약이나 질문 생성 등의 생성에 이용할 수 있습니다.
2. Unified Language Model Pre-training
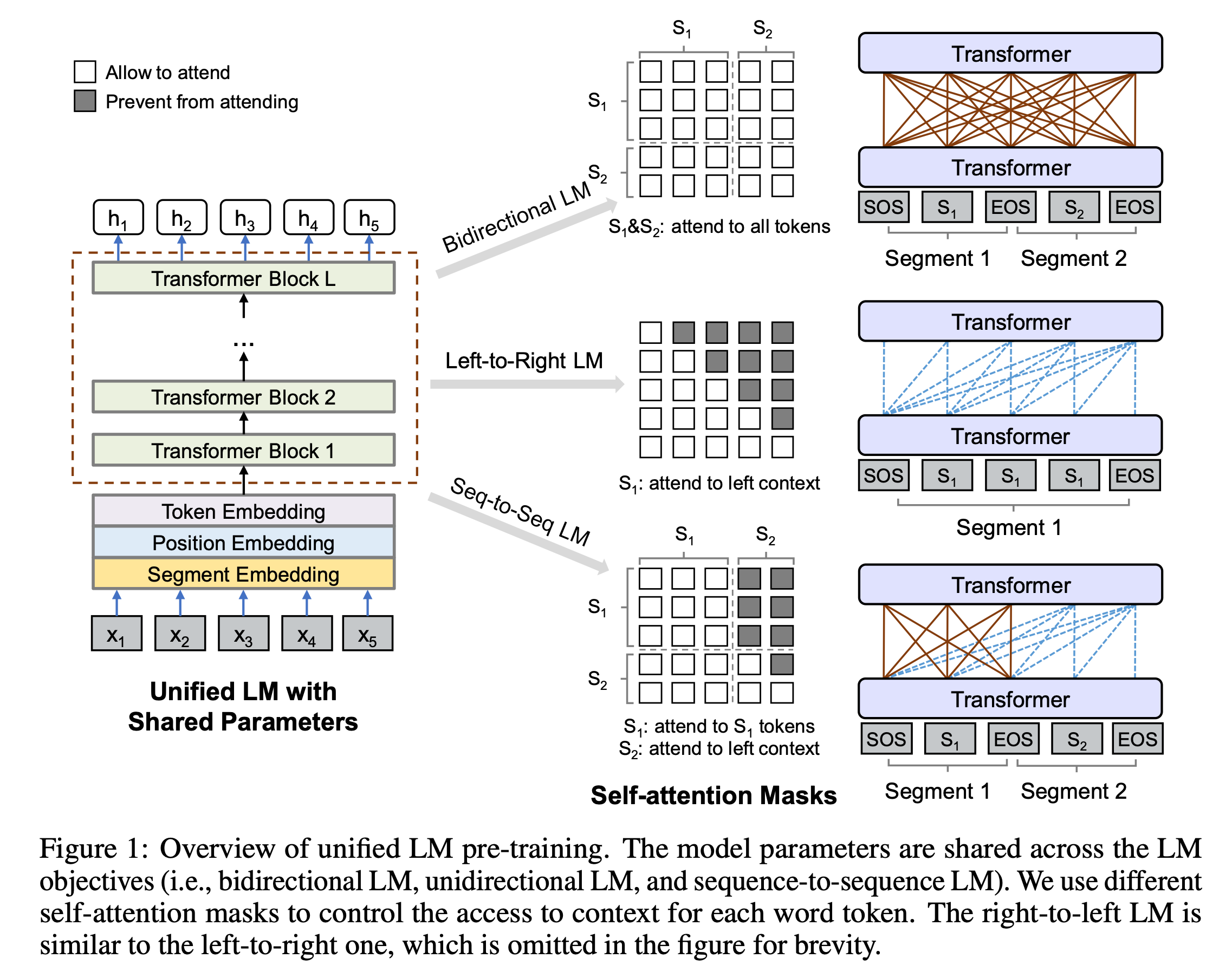
입력으로 토큰들의 시퀀스가 주어졌을 때, UniLM은 Transformer 구조를 이용해 컨텍스트를 고려한 각 토큰의 representation을 계산합니다. 이 때 제시한 세가지 objective를 수행하기 위해, 위 그림과 같이 어텐션 마스크를 이용해서 각 토큰이 어떤 컨텍스트에 접근할지 통제합니다. 즉, 얼마나 많은 토큰들(컨텍스트)에 attend 할지를 결정합니다.
