
뉴럴넷을 학습하기 위해서 일반적으로 GPU를 이용합니다. 하지만 최근에 많은 양의 데이터를 이용할 뿐만 아니라 엄청난 크기의 모델을 이용하는 연구들이 발표되고 있고, 이들은 GPU로 학습하기에 많은 시간이 소요됩니다. 이를 위해 Google Cloud에서는 TPU(Tensor Processing Unit)라는 연산장치를 제공하고 있고, TPU는 GPU에 비해 엄청난 성능을 보여줍니다. 또한 BERT 등 구글에서 공개한 많은 모델들은 이를 이용하여 학습되었습니다. TPU 자체에 대한 자세한 내용은 얼마전에 핑퐁팀 블로그의 포스트를 참고하면 더 많은 정보를 얻을 수 있습니다. 이번 포스트부터 3개의 포스트로 나누어 실제로 TPU를 이용해 모델을 학습하면서 경험했던 내용을 기록하려고 합니다.
목차
이번 글에서는 실험 환경에 대한 내용과 TPU를 이용하기 위해 GCP에서 수행해야 하는 작업들을 알아봅니다.
1. 실험 환경
이번 글에서는 BERT(Devlin et al., 2018) 모델의 pretraining과정을 TPU로 학습해보려고 합니다. 코드는 Tensorflow2.x + keras 를 이용해서 작성합니다. 모델 및 토크나이저 부분은 대부분 huggingface의 구현체를 이용합니다. 데이터는 한국어 wikipedia(약 1G) 데이터를 이용합니다.
TPU는 Google Colab 혹은 Google Cloud Platform 에서 TPU노드를 띄워서 사용할 수 있습니다. 두 과정에서 대부분의 로직은 동일기 때문에 본 포스트에서는 후자를 이용하여 진행합니다.
2. GCP에 TPU 환경 세팅하기
아래의 환경 세팅들은 Cloud TPU 공식 문서의 내용에 기반합니다. 아래 과정 중 대부분은 console(gcp 프로젝트 웹페이지)와 gsutil을 이용한 커멘드라인 명령어로 설정할 수 있습니다. 저는 편의성을 위해 전자를 이용했습니다.
-
프로젝트 생성 및 설정하기
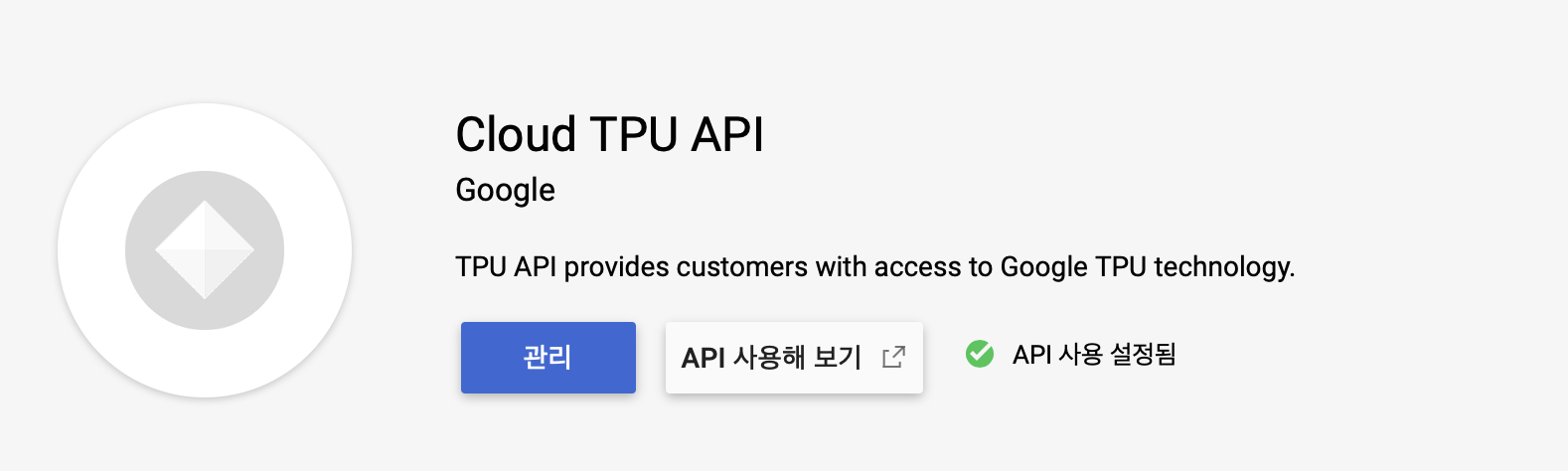
gcp홈에서 프로젝트를 생성합니다. 그리고 아래 그림과 같이 TPU 사용을 위해 Cloud TPU API를 켭니다.(아래 그림과 같이 되어 있다면 이용할 수 있습니다.)
