
작년 EMNLP 2019에 갔을 때, Vision & NLP(이름은 정확하지 않지만..) 세션에서 눈여겨 봤던 논문 중 하나인 LXMERT: Learning Cross-Modality Encoder Representations from Transformers를 리뷰하려고 한다. Visual Question Answering 2019 challenge 에서 3등에 위치해 있는 것을 볼 수 있다. (하지만 공식적으로 레퍼런스가 있는 방법들 중에는 첫번째이다.)
1. Main Idea
일반적으로 Multi-Modality 사이의 추론 능력을 다루는 테스크들은 1) 비주얼적인 개념, 2) 언어의 의미, 3) 두 모달리티 사이의 관계를 잘 파악하는 것이 중요하다. 각 싱글 모달리티에 대해서는 1) 비전 - ImageNet 데이터로 사전 학습, 2) 언어 - ELMo, BERT등의 언어 모델 사전 학습 을 통해 좋은 representation을 얻을 수 있었다. 본 논문에서는 이를 확장하여, 비전-언어 사이의 연결을 사전 학습하는 LXMERT(Language Cross-Modality Encoder Representation from Transformers) 방법을 제안한다.
LXMERT는 크게 1) Object relationship encoder 2) Language encoder 3) Cross-modality encoder의 3가지의 인코더로 구성되는데, 각각은 트렌스포머 인코더로 구성된다. 그리고 비전과 언어의 의미를 연결할 수 있는 능력을 학습하기 위해, 5개의 테스크로 pre-training을 진행했다. 각각의 테스크를 통해 intra-modality 뿐만 아니라 Cross-modality 또한 학습할 수 있다. 이 모델을 여러 VQA 데이터셋에 fine-tuning했을 때, SOTA 결과를 얻을 수 있었다.
2. LXMERT: Model Architecture
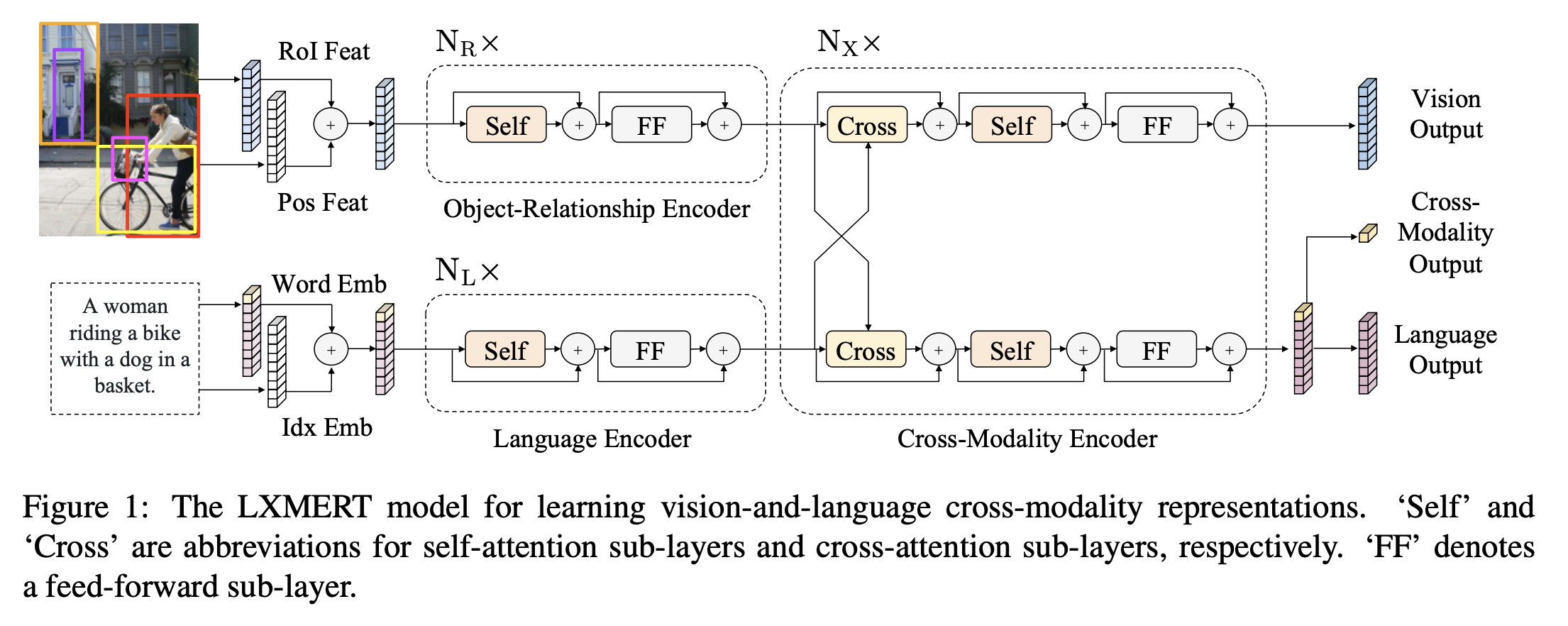
LXMERT는 위 그림과 같이 self-attention과 cross-attention layer로 구성된다.(각 layer는 Transformer 구조에 기반한다.) 입력으로 이미지와 그에 해당하는 문장을 받고, 각 이미지는 object의 시퀀스 문장은 단어의 시퀀스로 표현된다. 제안한 구조를 통해 언어, 이미지, cross-modality에 대한 각각의 representation을 만들어낼 수 있다.
2.1. Input Embeddings