2.1. Input Representation
- 입력은 1개 혹은 2개의 시그먼트(연속된 토큰의 시퀀스)로 구성됩니다. unidirectional LM의 경우 1개의 시그먼트를 입력으로 하고, 나머지 objective는 2개의 시그먼트를 입력으로 합니다.
- 모든 시퀀스는
[SOS](start-of-sequence) 토큰으로 시작하고, 각 시그먼트는[EOS](end-of-sequence) 토큰으로 끝납니다.[EOS]토큰은 각 시그먼트의 경계 역할 뿐만 아니라 NLG에서 디코딩 과정의 끝을 학습할수 있게 합니다. - 모든 텍스트는 WordPiece에 의해 서브워드로 토크나이즈 됩니다.
- 각 입력 토큰의 임베딩은 BERT와 유사하게 token, position, segment 임베딩의 합으로 계산됩니다. 서로 다른 objective를 임베딩 단에서 구분하기 위해, objective마다 다른 segment임베딩을 사용합니다.
2.2 Backbone Network: Multi-Layer Transformer
각 토큰의 입력 벡터는 L개의 layer를 가진 Transformer 블럭을 거치면서, 컨텍스트를 반영한 representation을 만듭니다. 각 블럭은 일반적인 Transformer와 동일하게 multi-head self-attention 연산을 수행합니다.
\[Q=H^{l-1}W_l^Q, K=H^{l-1}W_l^K, V=H^{l-1}W_l^V\] \[M_{ij} = \begin{cases} 0, \text{allow to attend} \\ -\infty, \text{prevent from attending} \end{cases}\] \[A_l = softmax(\frac{QK^{\top}}{\sqrt{d_k}} + M)V_l\]Self-Attention 연산은 위의 식과 같이 이루어지는데, 주목해야할 점은 2번째 식의 행렬 \(M\)입니다. 3번째 식에서 attention value(Q-K사이의 관계)에 \(M\)을 더해서 softmax연산을 진행하는데, 이 때 \(M=-\infty\) 인 경우 해당 Key에 attend할 비율은 0이 되어 버립니다. 일반적으로, BERT에서는 패딩 값들, GPT와 같은 생성모델에서는 현제 시점에서 미래 위치의 토큰값들에 attend하는 것을 막기 위해서 \(M\)을 적절히 이용합니다. (본 논문에서 사용법은 아래의 pre-training objective에서 자세히 다룹니다.)
2.3. Pre-training Objective
UniLM은 cloze 테스크(빈칸 맞추기-마스킹된 토큰 맞추기)를 수행하는데, 4가지의 서로 다른 LM objective에 따라 attend할 수 있는 컨텍스트가 달라집니다. 즉 각 Objective가 동일한 문제(cloze 테스크)를 풀되, 마스킹된 토큰을 맞추기 위해 주어지는 정보량에 차이가 있습니다. cloze 테스크는 BERT의 MLM과 유사한 방식으로 진행합니다. 입력에서 랜덤으로 몇몇 토큰을 [MASK]로 치환하고 Transformer 모델의 최종 출력값을 이용해 원래 토큰을 예측합니다.
- Unidirectional LM:
left-to-right,right-to-left두 방향의 컨텍스트를 각각 이용하여 마스킹된 토큰을 예측하는 단방향 Language Modeling을 학습합니다.left-to-right의 경우 주어진 토큰 \([x_1, x_2, [MASK], x_4]\)에서 \([MASK]\)를 예측하기 위해 왼쪽의 컨텍스트 \(x_1, x_2\)와 자기자신(\([MASK]\))만을 이용합니다. 이를 위해서 아래 그림과 같이 각 토큰의 attention을 계산할 때, 해당 시점 이전(자기 자신 포함)의 토큰들만 이용하도록 마스크를 구성합니다.