-
TPU 노드 생성하기
아래 그림과 같이 프로젝트 홈 페이지에서
왼쪽 상단의 메뉴 버튼>Compute Engine>TPU로 이동합니다.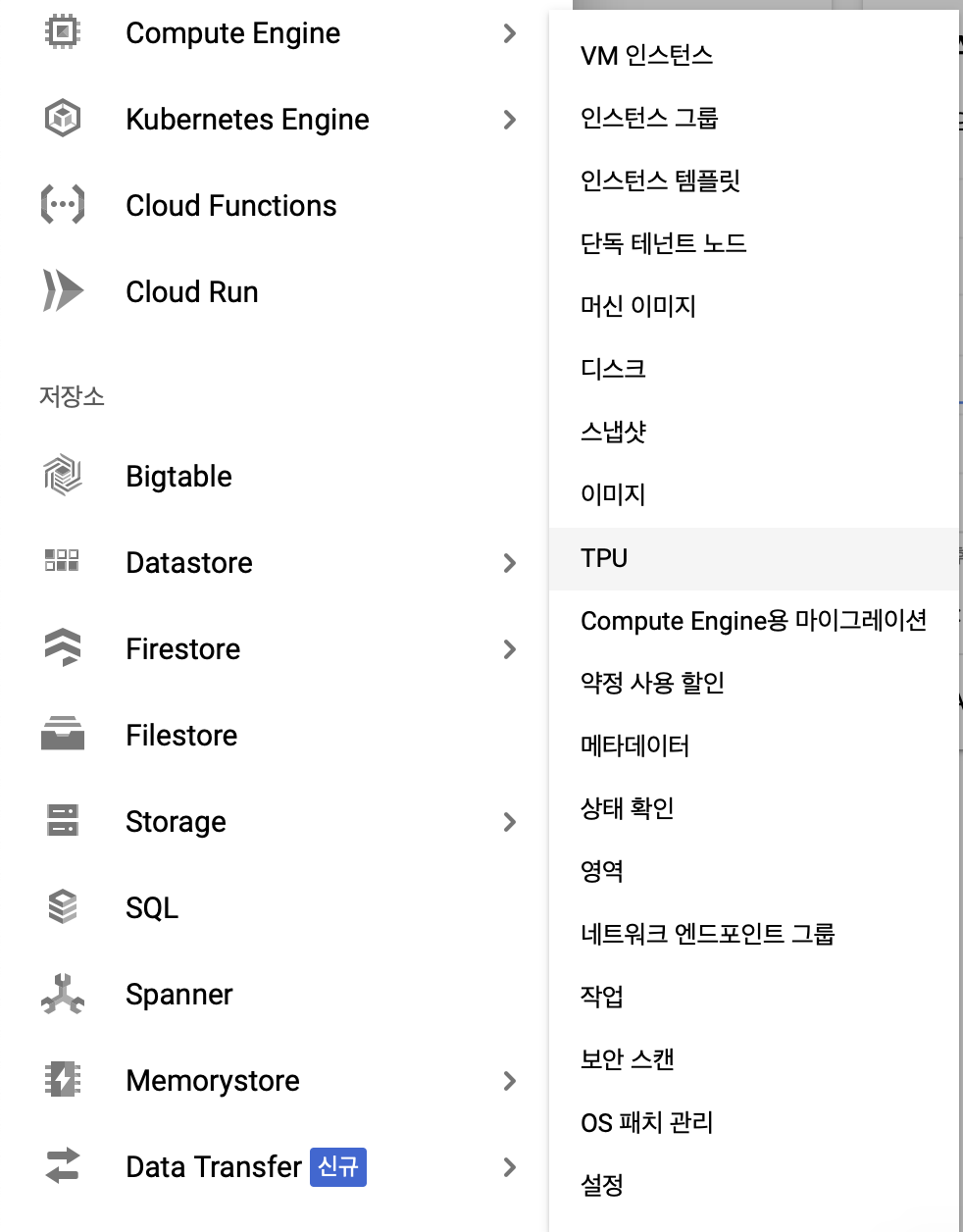