LXMERT의 입력은 단어단위의 문장 임베딩(Word-Level Sentence Embedding)과 object 단위의 이미지 임베딩(Object-Level Image Embedding)의 두개의 시퀀스로 구성된다.
Word-Level Sentence Embedding: 문장은 WordPiece 토크나이저에 의해 토큰들로 분리되고 임베딩 레이어에 의해 각 단어 토큰에 해당하는 벡터로 변환된다. BERT와 유사하게 문장에서 각 토큰의 절대적인 위치를 표현하기 위해 인덱스 임베딩을 만들고 단어 임베딩에 더해준다.
\[\hat{w_i} = \text{WordEmbed}(w_i)\] \[\hat{u_i} = \text{IdxEmbed}(i)\] \[h_i = \text{LayerNorm}(\hat{w_i} + \hat{u_i})\]Object-Level Image Embeddings: CNN의 피쳐맵을 이용하는 방식이 아니라 Object Detector(Faster-RCNN)에 의해 찾아진 피쳐들을 입력으로 이용한다. 이미지로부터 \(m\)개의 object \(\{o_1, o_2, ... o_m \}\)가 검출되었을 때, 각 \(o_j\) 는 위치 정보(바운딩 박스 좌표) \(p_j\)와 2048-차원의 RoI(Region of Interest) 피쳐 \(f_j\) 로 구성된다. 이를 이용하여 다음과 같이 이미지 임베딩을 구성한다. 단어 임베딩에서 이용했던 \(\text{IdxEmbed}\)는 이용하지 않기 때문에 이미지의 절대적 인덱스는 주어지지 않는다. 따라서 attention 계산시 모델 입장에서 이미지의 인덱스를 구분할 수 없다.
\[\hat{f_j} = \text{LayerNorm}(W_Ff_j + b_F)\] \[\hat{p_j} = \text{LayerNorm}(W_Pp_j + b_P)\] \[v_j = (\hat{f_j} + \hat{p_j}) / 2\]2.2. Encoders
1) Language Encoder 2) Object-relationship Encoder 3) Cross-modality Encoder 3종류의 인코더를 이용한다. 각 인코더는 Self-Attention과 Cross-Attention 연산에 기반한다.
Attention Layers: 일반적인 Transformer에서 이용하는 Attention과 동일한 방식을 취하며, 이후 과정에서 이 표기를 이용해 Attention 연산을 표현한다.(Multihead Attention을 이용하지만 표기에는 드러내지 않는다.)