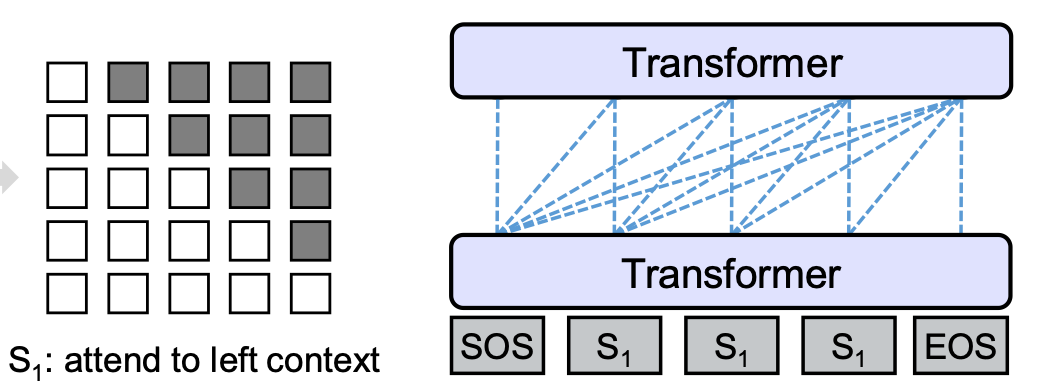
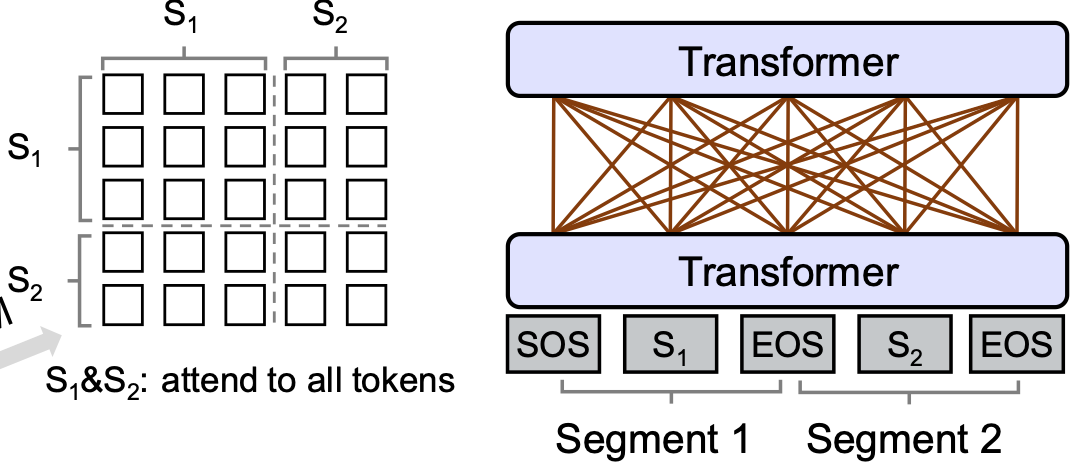
- Bidirectional LM: BERT의 방식과 동일하게, 양방향의 컨텍스트를 모두 이용하여 마스킹된 토큰을 예측하는 Language Modeling을 학습합니다. 아래 그림과 같이 모든 마스크의 값이 0으로, 각 토큰은 서로를 attend할 수 있습니다. 이를 통해 양 방향으로부터 더 많은 컨텍스트 정보를 인코딩할 수 있게 되고, 단 뱡향보다 풍부한 표현력을 갖게 됩니다. 또한 Bidirectional인 경우, BERT에서 제시한 Next Sentence Prediction 문제(두 시그먼트의 연결이 자연스로운지)도 함께 학습합니다.
-
Sequence-to-Sequence LM: Sequence-to-Sequence 방식은 두 시그먼트가 각각 소스/타겟의 의미를 갖고 모델은 인코더-디코더의 역할을 수행합니다. 전형적인 Seq2Seq과 유사하게 소스의 토큰들은 각 토큰들이 서로 attend할 수 있고(인코더의 역할), 타겟의 토큰들은 해당시점 이전의 토큰들(소스 토큰 + 현재 시점 이전의 타겟 토큰들, 자기자신 포함)에 attend 할 수 있습니다.(디코더의 역할)
주어진 입력 시퀀스 \([SOS], t_1, t_2, [EOS], t_3, t_4, t_5, [EOS]\) 에 대해 첫번째 시그먼트 (\([SOS], t_1, t_2, [EOS]\))는 서로 attend 할 수 있고 두번째 시그먼트의 \(t_4\)같은 경우 자기자신 포함 왼쪽의 6토큰에 attend할 수 있습니다.