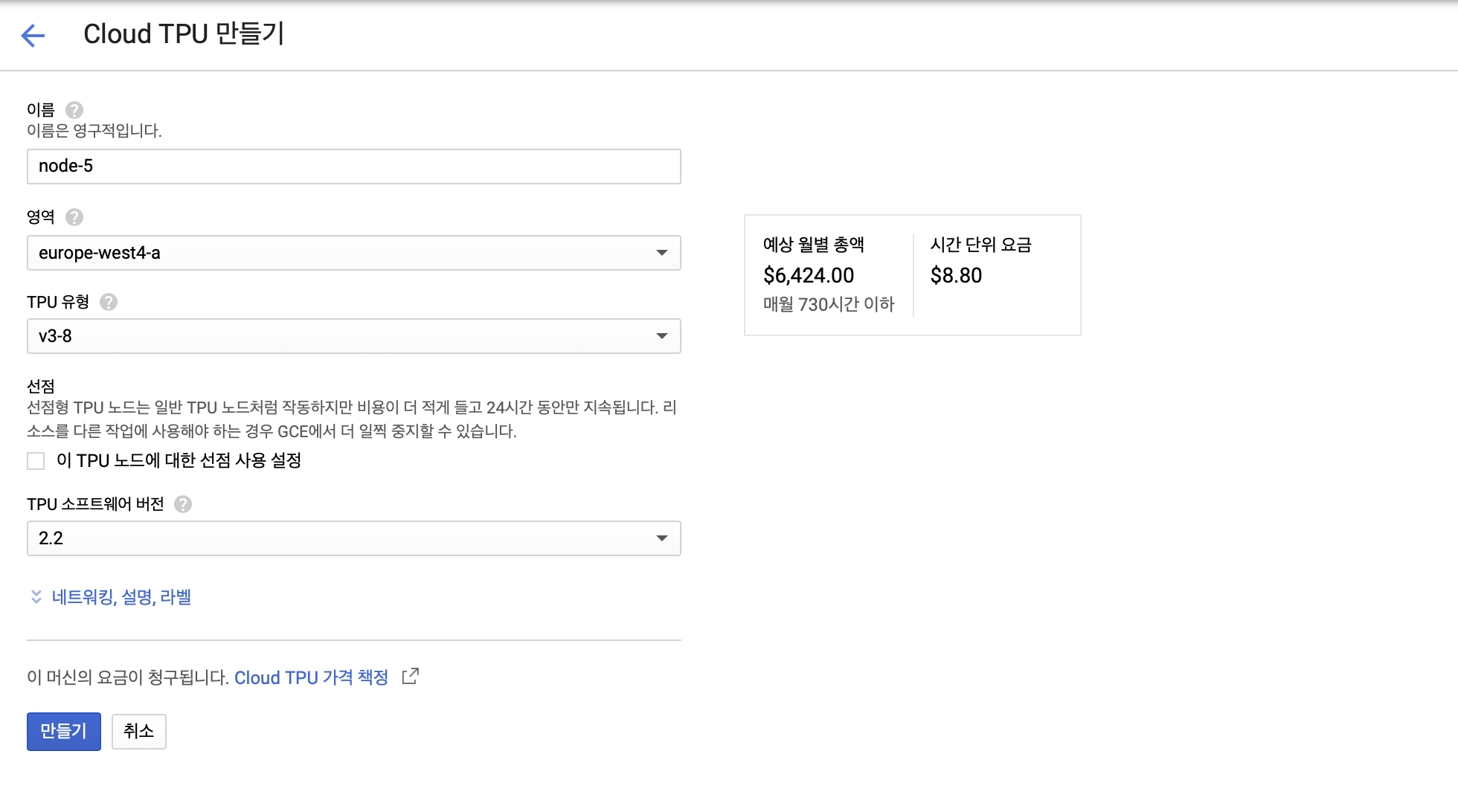
“TPU 노드 만들기” 버튼을 누르면 아래 그림과 같이 노드를 만들 수 있는 창이 열립니다.