Attention 연산은 query 벡터(\(x\))와 context 벡터(\(y_i\))를 이용해 Attention 점수(\(a_j\))를 계산하고 이 점수에 따라 context 벡터를 가중합한다.
\[a_j = score(x, y_i)\] \[\alpha_j = \text{exp}(a_j) / \sum_k \text{exp}(a_k)\] \[\text{Att}_{X \rightarrow Y}(x, \{y_j\}) = \sum_j \alpha_jy_j\]self-attention의 경우 query 벡터 \(x\)가 \(\{y_j\}\) 안에 들어가 있는 것으로 일반화 할 수 있다.
Single-Modality Encoder: 임베딩 layer를 거친 두 개의 입력(Word/Object)는 각각 독립된 두개의 Transformer 인코더(Language encoder, Object-relationship encoder)에 의해 인코딩 된다. 여기서 각 인코더는 각각의 모달리티(언어/비전)의 특성을 녹이는데 집중한다.(각각은 독립적으로 인코딩되고 서로를 attend할 수 없다.) 각 인코더는 Self Attention 모듈(아래 그림의 “Self”)과 Feed forward 모듈(아래 그림의 “FF”)로 구성된다. (Transformer 인코더와 동일한 구조)
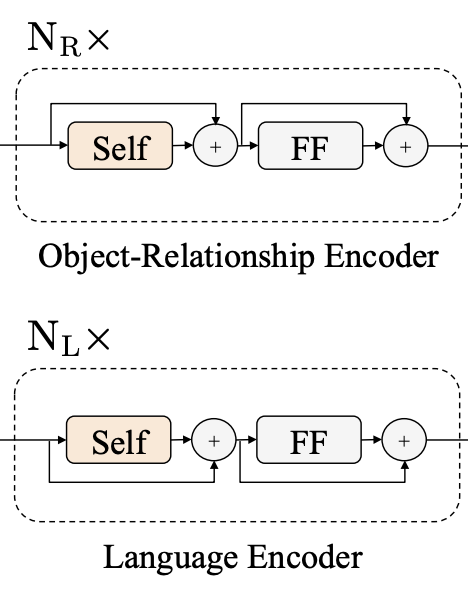
Cross-Modality Encoder: single-modality encoder를 통해 인코딩된 Vision/Language 각각의 시퀀스를 입력으로 하여, 두 모달리티 사이의 관계와 alignment를 녹이는데 집중한다. 인코더를 구성하는 하나의 layer는 하나의 Cross attention 모듈(아래 그림의 “Cross”), 두 개의 Self attention 모듈(아래 그림의 “Self”)와 Feed forward 모듈(아래 그림의 “FF”)로 구성된다. 인코더는 이러한 layer가 \(N_X\)개 쌓여서 만들어진다.
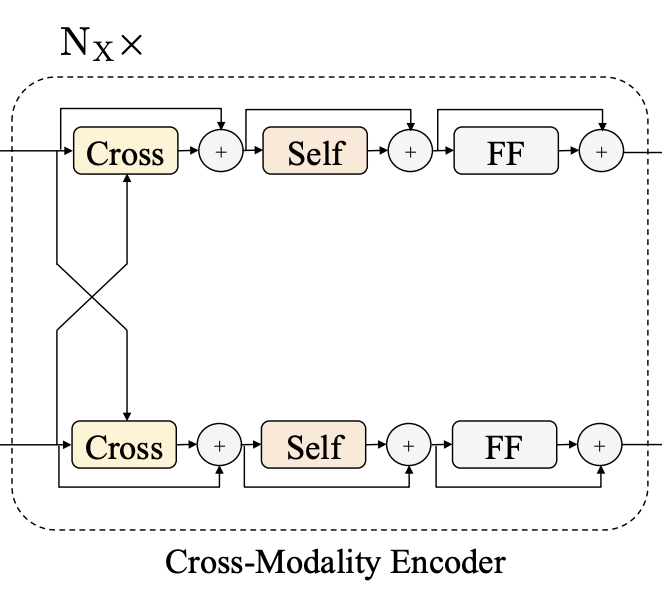
\(k\)번째 모듈에서 Cross Attention은 \(k-1\)번째 Language(\(\{h_i^{k-1}\}\))/Vision(\(\{v_i^{k-1}\}\)) 각각의 출력 시퀀스를 입력으로 받아 Cross Attn → Self Attn → FF 순서로 연산을 진행한다.