아래 그림과 같이 소스는 타겟 시그먼트를 볼 수 없도록 마스킹되고(우측 상단), 타겟은 현재 시점 이후의 토큰을 볼 수 없도록 마스킹 됩니다.
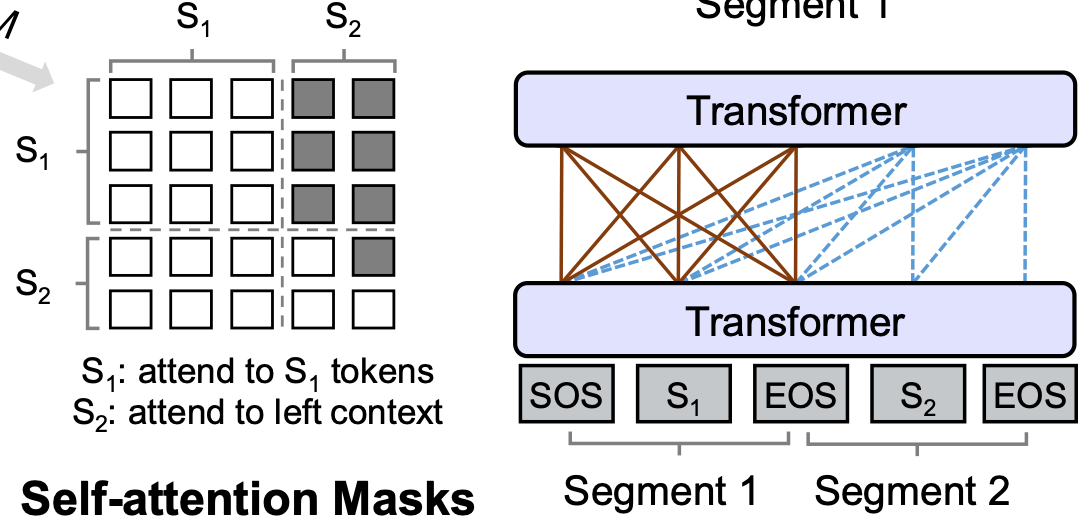
이렇게 마스킹이 된 입력의 원래 토큰을 분포를 예측하는 동일한 학습과정으로 학습하는데 “서로 다른 어텐션 마스크(\(M\))”로 4가지 LM을 구분할 수 있습니다.
2.4. Pre-training Setup
배치의 구성: 각 학습 배치는 다음과 같은 비율로 모든 objective가 혼합된 형태로 구성됩니다. 배치사이즈는 330으로 이용했습니다.
- Bidirectional LM/Sequence-to-Seuquence LM: 각각 1/3
- Unidirectional LM: left-to-right, right-to-left 각각 1/6
모델: BERT_LARGE와 같은 크기를 이용했습니다. (L=24, H=1024, A=16, 약 340M 파라메터)
- token 임베딩과 최종 토큰 분포를 예측하기 위한 softmax classifier의 가중치는 공유됩니다.
- UniLM은 BERT_LARGE의 학습된 가중치로 초기화되고, BookCorpus와 영어 위키피디아로 추가적으로 pre-training 됩니다.
마스킹 전략: BERT와 유사하게 입력 시퀀스의 15%를 마스킹 합니다. 이 중 80%의 경우 [MASK] 토큰으로 치환, 10%의 경우 랜덤한 다른 토큰으로 치환, 나머지 10%의 경우 원래 토큰을 유지합니다.
- 추가적으로 80%의 경우 한번에 유니 그램(하나의 토큰) 단위로 마스킹 하지만, 20%의 경우 한번에 연속적인 바이그램(두 개의 토큰)/트라이그램(세 개의 토큰)을 마스킹합니다.
옵티마이저: Adam(\(\beta_1 = 0.9, \beta_2 = 0.999\)), lr=3e-5를 이용했습니다.
- lr scheduler: 40,000 스탭의 웜업 후에 선형 감소하는 스케쥴링을 이용했습니다.