- 이름: 노드의 이름입니다. 이후 과정에서 TPU 인식 및 할당에 이용됩니다.
- 영역: TPU가 위치하고 있는 지역입니다. (TPU 유형별로 다릅니다.)
- TPU 유형: 버전 및 코어 수에 따라 여러 유형의 TPU가 존재합니다.(v{버전이름}-{코어수}) 각 유형별 자세한 스펙은 이곳에서 볼 수 있습니다.
- TPU 소프트웨어 버전: Tensorflow 혹은 Torch의 버전을 설정합니다. 이후에 설명하겠지만, TF2.1과 2.2 버전에서
TPUStrategy에 변경사항이 있어서 코드가 호환되지 않습니다.
-
VM 및 Storage 설정
VM은 실제 코드가 위치하고, TPU/Storage와 통신합니다. 실제 연산들(TF2.x 기준
tf.function으로 감싸져서 트레이싱 된 부분들)은 모두 TPU에서 이루어집니다. 로컬 머신에서 CPU의 역할을 한다고 볼 수 있습니다.Storage는 학습 데이터가 위치해있고, 학습 결과 모델이 저장됩니다. GCP 공식 문서에서는 Storage를 사용하는 이유는 Storage를 이용시 Consistency를 보장할 수 있기 때문이라고 나와있습니다. 시도해보진 않았지만, 데이터의 경우 VM 로컬에 존재해도 학습자체는 가능할 것 같습니다.
메뉴에서 TPU 관리창에 들어갔던 것과 유사하게
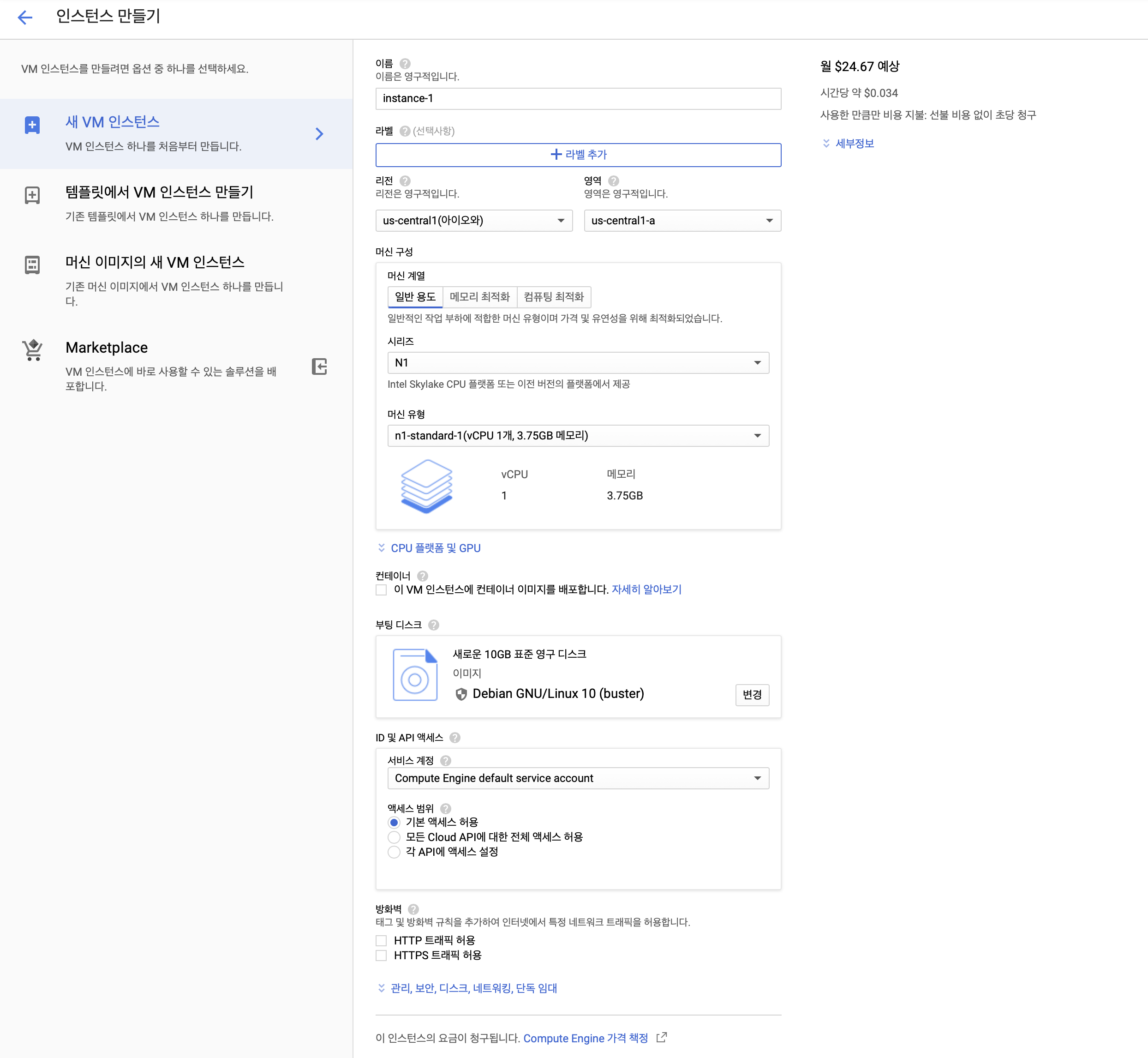
메뉴 버튼>Compute Engine>VM 인스턴스로 이동합니다. 인스턴스 만들기를 누르면 아래와 같이 여러 설정을 할 수 있는 창이 열립니다.- 이름: 인스턴스의 이름입니다.