Cross Attn 연산은 아래 식과 같이 Language Feature(\(\{v_i^{k-1}\}\))의 경우 key로 Language, context로 Vision 피쳐를 입력으로(\(L \rightarrow R\)), Vision Feature는 반대 순서(\(R \rightarrow L\))를 입력으로 이용하여 Attention 연산을 진행한다. 이를 통해 각각 모달리티의 피쳐가 교차(Cross)하여 서로를 attend할 수 있게 된다. 즉 서로 정보를 교환하고 두 모달리티 사이의 엔티티들을 배열하여 joint corss-modality representation을 학습한다.
\[\hat{h}_i^k = \text{CrossAtt}_{L \rightarrow R}(h_i^{k-1}, \{v_1^{k - 1},..., v_m^{k - 1} \})\] \[\hat{v}_j^k = \text{CrossAtt}_{R \rightarrow L}(v_j^{k-1}, \{h_1^{k - 1},..., h_n^{k - 1} \})\]Cross Attn 이후에는 싱글 모달리티 내부의 연결을 강화하기 위해 각각의 모달리티에 대해 Self Attn연산을 진행한다.
\[\tilde{h}_i^k = \text{SelfAtt}_{L \rightarrow L}(h_i^{k-1}, \{h_1^{k - 1},..., h_n^{k - 1} \})\] \[\tilde{v}_j^k = \text{SelfAtt}_{R \rightarrow R}(v_j^{k-1}, \{v_1^{k - 1},..., v_m^{k - 1} \})\]마지막으로 Feed Forward 모듈을 거쳐 최종적으로 layer의 출력값을 만든다.
2.3. Output Representations
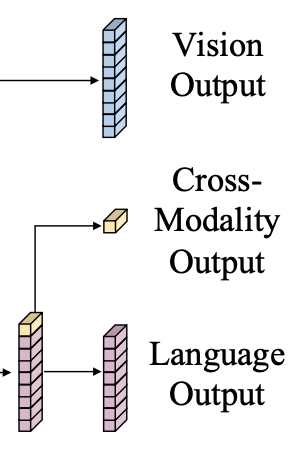
LXMERT의 출력값은 위 그림과 같이 Language/Vision/Cross-modality 3가지로 구성된다. Language/Vision의 경우 각각의 입력 시퀀스에 대응하는 Cross-Modality Encoder의 출력 시퀀스로 볼 수 있고, Cross-modality의 경우 BERT와 유사하게 Language 시퀀스의 첫번째에 위치하는 특수 토큰 [CLS] 의 출력값을 이용한다.