총 학습은 770,000 스텝 정도 진행되었습니다.
2.5. Fine-tuning on Downstream NLU and NLG Tasks
NLU 테스크들: BERT와 동일한 방식으로 학습을 진행합니다. 텍스트 분류 문제의 경우 [CLS] 토큰 대신에 [SOS] 토큰을 이용합니다.
NLG 테스크들: pre-training과 유사하게 마스킹된 토큰을 원래 토큰으로 복원하는 방식으로 생성을 진행합니다. 하지만 테스크에 따라 마스킹이 되는 위치와 비율이 달라집니다. 예를 들어 Sequence to Sequence NLG 테스크의 경우, 마스킹은 타겟 시그먼트에만 진행되며 약 0.5 ~ 0.7정도의 비율의 토큰이 마스킹됩니다. 실제 추론시에는 각 디코딩 스텝에서 [MASK]토큰을 입력으로 넣어 출력값을 계산합니다.
3. Experiments
저자들은 NLU 테스크들(GLUE 벤치마크) 및 NLG 테스크들(요약, 질문 생성, 대화 답변 생성)로 실험을 진행했습니다.
3.1. Abstraction Summarization
요약 테스크로 주어진 뉴스 기사 등에서 핵심 정보를 추출해 요약된 문장을 생성합니다. CNN/Daily Mail, Gigaword 데이터셋으로 실험을 진행했고 Sequence-to-Sequence 방식으로 학습을 진행했습니다.(소스 - 뉴스 기사, 타겟 - 요약 문장) 마스킹 비율은 0.7을 사용했습니다.
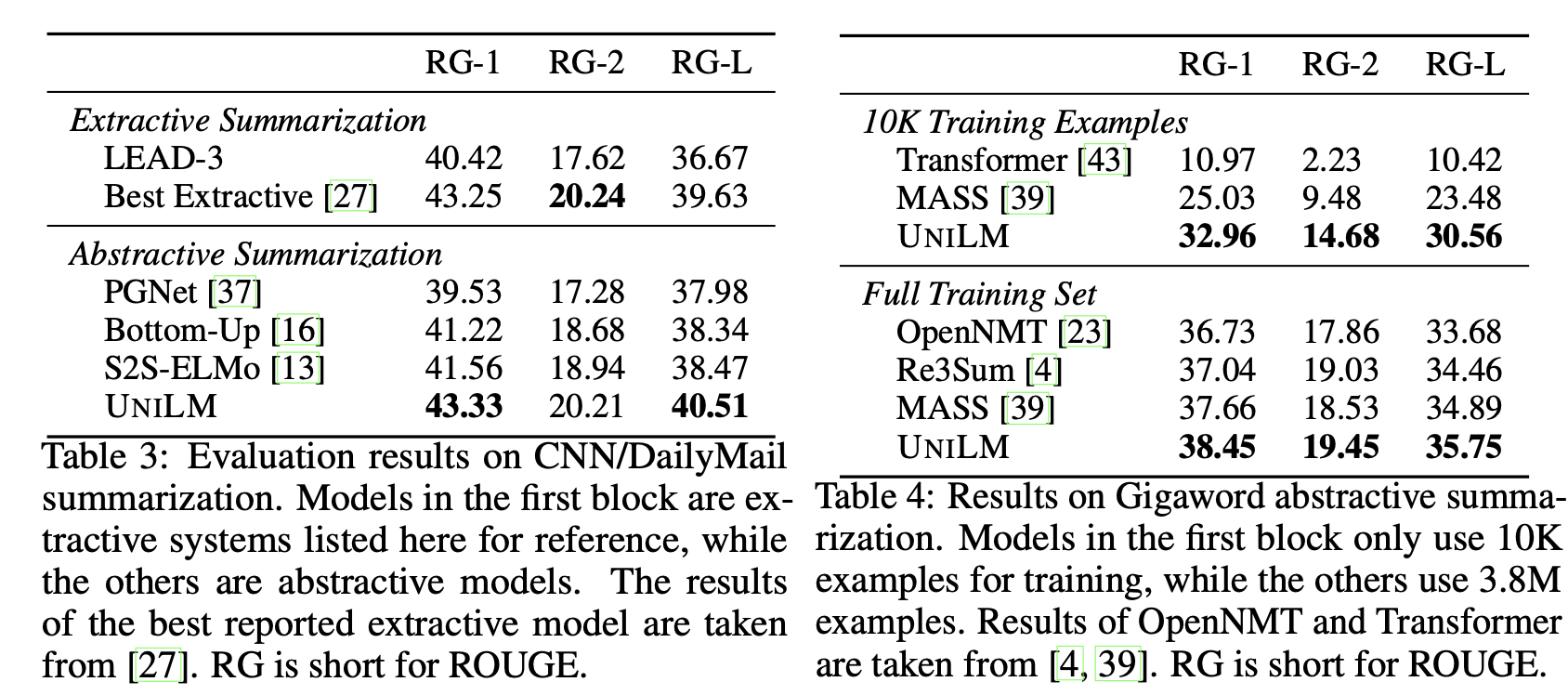