- 리전: TPU가 위치하고 있는 지역과 동일한 지역으로 설정합니다.
- 머신구성: VM의 스펙입니다. 실제 연산은 TPU에서 이루어지므로, 가장 낮은 스펙(
N1, vCPU - 1개, 3.75G 메모리)으로 설정해도 됩니다. - 부팅 디스크: 학습환경에서 이용될 OS 및 버전을 설정합니다. 저는 Ubuntu 18.04 LTS/디스크 - 50GB를 이용했습니다.
- ID 및 API 엑세스는
모든 Cloud API에 대한 전체 엑세스 허용으로 설정했습니다. - HTTP/HTTPS 트래픽은 모두 허용상태로 체크했습니다.
보안탭에서 로컬의 ssh 퍼블릭키를 추가할 수 있는데, 이를 통해 로컬 머신에서 ssh 명령어로 접속가능합니다.
이번에는 Storage 설정을 위해
메뉴 버튼>Storage로 이동합니다. 버킷 생성을 누르면 다음과 같이 여러 설정을 할 수 있습니다.- 이름: bucket의 이름입니다.
- 데이터 저장 위치 선택: Region, TPU와 동일한 지역을 선택합니다.
- 엑세스 제어: 균일한 엑세스 제어를 선택합니다.
이렇게 버킷을 만들고 나면 이곳을 참고하여 TPU가 소유한 버킷에 접근할 수 있는 권한을 설정해줍니다.
여기 까지 진행하면 console상에서 수행해야 하는 모든 작업이 완료됩니다.
이번 포스트에서는 TPU를 이용하기 위해 GCP에서 해야하는 설정에 대해 알아보았습니다. 다음 포스트부터는 본격적으로 코드 레벨에서 TPU를 어떻게 이용하는지 알아보겠습니다.