3. Pre-Training Strategy
3.1. Pre-Training Tasks
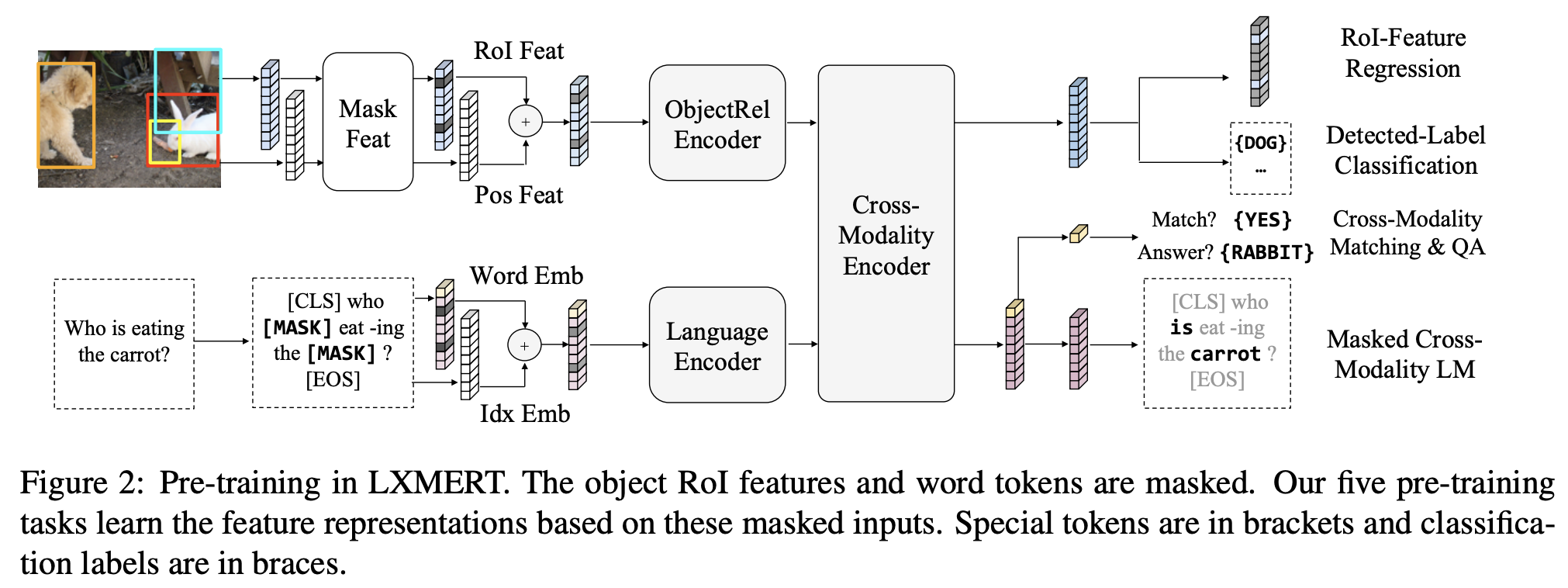
Language Task: Masked Cross-Modality LM: Language 입력에 대해 BERT의 Masked-LM과 동일한 테스크를 푼다. 일정 확률(0.15)로 입력 시퀀스 중 일부 토큰들을 [MASK] 로 치환하고, 원래의 토큰을 맞추는 문제를 푼다. BERT와 차이점은 Vision Feature로 부터 단서를 얻어 예측을 할 수 있다는 점이다. 위 예제에서 Carrot 에 마스킹이 되었을 때, 언어만으로 이를 맞추기는 쉽지 않다. 하지만 이미지를 이해한다면 이를 통해 통해 추론해낼 수 있다.
Vsion Task: Masked Object Prediction: 언어와 유사하게 입력 Vision Feature인 Object의 시퀀스 중 일부를 일정확률로 0으로 치환(마스킹) 하고, 이 object의 특성을 예측한다. 언어의 경우와 유사하게, 모델은 마스킹된 object를 비전 정보 뿐만 아니라 언어 정보를 이용해서 추론해낼 수 있고 이를 통해 Cross-modality alignment를 학습할 수 있다. 크게 다음과 같이 두 가지 문제를 푼다.
- RoI-Feature Regression: 마스킹된 Object의 RoI feature를 맞추는 문제
- Detected Label Classification: 마스킹된 Object의 Faster R-CNN의 출력 클래스를 레이블로 하여 이를 맞추는 문제
Cross-Modality Task: cross-modality를 더 잘 학습하기 위해 다음과 같은 문제를 추가적으로 푼다.