위의 표와 같이 각 데이터셋에서 SoTA성능을 보여줍니다. 왼쪽 표의 Extractive Summarization의 경우 요약문을 생성해내는 것이 아니라 주어진 본문 내에서 요약 문을 선택하는 방식으로 학습을 진행한 모델입니다.(완전히 동일한 학습 환경이 아닙니다.) 오른쪽 표에서 10K의 데이터만 이용한 경우에 다른 모델들을 큰 격차로 능가했는데, row-resource 설정에서도 잘 동작함을 알 수 있습니다.
3.2. Question Answering(QA)
QA는 주어진 지문 컨텍스트(C)에 대해 질문(Q)에 대한 답(A)를 찾는 문제입니다. 이 문제를 풀기 위해 extractive, generative 두 가지 방식이 존재합니다.
extractive: 질문의 답을 주어진 컨텍스트, 질문 내의 span으로 찾는 방법, 일반적으로 정답 span의 처음과 끝 index(위치)를 찾습니다. NLU 테스크로 볼 수 있습니다.generative: 질문의 답을 생성하는 방법, NLG 테스크로 볼 수 있습니다.
SQuAD(extractive)와 CoQA(extractive & generative) 데이터셋으로 실험을 진행했습니다.
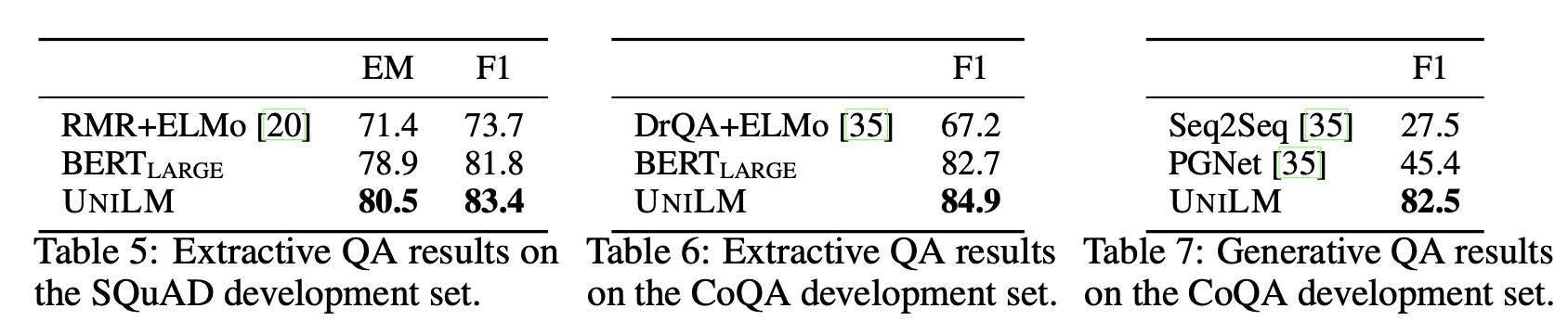
위의 표와 같이 extractive, generative 모두 기존의 방법론들보다 좋은 성능을 보여줍니다.
이외에도 Question generation(질문 생성 - NLG), Dialogue response generation(답변 생성 - NLG) GLUE 벤치마크(NLU) 등의 downstream 테스크들로 실험을 진행했고, 우수한 성능을 보여주었습니다.
4. Reference
- Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language understanding and generation. NeurIPS 2019