- Cross-Modality Matching: 0.5의 확률로 이미지와 매치되지 않는 랜덤 문장을 샘플링하고, 이미지-문장 쌍이 매치되는지 예측하는 문제
- Image Question Answering: 사전 학습 데이터 중 1/3 정도는 QA데이터 셋으로 구성됨. 따라서 위 문제에서 랜덤으로 치환되지 않은 QA데이터에 한하여 이미지와 질문을 주고 답을 찾는 문제
3.2. Pre-Training Data
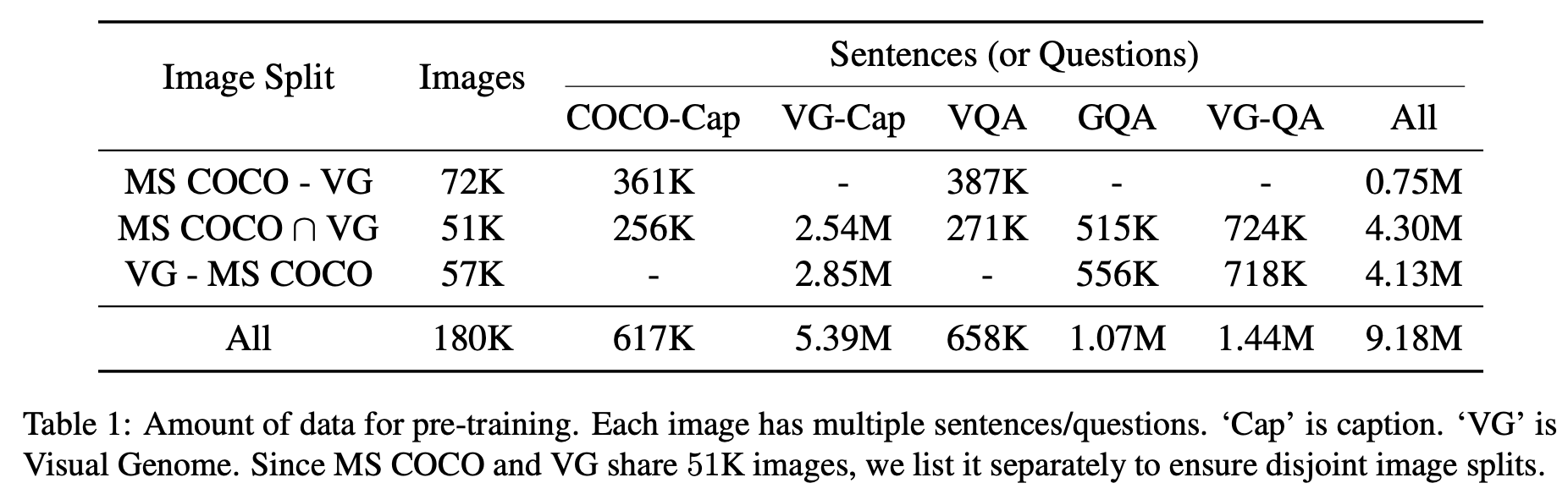
아래 표와 같이 총 5개의 데이터 셋을 이용해서 사전학습을 진행했다. 또한 train/dev 셋만 사전학습에 이용하였다.(파인튜닝 테스크의 테스트셋을 사전학습에서 보는 것을 방지하기 위해)
3.3. Pre-Training Procedure
사전 학습은 다음과 같은 설정을 따른다.
- 입력 텍스트: WordPiece 토크나이저(BERT에서 이용된)로 토크나이징
- 입력 이미지: Visual Genome으로 학습된 Faster R-CNN(ResNet-101)에 의해 추론된 결과, 각 이미지마다 최대 36개의 오브젝트만 유지
- 레이어 수:
- \(N_L\)(Language Encoder): 9
- \(N_X\)(Cross Modality Encoder): 5
- \(N_R\)(Object Relationship Encoder): 5
- 모든 파라메터를 from scratch로 학습함
- 사전 학습에 이용된 모든 테스크의 loss를 동일한 가중치로 더해서 최종 loss를 계산함
- 옵티마이저: Adam, lr=1e-4, linear-decay 스케쥴링
- 배치 크기: 256
- 학습 량: 20 epoch (QA는 마지막 10epoch에서만 이용함)
4. Experimental Setup and Results
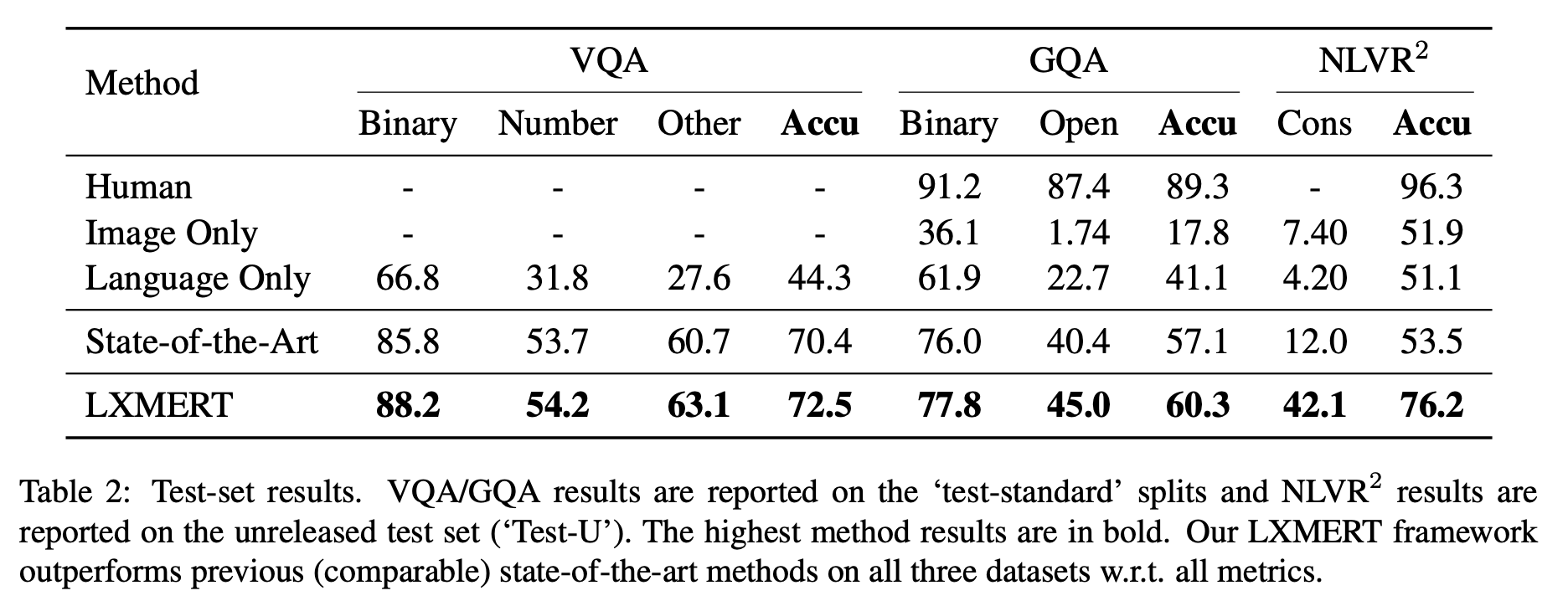
VQA2.0, GQA, NLVR 세가지 downstream 테스크들에 대해 평가를 진행했다. 아래 결과와 같이 기존 SoTA 결과들을 크게 뛰어넘었다. (실제로 2020년 8월 현제 시점까지 LXMERT는 각 테스크에서 상당히 높은 수준의 성능을 보여준다.)
5. 마무리
실험 결과 이후에 분석 부분도 상당히 흥미로웠다. 이 중에서도 Language Encoder 부분을 BERT로 초기화하는 것보다 from-scratch로 학습하는 것이 성능이 더 좋았다는 점이 가장 인상깊었다.